




Commit
·
255c557
0
Parent(s):
Super-squash branch 'main' using huggingface_hub
Browse filesCo-authored-by: KennethEnevoldsen <[email protected]>
Co-authored-by: giannor <[email protected]>
Co-authored-by: saattrupdan <[email protected]>
This view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +42 -0
- README.md +119 -0
- config.json +29 -0
- create_dataset.py +90 -0
- generation_config.json +6 -0
- images/performance_plot_da.png +3 -0
- images/performance_plot_en.png +3 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +299 -0
- plots/create_plots.py +198 -0
- plots/danish-english-perf.png +3 -0
- plots/danish-perf.png +3 -0
- plots/dfm.png +0 -0
- plots/eleutherai.png +0 -0
- plots/english-perf.png +0 -0
- plots/pleias.png +0 -0
- special_tokens_map.json +30 -0
- stage1/config.json +29 -0
- stage1/generation_config.json +6 -0
- stage1/model-00001-of-00003.safetensors +3 -0
- stage1/model-00002-of-00003.safetensors +3 -0
- stage1/model-00003-of-00003.safetensors +3 -0
- stage1/model.safetensors.index.json +299 -0
- stage1/open-stage1.log +0 -0
- stage1/open-stage1.py +85 -0
- stage1/open-stage1.toml +42 -0
- stage1/special_tokens_map.json +30 -0
- stage1/tokenizer.json +0 -0
- stage1/tokenizer_config.json +46 -0
- stage2/config.json +29 -0
- stage2/generation_config.json +6 -0
- stage2/model-00001-of-00003.safetensors +3 -0
- stage2/model-00002-of-00003.safetensors +3 -0
- stage2/model-00003-of-00003.safetensors +3 -0
- stage2/model.safetensors.index.json +299 -0
- stage2/open-stage2.log +0 -0
- stage2/open-stage2.py +85 -0
- stage2/open-stage2.toml +44 -0
- stage2/special_tokens_map.json +30 -0
- stage2/tokenizer.json +0 -0
- stage2/tokenizer_config.json +46 -0
- stage3/config.json +29 -0
- stage3/generation_config.json +6 -0
- stage3/index.py +20 -0
- stage3/model-00001-of-00003.safetensors +3 -0
- stage3/model-00002-of-00003.safetensors +3 -0
- stage3/model-00003-of-00003.safetensors +3 -0
- stage3/model.safetensors.index.json +299 -0
.gitattributes
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/performance_plot_da.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/performance_plot_en.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
images/perf_euroeval_benchmark_results_da_latest.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
images/perf_euroeval_benchmark_results_en_latest.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
images/performance_plot_da.png.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
plots/danish-english-perf.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
plots/danish-perf.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- danish-foundation-models/danish-dynaword
|
| 5 |
+
- common-pile/comma_v0.1_training_dataset
|
| 6 |
+
language:
|
| 7 |
+
- da
|
| 8 |
+
- en
|
| 9 |
+
base_model:
|
| 10 |
+
- common-pile/comma-v0.1-2t
|
| 11 |
+
pipeline_tag: text-generation
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# DFM-Decoder-open-v0-7b-pt
|
| 15 |
+
|
| 16 |
+
DFM-Decoder-open-v0-7b-pt is a 7-billion-parameter [open-source](https://opensource.org/ai/open-source-ai-definition) language model.
|
| 17 |
+
DFM-Decoder-open-v0-7b-pt is a base model that can serve as a starting point for fine-tuning and post-training.
|
| 18 |
+
It has not been instruction-tuned and cannot directly be expected to function as a chat model.
|
| 19 |
+
|
| 20 |
+
| Model | Model Weights | Training Data | Training Code |
|
| 21 |
+
|:------|:--------------|:--------------|:--------------|
|
| 22 |
+
| Llama | Public with custom license | Private | Private |
|
| 23 |
+
| Gemma | Public, openly licensed | Private | Private |
|
| 24 |
+
| Apertus | Public, openly licensed | Reproducible, license unspecified | Public, openly licensed |
|
| 25 |
+
| **DFM-Decoder-open-v0-7b-pt** (ours) | **Public, openly licensed** | **Public, openly licensed** | **Public, openly licensed** |
|
| 26 |
+
|
| 27 |
+
## Evaluation
|
| 28 |
+
|
| 29 |
+
### Performance on Danish
|
| 30 |
+
|
| 31 |
+
The following plots show the model size on the x-axis and an aggregate performance score for Danish on the y-axis. Each metric is normalized across all evaluated models using min-max normalization to the range [0, 1], and the final score represents the average of all normalized metrics.
|
| 32 |
+
|
| 33 |
+
<p align="center">
|
| 34 |
+
<img src="./plots/danish-perf.png" width="700"/>
|
| 35 |
+
</p>
|
| 36 |
+
|
| 37 |
+
DFM-Decoder-open-v0-7b-pt was evaluated using the [EuroEval](https://euroeval.com/) framework, which includes benchmarks across seven task types covering more than 15 European languages.
|
| 38 |
+
|
| 39 |
+
Below we report results for Danish (see English below) for all EuroEval-supported tasks: sentiment classification, named entity recognition, linguistic acceptability, reading comprehension, summarization, and knowledge and common-sense reasoning. In addition, we evaluate the model on DaLA, a Danish linguistic acceptability dataset focusing on real-world common errors.
|
| 40 |
+
|
| 41 |
+
We compare DFM-Decoder-open-v0-7b-pt at various training stages with its base model [Comma v0.1-2T](https://huggingface.co/common-pile/comma-v0.1-2t)
|
| 42 |
+
and two models from the Pleias family ([Pleias-350M-Preview](https://huggingface.co/PleIAs/Pleias-350m-Preview) and [Pleias-1.2B-Preview](https://huggingface.co/PleIAs/Pleias-1.2b-Preview)).
|
| 43 |
+
All comparison models were trained exclusively on open data, either in the public domain or under a permissive license.
|
| 44 |
+
|
| 45 |
+
The following tables show the performance on each dataset.
|
| 46 |
+
For each, we report the respective main metric from EuroEval and the confidence interval.
|
| 47 |
+
|
| 48 |
+
| Model | scala-da (MCC)| dala (MCC) | angry-tweets (MCC) | dansk (Micro F1, No Misc) | danske-talemaader (MCC) | danish-citizen-tests (MCC) | multi-wiki-qa-da (F1) | hellaswag-da (MCC) | nordjylland-news (BERTScore) | average |
|
| 49 |
+
| ----------------------------------- | ------------- | ------------- | ------------------ | ------------------------- | ----------------------- | -------------------------- | --------------------- | ------------------ | ---------------------------- | ------- |
|
| 50 |
+
| base (comma-v0.1-2t) | 0.9 ± 0.8 | 0.2 ± 0.6 | 39.8 ± 1.4 | 32.0 ± 2.8 | 3.6 ± 2.3 | 10.7 ± 4.1 | 66.4 ± 0.8 | 3.8 ± 1.0 | 60.2 ± 1.7 | 24.2 |
|
| 51 |
+
| **Training Stages** | | | | | | | | | | |
|
| 52 |
+
| stage 1 | 13.3 ± 2.9 | 12.7 ± 2.2 | **47.7** ± 1.7 | 40.0 ± 2.4 | 18.1 ± 0.9 | 32.8 ± 1.4 | **76.6** ± 0.6 | 12.9 ± 1.0 | 66.3 ± 0.7 | 35.6 |
|
| 53 |
+
| stage 2 | 15.8 ± 3.1 | 14.4 ± 2.9 | 47.4 ± 2.3 | 40.4 ± 2.4 | 24.1 ± 1.8 | 36.1 ± 1.8 | 75.2 ± 0.7 | 13.1 ± 1.1 | 66.5 ± 0.6 | 37.0 |
|
| 54 |
+
| dfm-decoder-open-v0-7b-pt (stage 3) | **16.5** ± 1.4| **15.7** ± 1.7| 46.3 ± 2.1 | **41.1** ± 2.8 | **24.6** ± 2.0 | **36.2** ± 1.7 | 76.0 ± 0.7 | **13.2** ± 1.2 | **66.6** ± 0.6 | **37.4** |
|
| 55 |
+
| **Baselines** | | | | | | | | | | |
|
| 56 |
+
| Pleias-350m-Preview | -1.0 ± 1.5 | -1.8 ± 1.8 | 10.6 ± 2.9 | 12.9 ± 1.8 | 0.7 ± 2.6 | 4.6 ± 2.3 | 11.6 ± 0.9 | -0.3 ± 0.7 | 56.3 ± 1.5 | 10.4 |
|
| 57 |
+
| Pleias-1.2b-Preview | 0.2 ± 1.1 | 0.7 ± 1.0 | 27.7 ± 2.9 | 27.3 ± 2.2 | -0.6 ± 1.9 | 8.6 ± 3.2 | 35.2 ± 1.3 | -0.0 ± 1.5 | 60.3 ± 0.9 | 17.7 |
|
| 58 |
+
|
| 59 |
+
### Performance on English
|
| 60 |
+
|
| 61 |
+
<div align="center">
|
| 62 |
+
<table>
|
| 63 |
+
<tr>
|
| 64 |
+
<td><img src="./plots/danish-english-perf.png" width="600"/></td>
|
| 65 |
+
<td><img src="./plots/english-perf.png" width="600"/></td>
|
| 66 |
+
</tr>
|
| 67 |
+
</table>
|
| 68 |
+
</div>
|
| 69 |
+
|
| 70 |
+
The goal of this section is to demonstrate how performance is maintained deteriorates for English when adapting the model for Danish. Generally, we see only minor performance degradation
|
| 71 |
+
across tasks.
