![]()
![]()
![]()

Video 1. Synchronized Multi-View Recordings. High-resolution streams from four synchronized views — an ego-centric head-mounted camera, left and right wrist-mounted cameras, and a static third-person scene camera — synchronized with 36-DoF robot proprioception.

Fig 1. High-Fidelity Real-World Scenes. Collected via our hybrid teleoperation system (Exoskeleton for arm + Vision Pro for hand), this dataset covers 347 objects across diverse environments. It captures varying lighting conditions, background clutter, and precise bimanual interactions essential for robust policy learning. Panels (a–d) correspond to four task categories: pick-and-place, assembly, articulation, and dexterous manipulation.
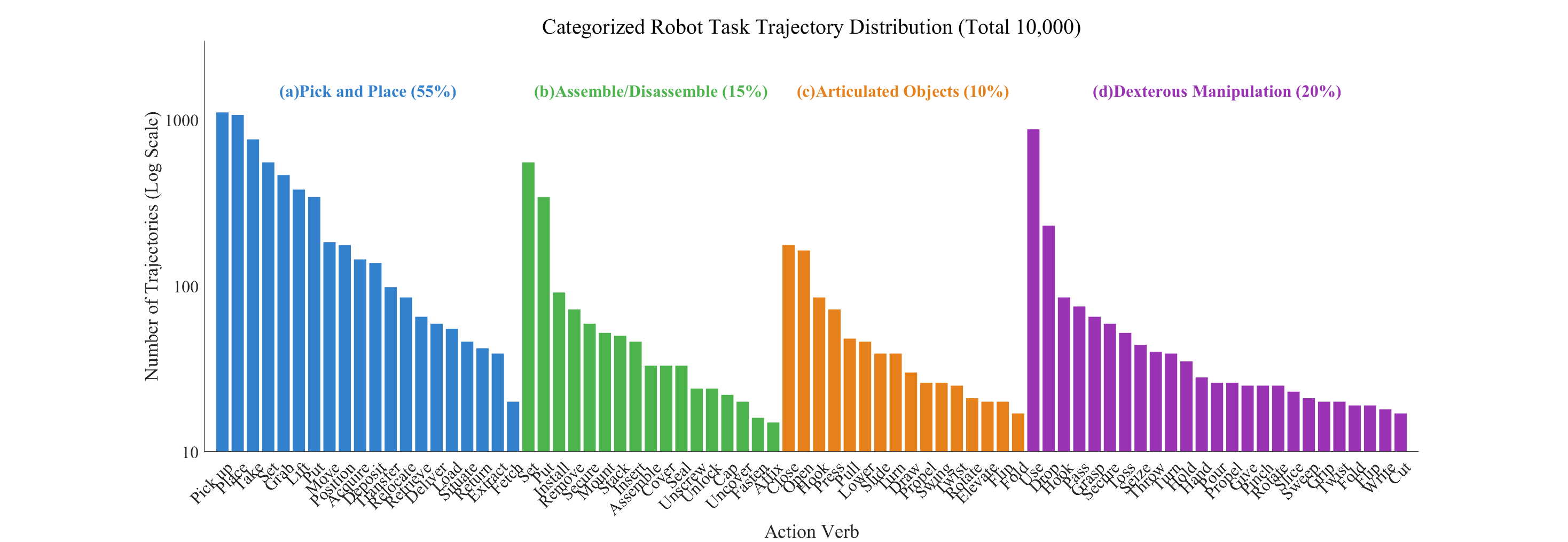
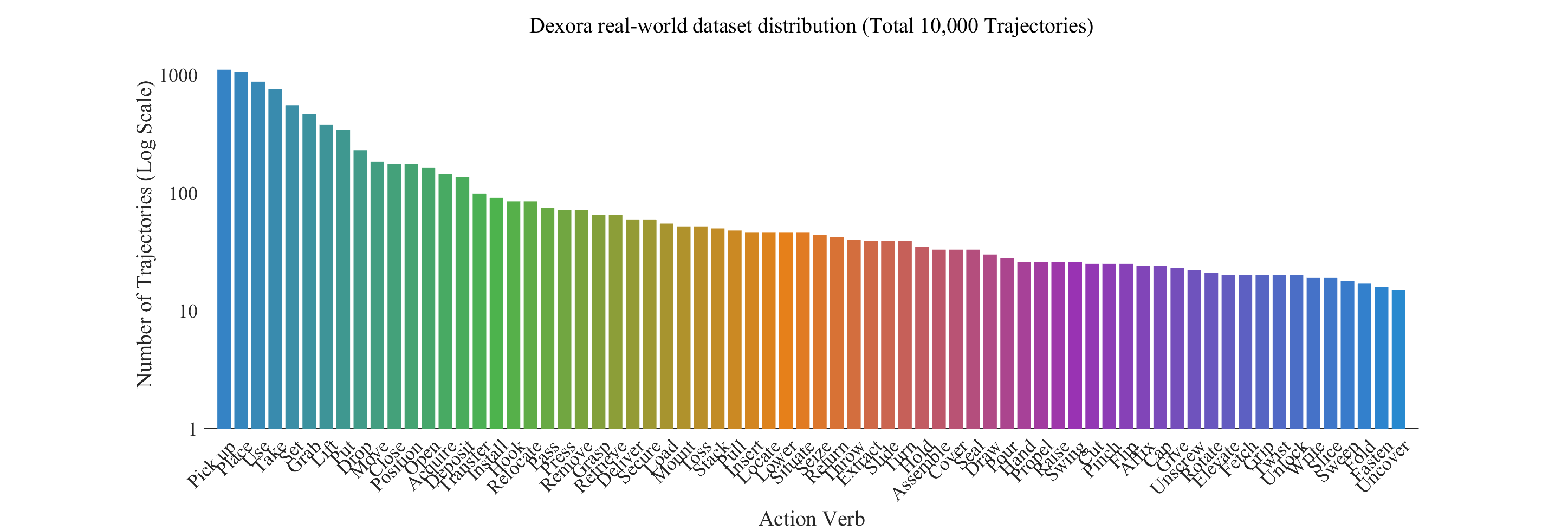
Fig 2. Task Categories & Action Distribution. Unlike standard gripper datasets, Dexora emphasizes high-DoF dexterity. The real-world data distribution includes Dexterous Manipulation (20%) (e.g., Twist Cap, Use Pen, Cut Leek) and Assembly (15%) (e.g., Separate Nested Bowls, Stack Ring Blocks), in addition to Articulated Objects (10%) and Pick-and-Place (55%).
Both the episodes and annotations follow the **LIBERO-2.1 standard**, including synchronized **RGB observations**, **robot proprioception**, **actions**, and **language instructions**. ### Object Inventory & Reproducibility Reproducibility is a **core value** of Dexora. To enable other labs and industry teams to **faithfully recreate** our environments, we release a **curated object inventory** that mirrors the physical setup used in our real-world experiments. - **Scale**: **347 objects** across **17 semantic categories** (e.g., tools, containers, articulated objects, deformables, daily-use items). - **Coverage**: Objects are chosen to stress **dexterous control**, **bimanual coordination**, and **long-horizon manipulation**. - **Procurement**: Every item is linked to **Taobao** and/or **Amazon**, so researchers can rebuild the setup with minimal effort. ### Inventory Metadata Schema The released Google Sheet follows the schema below: | Column | Description | | :------------------------- | :-------------------------------------------------------------------------- | | **Object Name (EN & CN)** | Bilingual identification for global researchers. | | **Task Type** | One