
Upload 63 files
Browse filesAdded Inference code, demo data and config and slum script
This view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +13 -0
- NoMAISI_logo.png +3 -0
- configs/config_maisi3d-rflow.json +150 -0
- configs/infr_config_NoMAISI_controlnet.json +17 -0
- configs/infr_env_NoMAISI_DLCSD24_demo.json +11 -0
- data/DLCS_1419_seg_sh.nii.gz +3 -0
- data/infr_NoMAISI_DLCSD24_demo_512xy_256z_771p25m_dataset.json +32 -0
- doc/images/DLCS_1419_ann0_slice134_triple.png +3 -0
- doc/images/DLCS_1419_ann1_slice204_triple.png +3 -0
- doc/images/DLCS_1443_ann1_slice125_triple.png +3 -0
- doc/images/DLCS_1446_ann0_slice122_triple.png +3 -0
- doc/images/DLCS_1447_ann0_slice206_triple.png +3 -0
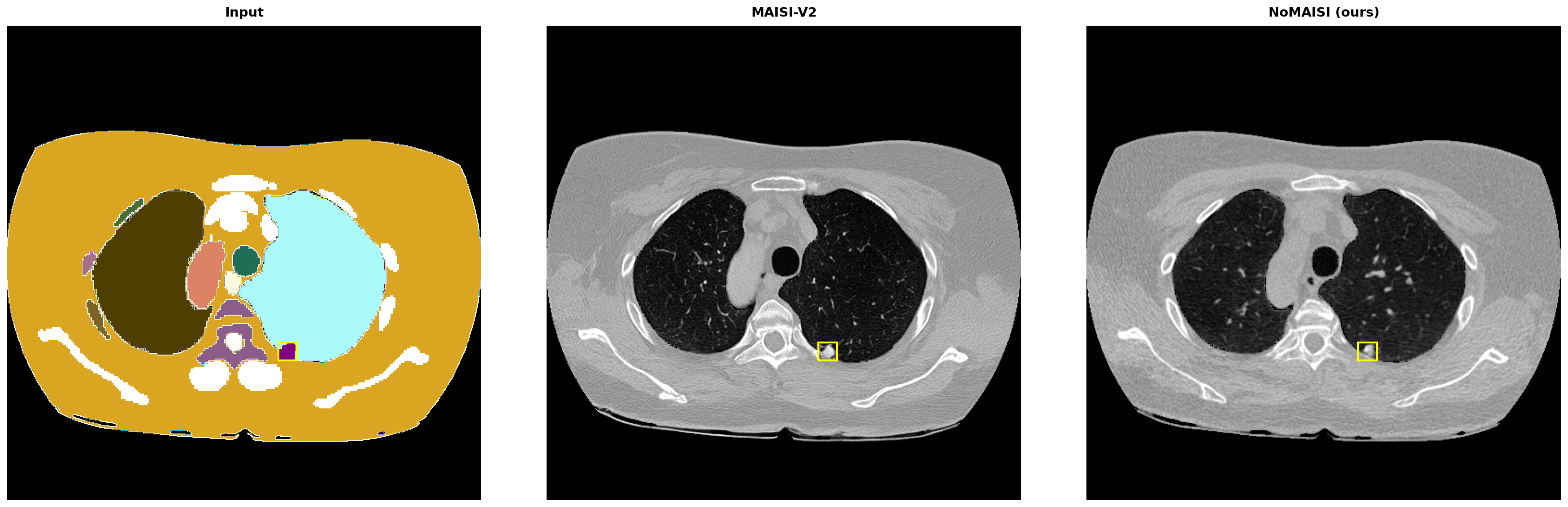
- doc/images/DLCS_1453_ann0_slice204_triple.png +3 -0
- doc/images/DLCS_1508_ann0_slice46_triple.png +3 -0
- doc/images/DLCS_1519_ann3_slice155_triple.png +3 -0
- doc/images/GanAI_fid_scatter_marker_legend.png +3 -0
- doc/images/NoMAISI_train_and_infer.png +3 -0
- doc/images/TaskCls.png +3 -0
- doc/images/workflow.png +3 -0
- inference.sub +26 -0
- logs/NoMAISI-infr-log-38612.out +18 -0
- scripts/__init__.py +10 -0
- scripts/__pycache__/__init__.cpython-310.pyc +0 -0
- scripts/__pycache__/augmentation.cpython-310.pyc +0 -0
- scripts/__pycache__/diff_model_create_training_data.cpython-310.pyc +0 -0
- scripts/__pycache__/diff_model_setting.cpython-310.pyc +0 -0
- scripts/__pycache__/find_masks.cpython-310.pyc +0 -0
- scripts/__pycache__/infer_controlnet.cpython-310.pyc +0 -0
- scripts/__pycache__/infer_testV2_controlnet.cpython-310.pyc +0 -0
- scripts/__pycache__/infer_test_controlnet.cpython-310.pyc +0 -0
- scripts/__pycache__/inference.cpython-310.pyc +0 -0
- scripts/__pycache__/quality_check.cpython-310.pyc +0 -0
- scripts/__pycache__/rectified_flow.cpython-310.pyc +0 -0
- scripts/__pycache__/sample.cpython-310.pyc +0 -0
- scripts/__pycache__/train_controlnet.cpython-310.pyc +0 -0
- scripts/__pycache__/utils.cpython-310.pyc +0 -0
- scripts/__pycache__/utils_plot.cpython-310.pyc +0 -0
- scripts/augmentation.py +373 -0
- scripts/compute_fid_2-5d_ct.py +747 -0
- scripts/diff_model_create_training_data.py +231 -0
- scripts/diff_model_infer.py +358 -0
- scripts/diff_model_setting.py +92 -0
- scripts/diff_model_train.py +499 -0
- scripts/find_masks.py +157 -0
- scripts/infer_controlnet.py +222 -0
- scripts/infer_testV2_controlnet.py +220 -0
- scripts/infer_test_controlnet.py +220 -0
- scripts/inference.py +299 -0
- scripts/quality_check.py +149 -0
- scripts/rectified_flow.py +322 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,16 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
doc/images/DLCS_1419_ann0_slice134_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
doc/images/DLCS_1419_ann1_slice204_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
doc/images/DLCS_1443_ann1_slice125_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
doc/images/DLCS_1446_ann0_slice122_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
doc/images/DLCS_1447_ann0_slice206_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