|
| 72 |
+
|
| 73 |
+
| Model | scala-en (MCC) | sst5 (MCC) | conll-en (Micro F1 no misc) | life-in-the-uk (MCC) | squad (F1) | hellaswag (MCC) | cnn-dailymail (BERTScore) | average |
|
| 74 |
+
| ------------------------------------ | ------------- | ------------ | --------------------------- | -------------------- | ------------ | --------------- | ------------------------- | ------- |
|
| 75 |
+
| base (comma-v0.1-2t) | **29.7** ± 1.9 | **61.8** ± 2.1| **57.5** ± 2.8 | 41.6 ± 2.4 | **90.4** ± 0.4| **16.8** ± 0.6 | **63.3** ± 0.9 | **51.6** |
|
| 76 |
+
| **Training Stages** | | | | | | | | |
|
| 77 |
+
| stage 1 | 17.1 ± 9.0 | 60.0 ± 1.7 | 56.6 ± 2.2 | 40.5 ± 1.7 | 90.1 ± 0.3 | 13.7 ± 0.7 | 59.6 ± 1.3 | 48.2 |
|
| 78 |
+
| stage 2 | 27.7 ± 2.0 | 59.5 ± 1.6 | 56.6 ± 2.3 | 41.2 ± 1.7 | 90.2 ± 0.4 | 16.0 ± 0.9 | 60.3 ± 1.6 | 50.2 |
|
| 79 |
+
| dfm-decoder-open-v0-7b-pt (stage 3) | 29.0 ± 2.4 | 60.3 ± 1.4 | 56.9 ± 2.5 | **41.7** ± 1.8 | 89.9 ± 0.4 | 13.8 ± 0.9 | 59.2 ± 1.7 | 50.1 |
|
| 80 |
+
| **Baseline** | | | | | | | | |
|
| 81 |
+
| Pleias-350m-Preview | 0.7 ± 1.8 | 15.4 ± 7.3 | 31.8 ± 3.5 | -0.7 ± 2.1 | 31.1 ± 2.3 | 0.2 ± 1.4 | 53.8 ± 1.0 | 18.9 |
|
| 82 |
+
| Pleias-1.2b-Preview | 1.0 ± 2.4 | 48.2 ± 2.6 | 40.9 ± 3.3 | 2.6 ± 2.8 | 52.9 ± 2.5 | -0.1 ± 1.5 | 60.2 ± 1.6 | 29.4 |
|
| 83 |
+
|
| 84 |
+
## Training details
|
| 85 |
+
|
| 86 |
+
DFM-Decoder-open-v0-7b-pt is continually pre-trained from [Comma v0.1-2T](https://huggingface.co/common-pile/comma-v0.1-2t) using 30B tokens, utilizing a mix of [Danish Dynaword](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword) and the [Comma v0.1 dataset](https://huggingface.co/datasets/common-pile/comma_v0.1_training_dataset), both comprising only public domain and openly licensed data.
|
| 87 |
+
|
| 88 |
+
DFM-Decoder-open-v0-7b-pt has been trained using the [maester](https://github.com/rlrs/maester) framework developed as part of [Danish Foundation Models](https://foundationmodels.dk/). All training was performed on a single 8x NVIDIA B200 node (the first of its kind in Denmark) as part of the [SDU UCloud](https://cloud.sdu.dk/) research cloud.
|
| 89 |
+
|
| 90 |
+
The training was performed in three stages, with data mix (open-stageK.py) and maester (open-stageK.toml) configuration files available in each subfolder. The datasets can be created using the `create_dataset.py` script provided in this repository.
|
| 91 |
+
|
| 92 |
+
The characteristics of the three pre-training stages are detailed in the following table:
|
| 93 |
+
|
| 94 |
+
| Stage | Batch size (tokens) | Steps | HF path | Data mix | Comments |
|
| 95 |
+
|-|-|-|-|-|-|
|
| 96 |
+
| stage 1 | 262,144 | 37,852| [subfolder="stage1"](https://huggingface.co/danish-foundation-models/munin-7b-open-pt/tree/main/stage1) | 2/3 [Dynaword](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/tree/9e230b35e31a510e5ab909112ad5bfc9463b2c23); <br> 1/3 [Common-Pile](https://huggingface.co/common-pile/comma_v0.1_training_dataset/5afc546db324e7f39f297ba757c9a60547151e7c) | Excludes depbank, jvj, nordjyllandnews, synne for Dynaword; <br> uses subsets and weighting from [Comma-v0.1-2T](https://huggingface.co/common-pile/comma-v0.1-2t) cooldown phase for Common-Pile ; LR schedule with 1000 steps warmup, constant 1e-5, 1000 steps cooldown |
|
| 97 |
+
| stage 2 | 524,288 | 18,926 | [subfolder="stage2"](https://huggingface.co/danish-foundation-models/munin-7b-open-pt/tree/main/stage2) | 2/3 [Dynaword](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/tree/9e230b35e31a510e5ab909112ad5bfc9463b2c23); <br> 1/3 [Common-Pile](https://huggingface.co/common-pile/comma_v0.1_training_dataset/5afc546db324e7f39f297ba757c9a60547151e7c) | Excludes depbank, jvj, nordjyllandnews, synne for Dynaword; <br> uses subsets and weighting from [Comma-v0.1-2T](https://huggingface.co/common-pile/comma-v0.1-2t) cooldown phase for Common-Pile; LR schedule with 500 steps warmup, constant 1e-5, 500 steps cooldown |
|
| 98 |
+
| stage 3 | 524,288 | 18,926 | [subfolder="stage3"](https://huggingface.co/danish-foundation-models/munin-7b-open-pt/tree/main/stage3) | 2/3 [Dynaword](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/tree/9e230b35e31a510e5ab909112ad5bfc9463b2c23); <br> 1/3 [Common-Pile](https://huggingface.co/common-pile/comma_v0.1_training_dataset/5afc546db324e7f39f297ba757c9a60547151e7c) | Excludes depbank, jvj, nordjyllandnews, synne for Dynaword; <br> uses subsets and weighting from [Comma-v0.1-2T](https://huggingface.co/common-pile/comma-v0.1-2t) cooldown phase for Common-Pile; LR schedule with 500 steps warmup, square root decay from 1e-5 |
|
| 99 |
+
|
| 100 |
+
## Limitations
|
| 101 |
+
|
| 102 |
+
DFM-Decoder-open-v0-7b-pt was trained only on Danish and English-language data and code from the 15 programming languages covered by the [stack-edu classifiers](https://huggingface.co/collections/HuggingFaceTB/the-ultimate-collection-of-code-classifiers-67b5aa3eb8994a4b71453005).
|
| 103 |
+
It will likely have poor performance on other languages or programming languages.