of: `pick-and-place`, `assemble`, `articulation`, `dexterous`. | | **Purchase Link** | Direct links to **Taobao** & **Amazon** for easy procurement and restock. | You can **filter by task type**, **category**, or **store** to design controlled benchmarks or new task suites on top of Dexora. ### B. Dexora Simulation Dataset (Large-Scale) The Dexora simulation dataset contains **100K episodes** generated in **MuJoCo**, using the same **36-DoF dual-arm, dual-hand** embodiment as the real robot. It provides large-scale, embodiment-matched experience focused on core skills such as **pick-and-place**, **assembly**, and **articulation**, which can be used for pre-training basic competence before **fine-tuning on the real-world dataset**. ### Summary Statistics (Sim vs Real) | **Split** | **Episodes** | **Frames** | **Hours (approx.)** | **Task Types** | | :--------------- | -----------: | ---------: | -------------------: | :----------------------------------------------------------------------------- | | **Simulated** | **——** | **——** | TBD | Pick-and-place, assembly, articulation | | **Real-World** | **11.5K** | **2.92M** | **40.5** | Teleoperated bimanual tasks with high-DoF hands, cluttered scenes, fine-grain object interactions | ## 📂 Data Structure Dexora follows the **LIBERO-2.1** dataset standard. Each episode is stored as a self-contained trajectory with: - **Observations**: multi-view RGB (and optionally depth), segmentation masks (when available). - **Robot State**: joint positions/velocities for dual arms and dual hands, gripper/hand states. - **Actions**: low-level control commands compatible with 36-DoF bimanual control. - **Language**: High-level task descriptions. We provide **5 diverse natural language instructions** per task, distributed evenly across all trajectories to enhance linguistic diversity. An example high-level directory layout is: ```text data ├── real │ ├── articulation │ │ └── ... │ ├── assembly │ │ └── ... │ ├── dexterous manipulation │ │ ├── data │ │ │ ├── chunk-000 │ │ │ │ ├── episode_000000.parquet │ │ │ │ ├── episode_000001.parquet │ │ │ │ ├── episode_000002.parquet │ │ │ │ ├── ... │ │ │ ├── chunk-001 │ │ │ │ ├── ... │ │ │ ├── ... │ │ ├── meta │ │ │ ├── episodes.jsonl │ │ │ ├── episodes_stats.jsonl │ │ │ ├── info.json │ │ │ ├── modality.json │ │ │ ├── stats.json │ │ │ ├── tasks.jsonl │ │ ├── videos │ │ │ ├── chunk-000 │ │ │ │ ├── observation.images.front │ │ │ │ │ ├── episode_000000.mp4 │ │ │ │ │ ├── episode_000001.mp4 │ │ │ │ │ ├── ... │ │ │ │ ├── ... │ │ │ ├── chunk-001 │ │ │ │ ├── ... │ │ │ ├── ... │ ├── pick_and_place │ │ └── ... │ ├── ... ├── sim │ ├── ... ``` > **Note**: The exact folder names and file formats may be updated as we finalize the public release, but the overall **episode-centric LIBERO-2.1 structure** will be preserved. --- ### [meta/info.json](meta/info.json): ```json { "codebase_version": "v2.1", "robot_type": "airbot_play", "total_episodes": 11517, "total_frames": 2919110, "total_tasks": 201, "total_videos": 46068, "total_chunks": 12, "chunks_size": 1000, "fps": 20, "splits": { "train": "0:2261" }, "data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet", "video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4", "features": { "observation.images.top": { "dtype": "video", "shape": [ 480, 640, 3 ], "names": [ "height", "width", "channels" ], "info": { "video.height": 480, "video.width": 640, "video.codec": "av1", "video.pix_fmt": "yuv420p", "video.is_depth_map": false, "video.fps": 20, "video.channels": 3, "has_audio": false } }, "observation.images.wrist_left": { "dtype": "video", "shape": [ 480, 640, 3 ], "names": [ "height", "width", "channels" ], "info": { "video.height": 480, "video.width": 640, "video.codec": "av1", "video.pix_fmt": "yuv420p", "video.is_depth_map": false, "video.fps": 20, "video.channels": 3, "has_audio": false } }, "observation.images.wrist_right": { "dtype": "video", "shape": [ 480, 640, 3 ], "names": [ "height", "width", "channels" ], "info": { "video.height": 480, "video.width": 640, "video.codec": "av1", "video.pix_fmt": "yuv420p", "video.is_depth_map": false, "video.fps": 20, "video.channels": 3, "has_audio": false } }, "observation.images.front": { "dtype": "video", "shape": [ 480, 640, 3 ], "names": [ "height", "width", "channels" ], "info": { "video.height": 480, "video.width": 640, "video.codec": "av1", "video.pix_fmt": "yuv420p", "video.is_depth_map": false, "video.fps": 20, "video.channels": 3, "has_audio": false } }, "observation.state": { "dtype": "float32", "shape": [ 39 ], "names": [ "left_arm_joint_1", "left_arm_joint_2", "left_arm_joint_3", "left_arm_joint_4", "left_arm_joint_5", "left_arm_joint_6", "right_arm_joint_1", "right_arm_joint_2", "right_arm_joint_3", "right_arm_joint_4", "right_arm_joint_5", "right_arm_joint_6", "left_hand_joint_1", "left_hand_joint_2", "left_hand_joint_3", "left_hand_joint_4", "left_hand_joint_5", "left_hand_joint_6", "left_hand_joint_7", "left_hand_joint_8", "left_hand_joint_9", "left_hand_joint_10", "left_hand_joint_11", "left_hand_joint_12", "right_hand_joint_1", "right_hand_joint_2", "right_hand_joint_3", "right_hand_joint_4", "right_hand_joint_5", "right_hand_joint_6", "right_hand_joint_7", "right_hand_joint_8", "right_hand_joint_9", "right_hand_joint_10", "right_hand_joint_11", "right_hand_joint_12", "head_joint_1", "head_joint_2", "spine_joint" ] }, "action": { "dtype": "float32", "shape": [ 39 ], "names": [ "left_arm_joint_1", "left_arm_joint_2", "left_arm_joint_3", "left_arm_joint_4", "left_arm_joint_5", "left_arm_joint_6", "right_arm_joint_1", "right_arm_joint_2", "right_arm_joint_3", "right_arm_joint_4", "right_arm_joint_5", "right_arm_joint_6", "left_hand_joint_1", "left_hand_joint_2", "left_hand_joint_3", "left_hand_joint_4", "left_hand_joint_5", "left_hand_joint_6", "left_hand_joint_7", "left_hand_joint_8", "left_hand_joint_9", "left_hand_joint_10", "left_hand_joint_11", "left_hand_joint_12", "right_hand_joint_1", "right_hand_joint_2", "right_hand_joint_3", "right_hand_joint_4", "right_hand_joint_5", "right_hand_joint_6", "right_hand_joint_7", "right_hand_joint_8", "right_hand_joint_9", "right_hand_joint_10", "right_hand_joint_11", "right_hand_joint_12", "head_joint_1", "head_joint_2", "spine_joint" ] }, "timestamp": { "dtype": "float32", "shape": [ 1 ], "names": null }, "frame_index": { "dtype": "int64", "shape": [ 1 ], "names": null }, "episode_index": { "dtype": "int64", "shape": [ 1 ], "names": null }, "index": { "dtype": "int64", "shape": [ 1 ], "names": null }, "task_index": { "dtype": "int64", "shape": [ 1 ], "names": null } } } ``` ## 📜 Citation If you find Dexora useful in your research, please consider citing our paper: ```bibtex @misc{dexora2026, title = {Dexora: Open-Source VLA for High-DoF Bimanual Dexterity}, author = {Dexora Team}, year = {2026}, archivePrefix = {arXiv}, eprint = {xxxx.xxxxx}, primaryClass = {cs.RO} } ``` --- For questions, collaborations, or feedback, please feel free to open an issue or contact the maintainers via the project page.