doc/images/DLCS_1453_ann0_slice204_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
doc/images/DLCS_1508_ann0_slice46_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
doc/images/DLCS_1519_ann3_slice155_triple.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
doc/images/GanAI_fid_scatter_marker_legend.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
doc/images/NoMAISI_train_and_infer.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
doc/images/TaskCls.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
doc/images/workflow.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
NoMAISI_logo.png filter=lfs diff=lfs merge=lfs -text
|
NoMAISI_logo.png
ADDED
|
|
Git LFS Details
|
configs/config_maisi3d-rflow.json
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"spatial_dims": 3,
|
| 3 |
+
"image_channels": 1,
|
| 4 |
+
"latent_channels": 4,
|
| 5 |
+
"include_body_region": false,
|
| 6 |
+
"mask_generation_latent_shape": [
|
| 7 |
+
4,
|
| 8 |
+
64,
|
| 9 |
+
64,
|
| 10 |
+
64
|
| 11 |
+
],
|
| 12 |
+
"autoencoder_def": {
|
| 13 |
+
"_target_": "monai.apps.generation.maisi.networks.autoencoderkl_maisi.AutoencoderKlMaisi",
|
| 14 |
+
"spatial_dims": "@spatial_dims",
|
| 15 |
+
"in_channels": "@image_channels",
|
| 16 |
+
"out_channels": "@image_channels",
|
| 17 |
+
"latent_channels": "@latent_channels",
|
| 18 |
+
"num_channels": [
|
| 19 |
+
64,
|
| 20 |
+
128,
|
| 21 |
+
256
|
| 22 |
+
],
|
| 23 |
+
"num_res_blocks": [2,2,2],
|
| 24 |
+
"norm_num_groups": 32,
|
| 25 |
+
"norm_eps": 1e-06,
|
| 26 |
+
"attention_levels": [
|
| 27 |
+
false,
|
| 28 |
+
false,
|
| 29 |
+
false
|
| 30 |
+
],
|
| 31 |
+
"with_encoder_nonlocal_attn": false,
|
| 32 |
+
"with_decoder_nonlocal_attn": false,
|
| 33 |
+
"use_checkpointing": false,
|
| 34 |
+
"use_convtranspose": false,
|
| 35 |
+
"norm_float16": true,
|
| 36 |
+
"num_splits": 4,
|
| 37 |
+
"dim_split": 1
|
| 38 |
+
},
|
| 39 |
+
"diffusion_unet_def": {
|
| 40 |
+
"_target_": "monai.apps.generation.maisi.networks.diffusion_model_unet_maisi.DiffusionModelUNetMaisi",
|
| 41 |
+
"spatial_dims": "@spatial_dims",
|
| 42 |
+
"in_channels": "@latent_channels",
|
| 43 |
+
"out_channels": "@latent_channels",
|
| 44 |
+
"num_channels": [64, 128, 256, 512],
|
| 45 |
+
"attention_levels": [
|
| 46 |
+
false,
|
| 47 |
+
false,
|
| 48 |
+
true,
|
| 49 |
+
true
|
| 50 |
+
],
|
| 51 |
+
"num_head_channels": [
|
| 52 |
+
0,
|
| 53 |
+
0,
|
| 54 |
+
32,
|
| 55 |
+
32
|
| 56 |
+
],
|
| 57 |
+
"num_res_blocks": 2,
|
| 58 |
+
"use_flash_attention": true,
|
| 59 |
+
"include_top_region_index_input": "@include_body_region",
|
| 60 |
+
"include_bottom_region_index_input": "@include_body_region",
|
| 61 |
+
"include_spacing_input": true,
|
| 62 |
+
"num_class_embeds": 128,
|
| 63 |
+
"resblock_updown": true,
|
| 64 |
+
"include_fc": true
|
| 65 |
+
},
|
| 66 |
+
"controlnet_def": {
|
| 67 |
+
"_target_": "monai.apps.generation.maisi.networks.controlnet_maisi.ControlNetMaisi",
|
| 68 |
+
"spatial_dims": "@spatial_dims",
|
| 69 |
+
"in_channels": "@latent_channels",
|
| 70 |