|
| 104 |
+
|
| 105 |
+
As a base model, DFM-Decoder-open-v0-7b-pt has not been aligned for safety and may, for example, reflect social biases present in its training data or potentially provide toxic or harmful information.
|
| 106 |
+
|
| 107 |
+
## License
|
| 108 |
+
|
| 109 |
+
The model is made available under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0) open source license. It may therefore be used, modified, distributed, and sublicensed for any purpose, including commercial use, without the licensee having to release their own derivative works under the same permissive terms, provided that users retain copyright and license notices and document any modifications they make.
|
| 110 |
+
|
| 111 |
+
## Project partners & funding
|
| 112 |
+
|
| 113 |
+
The development of DFM-Decoder-open-v0-7b-pt was performed in a close collaboration between [Aarhus University](https://chc.au.dk/), the [Alexandra Institute](https://alexandra.dk/), and the [University of Southern Denmark](https://www.sdu.dk/en/forskning/machine-learning) as part of [Danish Foundation Models](https://foundationmodels.dk/).
|
| 114 |
+
|
| 115 |
+
Funding was provided by the [Danish Ministry of Digital Affairs](https://www.english.digmin.dk/) and the [Danish Ministry of Higher Education and Science](https://ufm.dk/en).
|
| 116 |
+
|
| 117 |
+
## How to cite
|
| 118 |
+
|
| 119 |
+
Coming soon.
|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 2,
|
| 8 |
+
"dtype": "bfloat16",
|
| 9 |
+
"eos_token_id": 3,
|
| 10 |
+
"head_dim": 128,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 4096,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 11008,
|
| 15 |
+
"max_position_embeddings": 16384,
|
| 16 |
+
"mlp_bias": false,
|
| 17 |
+
"model_type": "llama",
|
| 18 |
+
"num_attention_heads": 32,
|
| 19 |
+
"num_hidden_layers": 32,
|
| 20 |
+
"num_key_value_heads": 32,
|
| 21 |
+
"pretraining_tp": 1,
|
| 22 |
+
"rms_norm_eps": 1e-05,
|
| 23 |
+
"rope_scaling": null,
|
| 24 |
+
"rope_theta": 100000.0,
|
| 25 |
+
"tie_word_embeddings": false,
|
| 26 |
+
"transformers_version": "4.57.3",
|
| 27 |
+
"use_cache": true,
|
| 28 |
+
"vocab_size": 64256
|
| 29 |
+
}
|
create_dataset.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import datasets
|
| 3 |
+
import importlib
|
| 4 |
+
import tqdm
|
| 5 |
+
import transformers
|
| 6 |
+
import typer
|
| 7 |
+
|
| 8 |
+
def load_config(config_file: str):
|
| 9 |
+
spec = importlib.util.spec_from_file_location("config", config_file)
|
| 10 |
+
config_module = importlib.util.module_from_spec(spec)
|
| 11 |
+
spec.loader.exec_module(config_module)
|
| 12 |
+
return config_module.sources, config_module.tokenizer_name, config_module.prefix
|
| 13 |
+
|
| 14 |
+
def tokenize(batch: dict):
|
| 15 |
+
if tokenizer:
|
| 16 |
+
return {"num_tokens": tokenizer(batch["text"], padding="do_not_pad", return_length=True)["length"]}
|
| 17 |
+
return {"num_tokens": 0}
|
| 18 |
+
|
| 19 |
+
def shard_indices(shard_index):
|
| 20 |
+
if not isinstance(shard_index, list):
|
| 21 |
+
shard_index = [shard_index]
|
| 22 |
+
return shard_index
|
| 23 |
+
|
| 24 |
+
def preprocess_shard(ds: datasets.Dataset, num_shards: int, index: int, num_proc: int):
|
| 25 |
+
shard = ds.shard(num_shards=num_shards, index=index, contiguous=True)
|
| 26 |
+
shard = shard.flatten_indices()
|
| 27 |
+
shard = shard.map(tokenize, batched=True, batch_size=1000, num_proc=num_proc)
|
| 28 |
+
return shard
|
| 29 |
+
|
| 30 |
+
def preprocess_subset(weights: dict, subsets: list, source: str, src_info: dict, dc: datasets.DownloadConfig, num_proc: int):
|
| 31 |
+
for key, frac in tqdm.tqdm(weights.items(), desc="Loading train subsets"):
|
| 32 |
+
uri_template = src_info["uri"]
|
| 33 |
+
print(f" Loading subset: {key} with fraction 1/{frac} from {uri_template.format(key=key)}")
|
| 34 |
+
ds = datasets.load_dataset(
|
| 35 |
+
src_info["format"],
|
| 36 |
+
data_files=uri_template.format(key=key),
|
| 37 |
+
split="train",
|
| 38 |
+
download_config=dc,
|
| 39 |
+
)
|
| 40 |
+
ds = ds.select_columns(["text"])
|
| 41 |
+
ds = ds.add_column("source", [source] * len(ds))
|
| 42 |
+
ds = ds.add_column("subset", [key] * len(ds))
|
| 43 |
+
ds = ds.shuffle(seed=42)
|
| 44 |
+
dss = [preprocess_shard(ds, int(src_info["shards"]/frac), i, num_proc) for i in shard_indices(src_info["shard_index"])]
|
| 45 |
+
ds = datasets.concatenate_datasets(dss)
|
| 46 |
+
ds = ds.cast_column("text", datasets.Value("large_string"))
|
| 47 |
+
print(f" Finished preprocessing subset: {key} with {sum(ds['num_tokens'])} tokens")
|
| 48 |
+
subsets.append(ds)
|
| 49 |
+
|
| 50 |
+
def main(
|
| 51 |
+
config_file: str,
|
| 52 |
+
num_proc: int = 96,
|
| 53 |
+
max_retries: int = 10,
|
| 54 |
+
):
|
| 55 |
+
sources, tokenizer_name, prefix = load_config(config_file)
|
| 56 |
+
global tokenizer
|
| 57 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained(tokenizer_name) if tokenizer_name else None
|
| 58 |
+
dc = datasets.DownloadConfig(num_proc=num_proc, max_retries=max_retries)
|
| 59 |
+
train_subsets = []
|
| 60 |
+
test_subsets = []
|
| 61 |
+
file_name = f"{prefix}-"
|
| 62 |
+
for source, src_info in sources.items():
|
| 63 |
+
print(f"Processing source: {source}")
|
| 64 |
+
shard_index = src_info["shard_index"]
|
| 65 |
+
if not isinstance(shard_index, list):
|
| 66 |
+
shard_index = [shard_index]
|
| 67 |
+
file_name += f"{source}-{'_'.join(str(s) for s in shard_index)}-of-{src_info['shards']}-"