+
"num_channels": [64, 128, 256, 512],
|
| 71 |
+
"attention_levels": [
|
| 72 |
+
false,
|
| 73 |
+
false,
|
| 74 |
+
true,
|
| 75 |
+
true
|
| 76 |
+
],
|
| 77 |
+
"num_head_channels": [
|
| 78 |
+
0,
|
| 79 |
+
0,
|
| 80 |
+
32,
|
| 81 |
+
32
|
| 82 |
+
],
|
| 83 |
+
"num_res_blocks": 2,
|
| 84 |
+
"use_flash_attention": true,
|
| 85 |
+
"conditioning_embedding_in_channels": 8,
|
| 86 |
+
"conditioning_embedding_num_channels": [8, 32, 64],
|
| 87 |
+
"num_class_embeds": 128,
|
| 88 |
+
"resblock_updown": true,
|
| 89 |
+
"include_fc": true
|
| 90 |
+
},
|
| 91 |
+
"mask_generation_autoencoder_def": {
|
| 92 |
+
"_target_": "monai.apps.generation.maisi.networks.autoencoderkl_maisi.AutoencoderKlMaisi",
|
| 93 |
+
"spatial_dims": "@spatial_dims",
|
| 94 |
+
"in_channels": 8,
|
| 95 |
+
"out_channels": 125,
|
| 96 |
+
"latent_channels": "@latent_channels",
|
| 97 |
+
"num_channels": [
|
| 98 |
+
32,
|
| 99 |
+
64,
|
| 100 |
+
128
|
| 101 |
+
],
|
| 102 |
+
"num_res_blocks": [1, 2, 2],
|
| 103 |
+
"norm_num_groups": 32,
|
| 104 |
+
"norm_eps": 1e-06,
|
| 105 |
+
"attention_levels": [
|
| 106 |
+
false,
|
| 107 |
+
false,
|
| 108 |
+
false
|
| 109 |
+
],
|
| 110 |
+
"with_encoder_nonlocal_attn": false,
|
| 111 |
+
"with_decoder_nonlocal_attn": false,
|
| 112 |
+
"use_flash_attention": false,
|
| 113 |
+
"use_checkpointing": true,
|
| 114 |
+
"use_convtranspose": true,
|
| 115 |
+
"norm_float16": true,
|
| 116 |
+
"num_splits": 8,
|
| 117 |
+
"dim_split": 1
|
| 118 |
+
},
|
| 119 |
+
"mask_generation_diffusion_def": {
|
| 120 |
+
"_target_": "monai.networks.nets.diffusion_model_unet.DiffusionModelUNet",
|
| 121 |
+
"spatial_dims": "@spatial_dims",
|
| 122 |
+
"in_channels": "@latent_channels",
|
| 123 |
+
"out_channels": "@latent_channels",
|
| 124 |
+
"channels":[64, 128, 256, 512],
|
| 125 |
+
"attention_levels":[false, false, true, true],
|
| 126 |
+
"num_head_channels":[0, 0, 32, 32],
|
| 127 |
+
"num_res_blocks": 2,
|
| 128 |
+
"use_flash_attention": true,
|
| 129 |
+
"with_conditioning": true,
|
| 130 |
+
"upcast_attention": true,
|
| 131 |
+
"cross_attention_dim": 10
|
| 132 |
+
},
|
| 133 |
+
"mask_generation_scale_factor": 1.0055984258651733,
|
| 134 |
+
"noise_scheduler": {
|
| 135 |
+
"_target_": "monai.networks.schedulers.rectified_flow.RFlowScheduler",
|
| 136 |
+
"num_train_timesteps": 1000,
|
| 137 |
+
"use_discrete_timesteps": false,
|
| 138 |
+
"use_timestep_transform": true,
|
| 139 |
+
"sample_method": "uniform",
|
| 140 |
+
"scale":1.4
|
| 141 |
+
},
|
| 142 |
+
"mask_generation_noise_scheduler": {
|
| 143 |
+
"_target_": "monai.networks.schedulers.ddpm.DDPMScheduler",
|
| 144 |
+
"num_train_timesteps": 1000,
|
| 145 |
+
"beta_start": 0.0015,
|
| 146 |
+
"beta_end": 0.0195,
|
| 147 |
+
"schedule": "scaled_linear_beta",
|
| 148 |
+
"clip_sample": false
|
| 149 |
+
}
|
| 150 |
+
}
|
configs/infr_config_NoMAISI_controlnet.json
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"controlnet_train": {
|
| 3 |
+
"batch_size": 2,
|
| 4 |
+
"cache_rate": 0.0,
|
| 5 |
+
"fold": 1,
|
| 6 |
+
"lr": 1e-5,
|
| 7 |
+
"n_epochs": 500,
|
| 8 |
+
"weighted_loss_label": [23],
|
| 9 |
+
"weighted_loss": 100
|
| 10 |
+
},
|
| 11 |
+
"controlnet_infer": {
|
| 12 |
+
"num_inference_steps": 30,
|
| 13 |
+
"autoencoder_sliding_window_infer_size": [80, 80, 64],
|
| 14 |
+
"autoencoder_sliding_window_infer_overlap": 0.25,
|
| 15 |
+
"modality": 1
|
| 16 |
+
}
|
| 17 |
+
}
|
configs/infr_env_NoMAISI_DLCSD24_demo.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_dir": "./models/",
|
| 3 |
+
"output_dir": "./outputs/NoMAISI_DLCSD24_demo_512xy_256z_771p25m",
|
| 4 |
+
"tfevent_path": "./outputs/tfevent",
|
| 5 |
+
"trained_autoencoder_path": "./models/autoencoder.pt",
|
| 6 |
+
"trained_diffusion_path": "./models/diffusion_unet.pt",
|
| 7 |
+
"trained_controlnet_path": "./models/Experiments_NoMAISI_512xy_256z_771p25m_finetune_500epoch_best.pt",
|
| 8 |
+
"exp_name": "NoMAISI_DLCSD24_demo_512xy_256z_771p25m",
|
| 9 |
+
"data_base_dir": ["/home/ft42/NoMAISI/data"],
|
| 10 |
+
"json_data_list": ["/home/ft42/NoMAISI/data/infr_NoMAISI_DLCSD24_demo_512xy_256z_771p25m_dataset.json"]
|
| 11 |
+
}
|
data/DLCS_1419_seg_sh.nii.gz
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83da8dbf3b165023f3ffcec571fe5766177b65aabfa143f3a0bef5be41af757b
|
| 3 |
+
size 2265286
|
data/infr_NoMAISI_DLCSD24_demo_512xy_256z_771p25m_dataset.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name": "NoMAISI_DLCSD24_demo_512xy_256z_771p25m",
|
| 3 |
+
"numTest": 1,
|
| 4 |
+
"testing": [
|
| 5 |
+
{
|
| 6 |
+
|
| 7 |
+
"label": "DLCS_1419_seg_sh.nii.gz",
|
| 8 |
+
"fold": 0,
|
| 9 |
+
"dim": [
|
| 10 |
+
512,
|
| 11 |
+
512,
|
| 12 |
+
256
|
| 13 |
+
],
|
| 14 |
+
"spacing": [
|
| 15 |
+
0.703125,
|
| 16 |
+
0.703125,
|
| 17 |
+
1.25
|
| 18 |
+
],
|
| 19 |
+
"top_region_index": [
|
| 20 |
+
0,
|
| 21 |
+
1,
|
| 22 |
+
0,
|
| 23 |
+
0
|
| 24 |
+
],
|
| 25 |
+
"bottom_region_index": [
|
| 26 |
+
0,
|
| 27 |
+
0,
|
| 28 |
+
1,
|
| 29 |
+
0
|
| 30 |
+
]
|
| 31 |
+
}]
|
| 32 |
+
}
|
doc/images/DLCS_1419_ann0_slice134_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1419_ann1_slice204_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1443_ann1_slice125_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1446_ann0_slice122_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1447_ann0_slice206_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1453_ann0_slice204_triple.png
ADDED
|
Git LFS Details
|
doc/images/DLCS_1508_ann0_slice46_triple.png
ADDED

|
Git LFS Details
|
doc/images/DLCS_1519_ann3_slice155_triple.png
ADDED

|
Git LFS Details
|
doc/images/GanAI_fid_scatter_marker_legend.png
ADDED

|
Git LFS Details
|
doc/images/NoMAISI_train_and_infer.png
ADDED

|
Git LFS Details
|
doc/images/TaskCls.png
ADDED

|
Git LFS Details
|
doc/images/workflow.png
ADDED

|
Git LFS Details
|
inference.sub
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
#SBATCH --job-name=nomaisi
|
| 4 |
+
#SBATCH --mail-type=END,FAIL
|
| 5 |
+
#SBATCH --mail-user=ft42@duke.edu
|
| 6 |
+
#SBATCH -p vram48
|
| 7 |
+
#SBATCH --ntasks=1 #
|
| 8 |
+
#SBATCH --gpus=1 # 2 GPU per task, chose more if model is capable of multi gpu training