|
| 68 |
+
preprocess_subset(src_info["train"], train_subsets, source, src_info, dc, num_proc)
|
| 69 |
+
preprocess_subset(src_info["test"], test_subsets, source, src_info, dc, num_proc)
|
| 70 |
+
print("Concatenating train subsets")
|
| 71 |
+
final_train = datasets.concatenate_datasets(train_subsets)
|
| 72 |
+
print("Shuffling final train dataset")
|
| 73 |
+
final_train = final_train.shuffle(seed=42)
|
| 74 |
+
print("Flattening final train dataset")
|
| 75 |
+
final_train = final_train.flatten_indices()
|
| 76 |
+
print("Concatenating test subsets")
|
| 77 |
+
final_test = datasets.concatenate_datasets(test_subsets)
|
| 78 |
+
print("Shuffling final test dataset")
|
| 79 |
+
final_test = final_test.shuffle(seed=42)
|
| 80 |
+
print("Flattening final test dataset")
|
| 81 |
+
final_test = final_test.flatten_indices()
|
| 82 |
+
test_file = f"{file_name}test/{file_name}test.parquet"
|
| 83 |
+
print(f"Writing final test dataset with {sum(final_test['num_tokens'])} tokens to {test_file}")
|
| 84 |
+
final_test.to_parquet(test_file)
|
| 85 |
+
train_file = f"{file_name}train/{file_name}train.parquet"
|
| 86 |
+
print(f"Writing final train dataset with {sum(final_train['num_tokens'])} tokens to {train_file}")
|
| 87 |
+
final_train.to_parquet(train_file)
|
| 88 |
+
|
| 89 |
+
if __name__ == "__main__":
|
| 90 |
+
typer.run(main)
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 2,
|
| 4 |
+
"eos_token_id": 3,
|
| 5 |
+
"transformers_version": "4.57.3"
|
| 6 |
+
}
|
images/performance_plot_da.png
ADDED

|
Git LFS Details
|
images/performance_plot_en.png
ADDED

|
Git LFS Details
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d56eb49f03ee932518e3e7c55f6c46a15177dce57662ad91417c65ba4cd794f8
|
| 3 |
+
size 4978830664
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6df9d3b3790135776e05993005383d8066bb2560e15b39bbb29b3c43ea0ee795
|
| 3 |
+
size 4991431432
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0cb865281fd75e9ac348d05160e4f3468a7d934c103d63ceb9b95887e1a8005
|
| 3 |
+
size 4035085288
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_parameters": 7002656768,
|
| 4 |
+
"total_size": 14005313536
|
| 5 |
+
},
|
| 6 |
+
"weight_map": {
|
| 7 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 8 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 297 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 298 |
+
}
|
| 299 |
+
}
|
plots/create_plots.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import matplotlib.pyplot as plt
|
| 2 |
+
import numpy as np
|
| 3 |
+
from matplotlib.offsetbox import AnnotationBbox, OffsetImage
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
#### --- Plot data and logos --- ####
|
| 7 |
+
|
| 8 |
+
data_danish = {
|
| 9 |
+
"comma-v0.1-2t": {"parameters (billions)": 7.0, "Danish Performance": 24.2},
|
| 10 |
+
"Stage 1": {"parameters (billions)": 7.0, "Danish Performance": 35.6},
|
| 11 |
+
"Stage 2": {"parameters (billions)": 7.0, "Danish Performance": 37.0},
|
| 12 |
+
# stage 3:
|
| 13 |
+
"dfm-decoder-open-v0-7b-pt": {
|
| 14 |
+
"parameters (billions)": 7.0,
|
| 15 |
+
"Danish Performance": 37.4,
|
| 16 |
+
},
|
| 17 |
+
"Pleias-350M": {"parameters (billions)": 0.35, "Danish Performance": 10.4},
|
| 18 |
+
"Pleias-1.2B": {"parameters (billions)": 1.2, "Danish Performance": 17.7},
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
data_english = {
|
| 22 |
+
"comma-v0.1-2t": {"parameters (billions)": 7.0, "English Performance": 51.6},
|
| 23 |
+
"Stage 1": {"parameters (billions)": 7.0, "English Performance": 48.2},
|
| 24 |
+
"Stage 2": {"parameters (billions)": 7.0, "English Performance": 50.2},
|
| 25 |
+
# stage 3:
|
| 26 |
+
"dfm-decoder-open-v0-7b-pt": {
|
| 27 |
+
"parameters (billions)": 7.0,
|
| 28 |
+
"English Performance": 50.1,
|
| 29 |
+
},
|
| 30 |
+
"Pleias-350M": {"parameters (billions)": 0.35, "English Performance": 18.9},
|
| 31 |
+
"Pleias-1.2B": {"parameters (billions)": 1.2, "English Performance": 29.4},
|
| 32 |
+
}
|
| 33 |
+
|
| 34 |
+
data = {}
|
| 35 |
+
for model in data_danish.keys():
|
| 36 |
+
data[model] = {
|
| 37 |
+
"parameters (billions)": data_danish[model]["parameters (billions)"],
|
| 38 |
+
"Danish Performance": data_danish[model]["Danish Performance"],
|
| 39 |
+
"English Performance": data_english[model]["English Performance"],
|
| 40 |
+
"Danish x English Performance": (
|
| 41 |
+
data_danish[model]["Danish Performance"]
|
| 42 |
+
+ data_english[model]["English Performance"]
|
| 43 |
+
)
|
| 44 |
+
/ 2,
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# Map models to logo files and sizes
|
| 49 |
+
logos = {
|
| 50 |
+
"comma-v0.1-2t": {"path": "eleutherai.png", "zoom": 0.035},
|
| 51 |
+
"dfm-decoder-open-v0-7b-pt": {"path": "dfm.png", "zoom": 0.018},
|
| 52 |
+
"Pleias-350M": {"path": "pleias.png", "zoom": 0.30},
|
| 53 |
+
"Pleias-1.2B": {"path": "pleias.png", "zoom": 0.30},
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
#### --- Create plot of Danish performance --- ####
|
| 58 |
+
|
| 59 |
+
model_names = list(data.keys())
|
| 60 |
+
sizes = [data[m]["parameters (billions)"] for m in model_names]
|
| 61 |
+
performance = [data[m]["Danish Performance"] for m in model_names]
|
| 62 |
+
|
| 63 |
+
# Create plot
|
| 64 |
+
plt.figure(figsize=(7, 7))
|
| 65 |
+
|
| 66 |
+
# Draw Pareto frontier
|
| 67 |
+
x_curve = np.linspace(0.0, 8, 100)
|
| 68 |
+
y_curve = 19 + 3.9 * np.log(x_curve)
|
| 69 |
+