|
| 9 |
+
#SBATCH --cpus-per-task=16 # More if it is CPU intensive job too NNUNET demands lot of CPU
|
| 10 |
+
|
| 11 |
+
## Make sure logs directory is present on current directory (same as this script)
|
| 12 |
+
#SBATCH --output=logs/NoMAISI-infr-log-%j.out
|
| 13 |
+
#SBATCH --error=logs/NoMAISI-infr-log-%j.out
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
echo "Job starting"
|
| 18 |
+
echo "GPUs Given: $CUDA_VISIBLE_DEVICES"
|
| 19 |
+
module load miniconda/py39_4.12.0
|
| 20 |
+
source activate monai-auto3dseg
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Add the correct path to PYTHONPATH
|
| 24 |
+
export MONAI_DATA_DIRECTORY=/home/ft42/NoMAISI/
|
| 25 |
+
|
| 26 |
+
python -m scripts.infer_testV2_controlnet -c ./configs/config_maisi3d-rflow.json -e ./configs/infr_env_NoMAISI_DLCSD24_demo.json -t ./configs/infr_config_NoMAISI_controlnet.json
|
logs/NoMAISI-infr-log-38612.out
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 0 |
0%| | 0/30 [00:00<?, ?it/s]
|
| 1 |
3%|▎ | 1/30 [00:00<00:23, 1.22it/s]
|
| 2 |
7%|▋ | 2/30 [00:01<00:14, 1.93it/s]
|
| 3 |
10%|█ | 3/30 [00:01<00:12, 2.17it/s]
|
| 4 |
13%|█▎ | 4/30 [00:01<00:11, 2.30it/s]
|
| 5 |
17%|█▋ | 5/30 [00:02<00:10, 2.39it/s]
|
| 6 |
20%|██ | 6/30 [00:02<00:09, 2.44it/s]
|
| 7 |
23%|██▎ | 7/30 [00:03<00:09, 2.47it/s]
|
| 8 |
27%|██▋ | 8/30 [00:03<00:08, 2.49it/s]
|
| 9 |
30%|███ | 9/30 [00:03<00:08, 2.51it/s]
|
| 10 |
33%|███▎ | 10/30 [00:04<00:07, 2.52it/s]
|
| 11 |
37%|███▋ | 11/30 [00:04<00:07, 2.53it/s]
|
| 12 |
40%|████ | 12/30 [00:05<00:07, 2.53it/s]
|
| 13 |
43%|████▎ | 13/30 [00:05<00:06, 2.53it/s]
|
| 14 |
47%|████▋ | 14/30 [00:05<00:06, 2.54it/s]
|
| 15 |
50%|█████ | 15/30 [00:06<00:05, 2.54it/s]
|
| 16 |
53%|█████▎ | 16/30 [00:06<00:05, 2.54it/s]
|
| 17 |
57%|█████▋ | 17/30 [00:07<00:05, 2.54it/s]
|
| 18 |
60%|██████ | 18/30 [00:07<00:04, 2.54it/s]
|
| 19 |
63%|██████▎ | 19/30 [00:07<00:04, 2.54it/s]
|
| 20 |
67%|██████▋ | 20/30 [00:08<00:03, 2.54it/s]
|
| 21 |
70%|███████ | 21/30 [00:08<00:03, 2.54it/s]
|
| 22 |
73%|███████▎ | 22/30 [00:08<00:03, 2.54it/s]
|
| 23 |
77%|███████▋ | 23/30 [00:09<00:02, 2.53it/s]
|
| 24 |
80%|████████ | 24/30 [00:09<00:02, 2.54it/s]
|
| 25 |
83%|████████▎ | 25/30 [00:10<00:01, 2.53it/s]
|
| 26 |
87%|████████▋ | 26/30 [00:10<00:01, 2.53it/s]
|
| 27 |
90%|█████████ | 27/30 [00:10<00:01, 2.53it/s]
|
| 28 |
93%|█████████▎| 28/30 [00:11<00:00, 2.53it/s]
|
| 29 |
97%|█████████▋| 29/30 [00:11<00:00, 2.53it/s]
|
|
|
|
|
|
|
|
|
|
| 30 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 31 |
25%|██▌ | 1/4 [00:04<00:13, 4.36s/it]
|
| 32 |
50%|█████ | 2/4 [00:08<00:07, 4.00s/it]
|
| 33 |
75%|███████▌ | 3/4 [00:11<00:03, 3.79s/it]
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Job starting
|
| 2 |
+
GPUs Given: 0
|
| 3 |
+
[2025-09-24 13:42:58.511][ INFO](maisi.controlnet.infer) - Number of GPUs: 1
|
| 4 |
+
[2025-09-24 13:42:58.512][ INFO](maisi.controlnet.infer) - World_size: 1
|
| 5 |
+
[2025-09-24 13:42:59.541][ INFO](maisi.controlnet.infer) - Load trained diffusion model from ./models/autoencoder.pt.