plt.plot(x_curve, y_curve, "--", color="grey", linewidth=0.7, alpha=0.7)
|
| 70 |
+
plt.text(
|
| 71 |
+
2,
|
| 72 |
+
20,
|
| 73 |
+
"Previous Pareto frontier for openly licensed data",
|
| 74 |
+
fontsize=8,
|
| 75 |
+
color="grey",
|
| 76 |
+
style="italic",
|
| 77 |
+
rotation=7.5,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
# Get axis reference
|
| 82 |
+
ax = plt.gca()
|
| 83 |
+
|
| 84 |
+
# Add logos for specific models
|
| 85 |
+
for i, name in enumerate(model_names):
|
| 86 |
+
if name in logos:
|
| 87 |
+
img = Image.open(logos[name]["path"])
|
| 88 |
+
imagebox = OffsetImage(img, zoom=logos[name]["zoom"])
|
| 89 |
+
ab = AnnotationBbox(imagebox, (sizes[i], performance[i]), frameon=False, pad=0)
|
| 90 |
+
ax.add_artist(ab)
|
| 91 |
+
|
| 92 |
+
# Add label below/beside logo
|
| 93 |
+
plt.annotate(
|
| 94 |
+
name,
|
| 95 |
+
(sizes[i], performance[i]),
|
| 96 |
+
xytext=(5, -15),
|
| 97 |
+
textcoords="offset points",
|
| 98 |
+
fontsize=9,
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
plt.xlabel("Parameters (billions)", fontsize=12)
|
| 102 |
+
plt.ylabel("Danish Performance", fontsize=12)
|
| 103 |
+
|
| 104 |
+
# Remove top and right spines
|
| 105 |
+
ax.spines["top"].set_visible(False)
|
| 106 |
+
ax.spines["right"].set_visible(False)
|
| 107 |
+
plt.tight_layout()
|
| 108 |
+
plt.xlim(0, 10)
|
| 109 |
+
plt.ylim(0, 40)
|
| 110 |
+
plt.savefig("danish-perf.png", dpi=300)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
#### --- Create plot of Danish x English performance --- ####
|
| 114 |
+
|
| 115 |
+
model_names = list(data.keys())
|
| 116 |
+
sizes = [data[m]["parameters (billions)"] for m in model_names]
|
| 117 |
+
performance = [data[m]["Danish x English Performance"] for m in model_names]
|
| 118 |
+
|
| 119 |
+
# Create plot
|
| 120 |
+
plt.figure(figsize=(7, 7))
|
| 121 |
+
|
| 122 |
+
# Draw Pareto frontier
|
| 123 |
+
x_curve = np.linspace(0.2, 8, 100)
|
| 124 |
+
y_curve = 26 + 7 * np.log(x_curve)
|
| 125 |
+
plt.plot(x_curve, y_curve, "--", color="grey", linewidth=0.7, alpha=0.7)
|
| 126 |
+
|
| 127 |
+
# Get axis reference
|
| 128 |
+
ax = plt.gca()
|
| 129 |
+
|
| 130 |
+
# Add logos for specific models
|
| 131 |
+
for i, name in enumerate(model_names):
|
| 132 |
+
if name in logos:
|
| 133 |
+
img = Image.open(logos[name]["path"])
|
| 134 |
+
imagebox = OffsetImage(img, zoom=logos[name]["zoom"])
|
| 135 |
+
ab = AnnotationBbox(imagebox, (sizes[i], performance[i]), frameon=False, pad=0)
|
| 136 |
+
ax.add_artist(ab)
|
| 137 |
+
|
| 138 |
+
# Add label below/beside logo
|
| 139 |
+
plt.annotate(
|
| 140 |
+
name,
|
| 141 |
+
(sizes[i], performance[i]),
|
| 142 |
+
xytext=(5, -15),
|
| 143 |
+
textcoords="offset points",
|
| 144 |
+
fontsize=9,
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
plt.xlabel("Parameters (billions)", fontsize=12)
|
| 148 |
+
plt.ylabel("Danish x English Performance", fontsize=12)
|
| 149 |
+
|
| 150 |
+
# Remove top and right spines
|
| 151 |
+
ax.spines["top"].set_visible(False)
|
| 152 |
+
ax.spines["right"].set_visible(False)
|
| 153 |
+
plt.tight_layout()
|
| 154 |
+
plt.xlim(0, 10)
|
| 155 |
+
plt.ylim(0, 45)
|
| 156 |
+
plt.savefig("danish-english-perf.png", dpi=300)
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
#### --- Create plot of English performance --- ####
|
| 160 |
+
|
| 161 |
+
model_names = list(data.keys())
|
| 162 |
+
sizes = [data[m]["parameters (billions)"] for m in model_names]
|
| 163 |
+
performance = [data[m]["English Performance"] for m in model_names]
|
| 164 |
+
|
| 165 |
+
# Create plot
|
| 166 |
+
plt.figure(figsize=(7, 7))
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
# Get axis reference
|
| 170 |
+
ax = plt.gca()
|
| 171 |
+
|
| 172 |
+
# Add logos for specific models
|
| 173 |
+
for i, name in enumerate(model_names):
|
| 174 |
+
if name in logos:
|
| 175 |
+
img = Image.open(logos[name]["path"])
|
| 176 |
+
imagebox = OffsetImage(img, zoom=logos[name]["zoom"])
|
| 177 |
+
ab = AnnotationBbox(imagebox, (sizes[i], performance[i]), frameon=False, pad=0)
|
| 178 |
+
ax.add_artist(ab)
|
| 179 |
+
|
| 180 |
+
# Add label below/beside logo
|
| 181 |
+
plt.annotate(
|
| 182 |
+
name,
|
| 183 |
+
(sizes[i], performance[i]),
|
| 184 |
+
xytext=(5, -15),
|
| 185 |
+
textcoords="offset points",
|
| 186 |
+
fontsize=9,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
plt.xlabel("Parameters (billions)", fontsize=12)
|
| 190 |
+
plt.ylabel("English Performance", fontsize=12)
|
| 191 |
+
|
| 192 |
+
# Remove top and right spines
|
| 193 |
+
ax.spines["top"].set_visible(False)
|
| 194 |
+
ax.spines["right"].set_visible(False)
|
| 195 |
+
plt.tight_layout()
|
| 196 |
+
plt.xlim(0, 10)
|
| 197 |
+
plt.ylim(0, 55)
|
| 198 |
+
plt.savefig("english-perf.png", dpi=300)
|
plots/danish-english-perf.png
ADDED
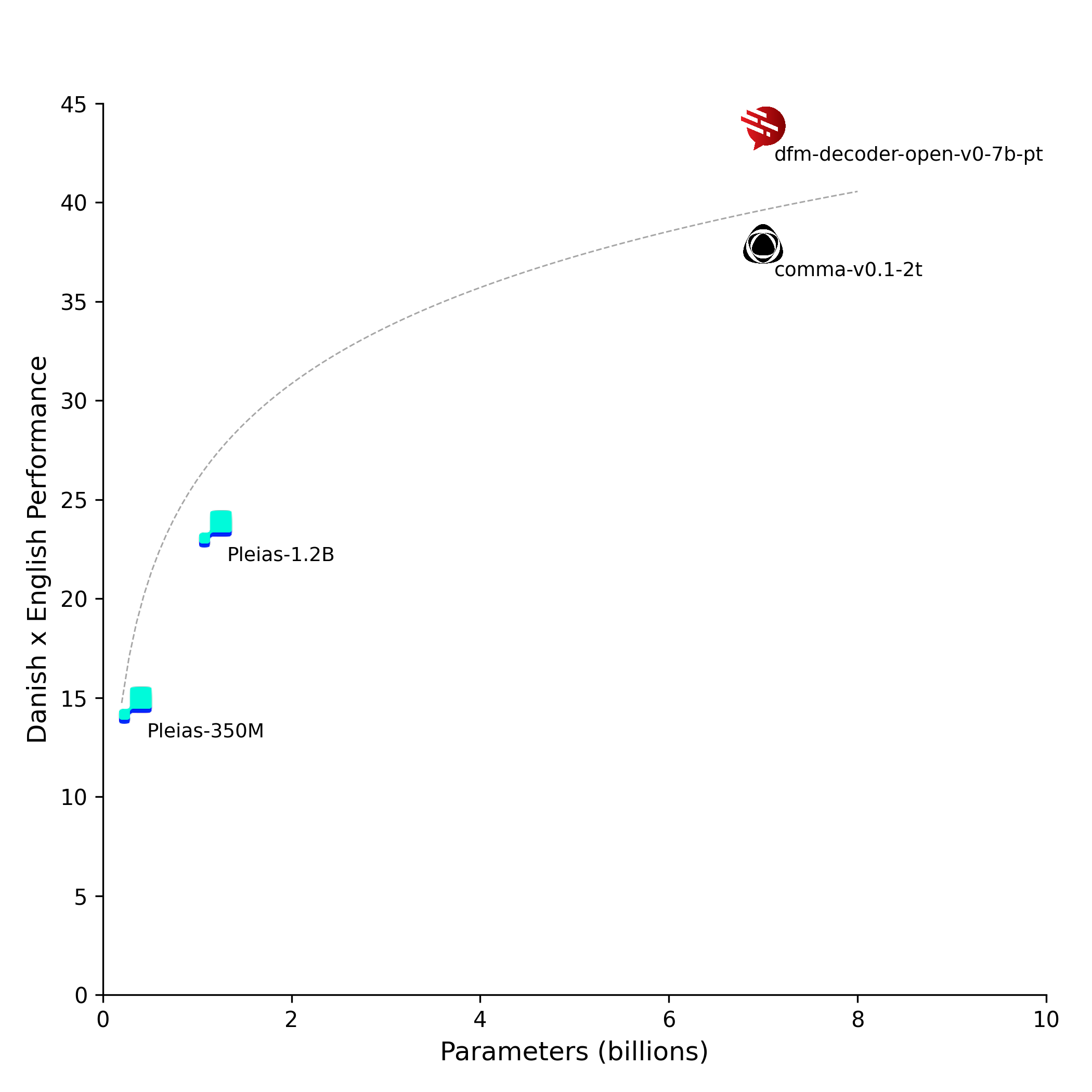
|
Git LFS Details
|
plots/danish-perf.png
ADDED
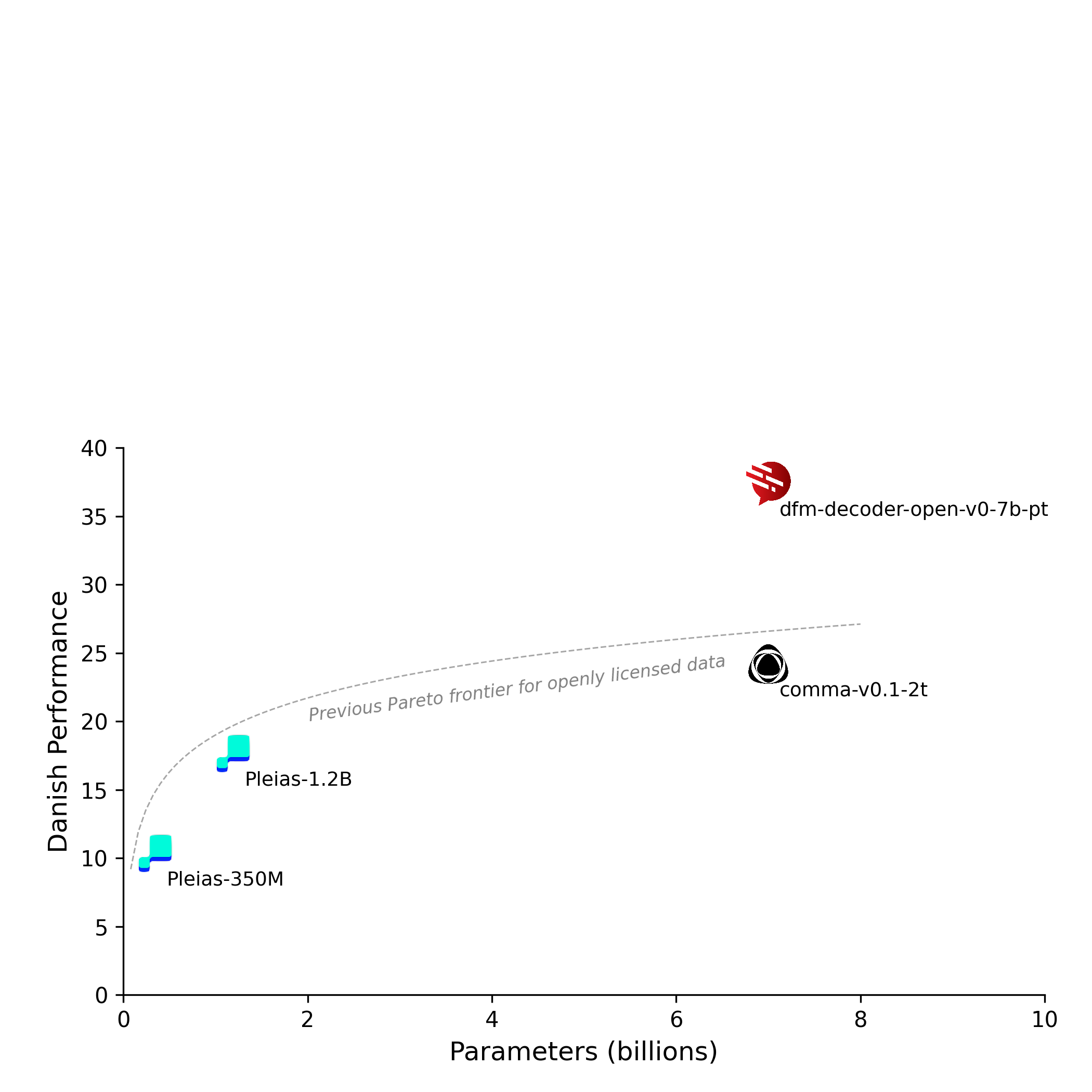
|
Git LFS Details
|
plots/dfm.png
ADDED

|
plots/eleutherai.png
ADDED

|
plots/english-perf.png
ADDED

|
plots/pleias.png
ADDED

|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin_of_text|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end_of_text|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<pad>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
stage1/config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 2,
|
| 8 |
+
"dtype": "bfloat16",
|
| 9 |
+
"eos_token_id": 3,
|
| 10 |
+