|
| 6 |
+
[2025-09-24 13:43:03.285][ INFO](maisi.controlnet.infer) - Load trained diffusion model from ./models/diffusion_unet.pt.
|
| 7 |
+
[2025-09-24 13:43:03.287][ INFO](maisi.controlnet.infer) - loaded scale_factor from diffusion model ckpt -> 1.0311251878738403.
|
| 8 |
+
2025-09-24 13:43:03,824 - INFO - 'dst' model updated: 180 of 231 variables.
|
| 9 |
+
[2025-09-24 13:43:04.077][ INFO](maisi.controlnet.infer) - load trained controlnet model from ./models/Experiments_NoMAISI_512xy_256z_771p25m_finetune_500epoch_best.pt
|
| 10 |
+
[2025-09-24 13:43:07.130][ INFO](root) - `controllable_anatomy_size` is not provided.
|
| 11 |
+
[2025-09-24 13:43:07.133][ INFO](root) - ---- Start generating latent features... ----
|
| 12 |
+
|
| 13 |
0%| | 0/30 [00:00<?, ?it/s]
|
| 14 |
3%|▎ | 1/30 [00:00<00:23, 1.22it/s]
|
| 15 |
7%|▋ | 2/30 [00:01<00:14, 1.93it/s]
|
| 16 |
10%|█ | 3/30 [00:01<00:12, 2.17it/s]
|
| 17 |
13%|█▎ | 4/30 [00:01<00:11, 2.30it/s]
|
| 18 |
17%|█▋ | 5/30 [00:02<00:10, 2.39it/s]
|
| 19 |
20%|██ | 6/30 [00:02<00:09, 2.44it/s]
|
| 20 |
23%|██▎ | 7/30 [00:03<00:09, 2.47it/s]
|
| 21 |
27%|██▋ | 8/30 [00:03<00:08, 2.49it/s]
|
| 22 |
30%|███ | 9/30 [00:03<00:08, 2.51it/s]
|
| 23 |
33%|███▎ | 10/30 [00:04<00:07, 2.52it/s]
|
| 24 |
37%|███▋ | 11/30 [00:04<00:07, 2.53it/s]
|
| 25 |
40%|████ | 12/30 [00:05<00:07, 2.53it/s]
|
| 26 |
43%|████▎ | 13/30 [00:05<00:06, 2.53it/s]
|
| 27 |
47%|████▋ | 14/30 [00:05<00:06, 2.54it/s]
|
| 28 |
50%|█████ | 15/30 [00:06<00:05, 2.54it/s]
|
| 29 |
53%|█████▎ | 16/30 [00:06<00:05, 2.54it/s]
|
| 30 |
57%|█████▋ | 17/30 [00:07<00:05, 2.54it/s]
|
| 31 |
60%|██████ | 18/30 [00:07<00:04, 2.54it/s]
|
| 32 |
63%|██████▎ | 19/30 [00:07<00:04, 2.54it/s]
|
| 33 |
67%|██████▋ | 20/30 [00:08<00:03, 2.54it/s]
|
| 34 |
70%|███████ | 21/30 [00:08<00:03, 2.54it/s]
|
| 35 |
73%|███████▎ | 22/30 [00:08<00:03, 2.54it/s]
|
| 36 |
77%|███████▋ | 23/30 [00:09<00:02, 2.53it/s]
|
| 37 |
80%|████████ | 24/30 [00:09<00:02, 2.54it/s]
|
| 38 |
83%|████████▎ | 25/30 [00:10<00:01, 2.53it/s]
|
| 39 |
87%|████████▋ | 26/30 [00:10<00:01, 2.53it/s]
|
| 40 |
90%|█████████ | 27/30 [00:10<00:01, 2.53it/s]
|
| 41 |
93%|█████████▎| 28/30 [00:11<00:00, 2.53it/s]
|
| 42 |
97%|█████████▋| 29/30 [00:11<00:00, 2.53it/s]
|
| 43 |
+
[2025-09-24 13:43:19.446][ INFO](root) - ---- DM/ControlNet Latent features generation time: 12.313125371932983 seconds ----
|
| 44 |
+
[2025-09-24 13:43:20.016][ INFO](root) - ---- Start decoding latent features into images... ----
|
| 45 |
+
|
| 46 |
0%| | 0/4 [00:00<?, ?it/s]
|
| 47 |
25%|██▌ | 1/4 [00:04<00:13, 4.36s/it]
|
| 48 |
50%|█████ | 2/4 [00:08<00:07, 4.00s/it]
|
| 49 |
75%|███████▌ | 3/4 [00:11<00:03, 3.79s/it]
|
| 50 |
+
[2025-09-24 13:43:35.252][ INFO](root) - ---- Image VAE decoding time: 15.23531699180603 seconds ----
|
| 51 |
+
2025-09-24 13:43:37,053 INFO image_writer.py:197 - writing: outputs/NoMAISI_DLCSD24_demo_512xy_256z_771p25m/DLCS_1419_seg_sh_image.nii.gz
|
| 52 |