"head_dim": 128,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 4096,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 11008,
|
| 15 |
+
"max_position_embeddings": 16384,
|
| 16 |
+
"mlp_bias": false,
|
| 17 |
+
"model_type": "llama",
|
| 18 |
+
"num_attention_heads": 32,
|
| 19 |
+
"num_hidden_layers": 32,
|
| 20 |
+
"num_key_value_heads": 32,
|
| 21 |
+
"pretraining_tp": 1,
|
| 22 |
+
"rms_norm_eps": 1e-05,
|
| 23 |
+
"rope_scaling": null,
|
| 24 |
+
"rope_theta": 100000.0,
|
| 25 |
+
"tie_word_embeddings": false,
|
| 26 |
+
"transformers_version": "4.57.3",
|
| 27 |
+
"use_cache": true,
|
| 28 |
+
"vocab_size": 64256
|
| 29 |
+
}
|
stage1/generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 2,
|
| 4 |
+
"eos_token_id": 3,
|
| 5 |
+
"transformers_version": "4.57.3"
|
| 6 |
+
}
|
stage1/model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e5c530efe83db8989cd4035fc6e12e4f5bb97b95db2fddbdc271e43e9d6a8702
|
| 3 |
+
size 4978830664
|
stage1/model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7b9cb4b026a961839b052e4f6ab2789349a461c3c0f7a0592cd3014edaaa14bb
|
| 3 |
+
size 4991431432
|
stage1/model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b22ac25c3098a57faa4abe14fe67cf4fd5b8005b41e615ce4d2247d0fd43f4b9
|
| 3 |
+
size 4035085288
|
stage1/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_parameters": 7002656768,
|
| 4 |
+
"total_size": 14005313536
|
| 5 |
+
},
|
| 6 |
+
"weight_map": {
|
| 7 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 8 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 297 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 298 |
+
}
|
| 299 |
+
}
|
stage1/open-stage1.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
stage1/open-stage1.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
prefix = "munin-open"
|
| 2 |
+
tokenizer_name = "common-pile/comma-v0.1-2t"
|
| 3 |
+
|
| 4 |
+
dyna_train = {
|
| 5 |
+
"adl": 1.0,
|
| 6 |
+
"ai-aktindsigt": 1.0,
|
| 7 |
+
"botxt": 1.0,
|
| 8 |
+
"cellar": 1.0,
|
| 9 |
+
"dannet": 1.0,
|
| 10 |
+
"danske-taler": 1.0,
|
| 11 |
+
"domsdatabasen": 1.0,
|
| 12 |
+
"enevaeldens_nyheder": 1.0,
|
| 13 |
+
"ep": 1.0,
|
| 14 |
+
"eur-lex-sum-da": 1.0,
|
| 15 |
+
"fm-udgivelser": 1.0,
|
| 16 |
+
"ft": 1.0,
|
| 17 |
+
"grundtvig": 1.0,
|
| 18 |
+
"gutenberg": 1.0,
|
| 19 |
+
"health_hovedstaden": 1.0,
|
| 20 |
+
"hest": 1.0,
|
| 21 |
+
"historical-danish-handwriting": 1.0,
|
| 22 |
+
"memo": 1.0,
|
| 23 |
+
"miljoeportalen": 1.0,
|
| 24 |
+
"naat": 1.0,
|
| 25 |
+
"ncc_books": 1.0,
|
| 26 |
+
"ncc_maalfrid": 1.0,
|
| 27 |
+
"ncc_newspaper": 1.0,
|
| 28 |
+
"ncc_parliament": 1.0,
|
| 29 |
+
"nota": 1.0,
|
| 30 |
+
"opensubtitles": 1.0,
|
| 31 |
+
"relig": 1.0,
|
| 32 |
+
"retsinformationdk": 1.0,
|
| 33 |
+
"skat": 1.0,
|
| 34 |
+
"retspraksis": 1.0,
|
| 35 |
+
"spont": 1.0,
|
| 36 |
+
"tv2r": 1.0,
|
| 37 |
+
"wiki-comments": 1.0,
|
| 38 |
+
"wikibooks": 1.0,
|
| 39 |
+
"wikipedia": 1.0,
|
| 40 |
+
"wikisource": 1.0,
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
dyna_test = {
|
| 44 |
+
"depbank": 1.0,
|
| 45 |
+
"jvj": 1.0,
|
| 46 |
+
"nordjyllandnews": 1.0,
|
| 47 |
+
"synne": 1.0,
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
cp_train = {
|
| 51 |
+
"arxiv_papers": 0.5,
|
| 52 |
+
"cccc": 0.3,
|
| 53 |
+
"data_provenance_initiative": 2,
|
| 54 |
+
"doab": 2,
|
| 55 |
+
"foodista": 2,
|
| 56 |
+
"libretexts": 2,
|
| 57 |
+
"news": 2,
|
| 58 |
+
"oercommons": 2,
|
| 59 |
+
"peS2o": 0.1,
|
| 60 |
+
"pressbooks": 2,
|
| 61 |
+
"public_domain_review": 2,
|
| 62 |
+
"python_enhancement_proposals": 2,
|
| 63 |
+
"stackexchange": 0.25,
|
| 64 |
+
"stackv2_edu": 0.1,
|
| 65 |
+
"wikimedia": 0.4,
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
sources = {
|
| 69 |
+
"dyna": {
|
| 70 |
+
"uri": "hf://datasets/danish-foundation-models/danish-dynaword/data/{key}/*.parquet",
|
| 71 |
+
"format": "parquet",
|
| 72 |
+
"shards": 1,
|
| 73 |
+
"shard_index": 0,
|
| 74 |
+
"train": dyna_train,
|
| 75 |
+
"test": dyna_test,
|
| 76 |
+
},
|
| 77 |
+
"cp": {
|
| 78 |
+
"uri": "hf://datasets/common-pile/comma_v0.1_training_dataset/{key}/*.jsonl.gz",
|
| 79 |
+
"format": "json",
|
| 80 |
+
"shards": 16,
|
| 81 |
+
"shard_index": 0,
|
| 82 |
+
"train": cp_train,
|
| 83 |
+
"test": {},
|
| 84 |
+
},
|
| 85 |
+
}
|
stage1/open-stage1.toml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_name = "llama3"
|
| 2 |
+
flavor = "Comma7B"
|
| 3 |
+
tokenizer_name = "common-pile/comma-v0.1-2t"
|
| 4 |
+
|
| 5 |
+
# job
|
| 6 |
+
job_name = "munin-7b-open-stage1"
|
| 7 |
+
wandb_project = "munin-7b-open-stage1"
|
| 8 |
+
enable_wandb = false
|
| 9 |
+
|
| 10 |
+
# parallelism
|
| 11 |
+
num_nodes = 1
|
| 12 |
+
data_parallel_shard_degree = 8
|
| 13 |
+
data_parallel_replicate_degree = 1
|
| 14 |
+
|
| 15 |
+
# training settings
|
| 16 |
+
train_batch_size = 8
|
| 17 |
+
seq_len = 4096
|
| 18 |
+
train_num_steps = 37852
|
| 19 |
+
scheduler = "linear_warmup_constant_sqrt_decay"
|
| 20 |
+
warmup_steps = 1000
|
| 21 |
+
cooldown_steps = 1000
|
| 22 |
+
checkpoint_interval = 1000
|
| 23 |
+
forced_load_path = "/work/training/maester/comma-v0.1-2t-dcp/"
|
| 24 |
+
compile = true
|
| 25 |
+
enable_cut_cross_entropy = false
|
| 26 |
+
ac_mode = "none"
|
| 27 |
+
selective_ac_option = "op"
|
| 28 |
+
|
| 29 |
+
[dataset]
|
| 30 |
+
bos_token = 2
|
| 31 |
+
eos_token = 1
|
| 32 |
+
data_dirs = [
|
| 33 |
+
"/work/production/data/munin-open-dyna-0-of-1-cp-0-of-16-train/",
|
| 34 |
+
]
|
| 35 |
+
dataset_weights = "1.0"