+
2025-09-24 13:43:41,437 INFO image_writer.py:197 - writing: outputs/NoMAISI_DLCSD24_demo_512xy_256z_771p25m/DLCS_1419_seg_sh_label.nii.gz
|
scripts/__init__.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# You may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
scripts/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (140 Bytes). View file
|
|
|
scripts/__pycache__/augmentation.cpython-310.pyc
ADDED
|
Binary file (6.81 kB). View file
|
|
|
scripts/__pycache__/diff_model_create_training_data.cpython-310.pyc
ADDED
|
Binary file (7.38 kB). View file
|
|
|
scripts/__pycache__/diff_model_setting.cpython-310.pyc
ADDED
|
Binary file (2.47 kB). View file
|
|
|
scripts/__pycache__/find_masks.cpython-310.pyc
ADDED
|
Binary file (4.48 kB). View file
|
|
|
scripts/__pycache__/infer_controlnet.cpython-310.pyc
ADDED
|
Binary file (5.72 kB). View file
|
|
|
scripts/__pycache__/infer_testV2_controlnet.cpython-310.pyc
ADDED
|
Binary file (5.76 kB). View file
|
|
|
scripts/__pycache__/infer_test_controlnet.cpython-310.pyc
ADDED
|
Binary file (5.75 kB). View file
|
|
|
scripts/__pycache__/inference.cpython-310.pyc
ADDED
|
Binary file (7.62 kB). View file
|
|
|
scripts/__pycache__/quality_check.cpython-310.pyc
ADDED
|
Binary file (4.39 kB). View file
|
|
|
scripts/__pycache__/rectified_flow.cpython-310.pyc
ADDED
|
Binary file (10.9 kB). View file
|
|
|
scripts/__pycache__/sample.cpython-310.pyc
ADDED
|
Binary file (31.4 kB). View file
|
|
|
scripts/__pycache__/train_controlnet.cpython-310.pyc
ADDED
|
Binary file (8.01 kB). View file
|
|
|
scripts/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (26.5 kB). View file
|
|
|
scripts/__pycache__/utils_plot.cpython-310.pyc
ADDED
|
Binary file (6.66 kB). View file
|
|
|
scripts/augmentation.py
ADDED
|
@@ -0,0 +1,373 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from monai.transforms import Rand3DElastic, RandAffine, RandZoom
|
| 16 |
+
from monai.utils import ensure_tuple_rep
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def erode3d(input_tensor, erosion=3):
|
| 20 |
+
# Define the structuring element
|
| 21 |
+
erosion = ensure_tuple_rep(erosion, 3)
|
| 22 |
+
structuring_element = torch.ones(1, 1, erosion[0], erosion[1], erosion[2]).to(input_tensor.device)
|
| 23 |
+
|
| 24 |
+
# Pad the input tensor to handle border pixels
|
| 25 |
+
input_padded = F.pad(
|
| 26 |
+
input_tensor.float().unsqueeze(0).unsqueeze(0),
|
| 27 |
+
(erosion[0] // 2, erosion[0] // 2, erosion[1] // 2, erosion[1] // 2, erosion[2] // 2, erosion[2] // 2),
|
| 28 |
+
mode="constant",
|
| 29 |
+
value=1.0,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
# Apply erosion operation
|
| 33 |
+
output = F.conv3d(input_padded, structuring_element, padding=0)
|
| 34 |
+
|
| 35 |
+
# Set output values based on the minimum value within the structuring element
|
| 36 |
+
output = torch.where(output == torch.sum(structuring_element), 1.0, 0.0)
|
| 37 |
+
|
| 38 |
+