|
| 36 |
+
|
| 37 |
+
[opt_cfg] # must specify *all* fields here, will not merge with defaults
|
| 38 |
+
lr = 1e-5
|
| 39 |
+
betas = [0.9, 0.95]
|
| 40 |
+
weight_decay = 0.1
|
| 41 |
+
eps = 1e-9
|
| 42 |
+
fused = true
|
stage1/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin_of_text|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end_of_text|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<pad>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
stage1/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
stage1/tokenizer_config.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<pad>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<unk>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "<|begin_of_text|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"3": {
|
| 30 |
+
"content": "<|end_of_text|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
"bos_token": "<|begin_of_text|>",
|
| 39 |
+
"clean_up_tokenization_spaces": false,
|
| 40 |
+
"eos_token": "<|end_of_text|>",
|
| 41 |
+
"extra_special_tokens": {},
|
| 42 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 43 |
+
"pad_token": "<pad>",
|
| 44 |
+
"tokenizer_class": "PreTrainedTokenizerFast",
|
| 45 |
+
"unk_token": "<unk>"
|
| 46 |
+
}
|
stage2/config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 2,
|
| 8 |
+
"dtype": "bfloat16",
|
| 9 |
+
"eos_token_id": 3,
|
| 10 |
+
"head_dim": 128,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 4096,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 11008,
|
| 15 |
+
"max_position_embeddings": 16384,
|
| 16 |
+
"mlp_bias": false,
|
| 17 |
+
"model_type": "llama",
|
| 18 |
+
"num_attention_heads": 32,
|
| 19 |
+
"num_hidden_layers": 32,
|
| 20 |
+
"num_key_value_heads": 32,
|
| 21 |
+
"pretraining_tp": 1,
|
| 22 |
+
"rms_norm_eps": 1e-05,
|
| 23 |
+
"rope_scaling": null,
|
| 24 |
+
"rope_theta": 100000.0,
|
| 25 |
+
"tie_word_embeddings": false,
|
| 26 |
+
"transformers_version": "4.57.3",
|
| 27 |
+
"use_cache": true,
|
| 28 |
+
"vocab_size": 64256
|
| 29 |
+
}
|
stage2/generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 2,
|
| 4 |
+
"eos_token_id": 3,
|
| 5 |
+
"transformers_version": "4.57.3"
|
| 6 |
+
}
|
stage2/model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ac8613519b12f0fcb8ecba02a1cbaa11200ef6eb66c44acee5c51f1d3b12ee5
|
| 3 |
+
size 4978830664
|
stage2/model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7c80dcd1d81e4cc66f0ef72fdc4f5be654857b23aa286900121d3bdd2eeb2d18
|
| 3 |
+
size 4991431432
|
stage2/model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0eddc6ee90d5c0e9e07e8fb2add63e0c625a29a66fb6044f5d82c93d7dc0aa98
|
| 3 |
+
size 4035085288
|
stage2/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_parameters": 7002656768,
|
| 4 |
+
"total_size": 14005313536
|
| 5 |
+
},
|
| 6 |
+
"weight_map": {
|
| 7 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 8 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 297 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 298 |
+
}
|
| 299 |
+
}
|
stage2/open-stage2.log
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
stage2/open-stage2.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
prefix = "munin-open"
|
| 2 |
+
tokenizer_name = "common-pile/comma-v0.1-2t"
|
| 3 |
+
|
| 4 |
+
dyna_train = {
|
| 5 |
+
"adl": 1.0,
|
| 6 |
+
"ai-aktindsigt": 1.0,
|
| 7 |
+
"botxt": 1.0,
|
| 8 |
+
"cellar": 1.0,
|
| 9 |
+
"dannet": 1.0,
|
| 10 |
+
"danske-taler": 1.0,
|
| 11 |
+
"domsdatabasen": 1.0,
|
| 12 |
+
"enevaeldens_nyheder": 1.0,
|
| 13 |
+
"ep": 1.0,
|
| 14 |
+
"eur-lex-sum-da": 1.0,
|
| 15 |
+
"fm-udgivelser": 1.0,
|
| 16 |
+
"ft": 1.0,
|
| 17 |
+
"grundtvig": 1.0,
|
| 18 |
+
"gutenberg": 1.0,
|
| 19 |
+
"health_hovedstaden": 1.0,
|
| 20 |
+
"hest": 1.0,
|
| 21 |
+
"historical-danish-handwriting": 1.0,
|
| 22 |
+
"memo": 1.0,
|
| 23 |
+
"miljoeportalen": 1.0,
|
| 24 |
+
"naat": 1.0,
|
| 25 |
+
"ncc_books": 1.0,
|
| 26 |
+
"ncc_maalfrid": 1.0,
|
| 27 |
+
"ncc_newspaper": 1.0,
|
| 28 |
+
"ncc_parliament": 1.0,
|
| 29 |
+
"nota": 1.0,
|
| 30 |
+
"opensubtitles": 1.0,
|
| 31 |
+
"relig": 1.0,
|
| 32 |
+
"retsinformationdk": 1.0,
|
| 33 |
+
"skat": 1.0,
|
| 34 |
+
"retspraksis": 1.0,
|
| 35 |
+
"spont": 1.0,
|
| 36 |
+
"tv2r": 1.0,
|
| 37 |
+
"wiki-comments": 1.0,
|
| 38 |
+
"wikibooks": 1.0,
|
| 39 |
+
"wikipedia": 1.0,
|
| 40 |
+
"wikisource": 1.0,
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
dyna_test = {
|
| 44 |
+
"depbank": 1.0,
|
| 45 |
+
"jvj": 1.0,
|
| 46 |
+
"nordjyllandnews": 1.0,
|
| 47 |
+
"synne": 1.0,
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
cp_train = {
|
| 51 |
+
"arxiv_papers": 0.5,
|
| 52 |
+
"cccc": 0.3,
|
| 53 |
+
"data_provenance_initiative": 2,
|
| 54 |
+
"doab": 2,
|
| 55 |
+
"foodista": 2,
|
| 56 |
+
"libretexts": 2,
|
| 57 |
+
"news": 2,
|
| 58 |
+
"oercommons": 2,
|
| 59 |
+
"peS2o": 0.1,
|
| 60 |
+
"pressbooks": 2,
|
| 61 |
+
"public_domain_review": 2,
|
| 62 |
+
"python_enhancement_proposals": 2,
|
| 63 |
+
"stackexchange": 0.25,
|
| 64 |
+
"stackv2_edu": 0.1,
|
| 65 |
+
"wikimedia": 0.4,
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
sources = {
|
| 69 |
+
"dyna": {
|
| 70 |
+
"uri": "hf://datasets/danish-foundation-models/danish-dynaword/data/{key}/*.parquet",
|
| 71 |
+
"format": "parquet",
|
| 72 |
+
"shards": 1,
|
| 73 |
+
"shard_index": 0,
|
| 74 |
+
"train": dyna_train,
|
| 75 |
+
"test": dyna_test,
|
| 76 |
+
},
|
| 77 |
+
"cp": {
|
| 78 |
+
"uri": "hf://datasets/common-pile/comma_v0.1_training_dataset/{key}/*.jsonl.gz",
|
| 79 |
+
"format": "json",
|
| 80 |
+
"shards": 16,
|
| 81 |
+
"shard_index": 1,
|
| 82 |
+
"train": cp_train,
|
| 83 |
+
"test": {},
|
| 84 |
+
},
|
| 85 |
+
}
|
stage2/open-stage2.toml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model_name = "llama3"
|
| 2 |
+
flavor = "Comma7B"
|
| 3 |
+
tokenizer_name = "common-pile/comma-v0.1-2t"
|
| 4 |
+
|
| 5 |
+
# job
|
| 6 |
+
job_name = "munin-7b-open-stage2"
|
| 7 |
+
wandb_project = "munin-7b-open-stage2"
|
| 8 |
+
enable_wandb = false
|
| 9 |
+
|
| 10 |
+
# parallelism
|
| 11 |
+
num_nodes = 1
|
| 12 |
+
data_parallel_shard_degree = 8
|
| 13 |
+
data_parallel_replicate_degree = 1
|
| 14 |
+
|
| 15 |
+
# training settings
|
| 16 |
+
train_batch_size = 8
|
| 17 |
+
gradient_accumulation_steps = 2
|
| 18 |
+
gradient_accumulation_sync_each_step = true
|
| 19 |
+
seq_len = 4096
|
| 20 |
+
train_num_steps = 18926 # 37852 // 2
|
| 21 |
+
scheduler = "linear_warmup_constant_sqrt_decay"
|
| 22 |
+
warmup_steps = 500
|
| 23 |
+
cooldown_steps = 500
|
| 24 |
+
checkpoint_interval = 1000
|
| 25 |
+
forced_load_path = "/work/training/maester/jobs/munin-7b-open-stage1/checkpoints/step-37852/"
|
| 26 |
+
compile = true
|
| 27 |
+
enable_cut_cross_entropy = false
|
| 28 |
+
ac_mode = "none"
|
| 29 |
+
selective_ac_option = "op"
|
| 30 |
+
|
| 31 |
+
[dataset]
|
| 32 |
+
bos_token = 2
|
| 33 |
+
eos_token = 1
|
| 34 |
+
data_dirs = [
|
| 35 |
+
"/work/production/data/munin-open-dyna-0-of-1-cp-1-of-16-train/",
|
| 36 |
+
]
|
| 37 |
+
dataset_weights = "1.0"
|
| 38 |
+
|
| 39 |
+
[opt_cfg] # must specify *all* fields here, will not merge with defaults
|
| 40 |
+
lr = 1e-5
|
| 41 |
+
betas = [0.9, 0.95]
|
| 42 |
+
weight_decay = 0.1
|
| 43 |
+
eps = 1e-9
|
| 44 |
+
fused = true
|
stage2/special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin_of_text|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end_of_text|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<pad>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"unk_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
stage2/tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
stage2/tokenizer_config.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<pad>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<unk>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "<|begin_of_text|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"3": {
|
| 30 |
+
"content": "<|end_of_text|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
"bos_token": "<|begin_of_text|>",
|
| 39 |
+
"clean_up_tokenization_spaces": false,
|
| 40 |
+
"eos_token": "<|end_of_text|>",
|
| 41 |
+
"extra_special_tokens": {},
|
| 42 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 43 |
+
"pad_token": "<pad>",
|
| 44 |
+
"tokenizer_class": "PreTrainedTokenizerFast",
|
| 45 |
+
"unk_token": "<unk>"
|
| 46 |
+
}
|
stage3/config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"LlamaForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 2,
|
| 8 |
+
"dtype": "bfloat16",
|
| 9 |
+
"eos_token_id": 3,
|
| 10 |
+
"head_dim": 128,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 4096,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 11008,
|
| 15 |
+
"max_position_embeddings": 16384,
|
| 16 |
+
"mlp_bias": false,
|
| 17 |
+
"model_type": "llama",
|
| 18 |
+
"num_attention_heads": 32,
|
| 19 |
+
"num_hidden_layers": 32,
|
| 20 |
+
"num_key_value_heads": 32,
|
| 21 |
+
"pretraining_tp": 1,
|
| 22 |
+
"rms_norm_eps": 1e-05,
|
| 23 |
+
"rope_scaling": null,
|
| 24 |
+
"rope_theta": 100000.0,
|
| 25 |
+
"tie_word_embeddings": false,
|
| 26 |
+
"transformers_version": "4.57.3",
|
| 27 |
+
"use_cache": true,
|
| 28 |
+
"vocab_size": 64256
|
| 29 |
+
}
|
stage3/generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 2,
|
| 4 |
+
"eos_token_id": 3,
|
| 5 |
+
"transformers_version": "4.57.3"
|
| 6 |
+
}
|
stage3/index.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from safetensors.torch import load_file
|
| 3 |
+
|
| 4 |
+
path = "model.safetensors"
|
| 5 |
+
tensors = load_file(path)
|
| 6 |
+
|
| 7 |
+
weight_map = {}
|
| 8 |
+
total_size = 0
|
| 9 |
+
|
| 10 |
+
for name, tensor in tensors.items():
|
| 11 |
+
weight_map[name] = "model.safetensors"
|
| 12 |
+
total_size += tensor.element_size() * tensor.numel()
|
| 13 |
+
|
| 14 |
+
index = {
|
| 15 |
+
"metadata": {"total_size": str(total_size)},
|
| 16 |
+
"weight_map": weight_map,
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
with open("model.safetensors.index.json", "w") as f:
|
| 20 |
+
json.dump(index, f, indent=2)
|
stage3/model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d56eb49f03ee932518e3e7c55f6c46a15177dce57662ad91417c65ba4cd794f8
|
| 3 |
+
size 4978830664
|
stage3/model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6df9d3b3790135776e05993005383d8066bb2560e15b39bbb29b3c43ea0ee795
|
| 3 |
+
size 4991431432
|
stage3/model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0cb865281fd75e9ac348d05160e4f3468a7d934c103d63ceb9b95887e1a8005
|
| 3 |
+
size 4035085288
|
stage3/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_parameters": 7002656768,
|
| 4 |
+
"total_size": 14005313536
|
| 5 |
+
},
|
| 6 |
+
"weight_map": {
|
| 7 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 8 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 297 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 298 |
+
}
|
| 299 |
+
}
|