return output.squeeze(0).squeeze(0)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def dilate3d(input_tensor, erosion=3):
|
| 42 |
+
# Define the structuring element
|
| 43 |
+
erosion = ensure_tuple_rep(erosion, 3)
|
| 44 |
+
structuring_element = torch.ones(1, 1, erosion[0], erosion[1], erosion[2]).to(input_tensor.device)
|
| 45 |
+
|
| 46 |
+
# Pad the input tensor to handle border pixels
|
| 47 |
+
input_padded = F.pad(
|
| 48 |
+
input_tensor.float().unsqueeze(0).unsqueeze(0),
|
| 49 |
+
(erosion[0] // 2, erosion[0] // 2, erosion[1] // 2, erosion[1] // 2, erosion[2] // 2, erosion[2] // 2),
|
| 50 |
+
mode="constant",
|
| 51 |
+
value=1.0,
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
# Apply erosion operation
|
| 55 |
+
output = F.conv3d(input_padded, structuring_element, padding=0)
|
| 56 |
+
|
| 57 |
+
# Set output values based on the minimum value within the structuring element
|
| 58 |
+
output = torch.where(output > 0, 1.0, 0.0)
|
| 59 |
+
|
| 60 |
+
return output.squeeze(0).squeeze(0)
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def augmentation_tumor_bone(pt_nda, output_size, random_seed=None):
|
| 64 |
+
volume = pt_nda.squeeze(0)
|
| 65 |
+
real_l_volume_ = torch.zeros_like(volume)
|
| 66 |
+
real_l_volume_[volume == 128] = 1
|
| 67 |
+
real_l_volume_ = real_l_volume_.to(torch.uint8)
|
| 68 |
+
|
| 69 |
+
elastic = RandAffine(
|
| 70 |
+
mode="nearest",
|
| 71 |
+
prob=1.0,
|
| 72 |
+
translate_range=(5, 5, 0),
|
| 73 |
+
rotate_range=(0, 0, 0.1),
|
| 74 |
+
scale_range=(0.15, 0.15, 0),
|
| 75 |
+
padding_mode="zeros",
|
| 76 |
+
)
|
| 77 |
+
elastic.set_random_state(seed=random_seed)
|
| 78 |
+
|
| 79 |
+
tumor_szie = torch.sum((real_l_volume_ > 0).float())
|
| 80 |
+
###########################
|
| 81 |
+
# remove pred in pseudo_label in real lesion region
|
| 82 |
+
volume[real_l_volume_ > 0] = 200
|
| 83 |
+
###########################
|
| 84 |
+
if tumor_szie > 0:
|
| 85 |
+
# get organ mask
|
| 86 |
+
organ_mask = (
|
| 87 |
+
torch.logical_and(33 <= volume, volume <= 56).float()
|
| 88 |
+
+ torch.logical_and(63 <= volume, volume <= 97).float()
|
| 89 |
+
+ (volume == 127).float()
|
| 90 |
+
+ (volume == 114).float()
|
| 91 |
+
+ real_l_volume_
|
| 92 |
+
)
|
| 93 |
+
organ_mask = (organ_mask > 0).float()
|
| 94 |
+
cnt = 0
|
| 95 |
+
while True:
|
| 96 |
+
threshold = 0.8 if cnt < 40 else 0.75
|
| 97 |
+
real_l_volume = real_l_volume_
|
| 98 |
+
# random distor mask
|
| 99 |
+
distored_mask = elastic((real_l_volume > 0).cuda(), spatial_size=tuple(output_size)).as_tensor()
|
| 100 |
+
real_l_volume = distored_mask * organ_mask
|
| 101 |
+
cnt += 1
|
| 102 |
+
print(torch.sum(real_l_volume), "|", tumor_szie * threshold)
|
| 103 |
+
if torch.sum(real_l_volume) >= tumor_szie * threshold:
|
| 104 |
+
real_l_volume = dilate3d(real_l_volume.squeeze(0), erosion=5)
|
| 105 |
+
real_l_volume = erode3d(real_l_volume, erosion=5).unsqueeze(0).to(torch.uint8)
|
| 106 |
+
break
|
| 107 |
+
else:
|
| 108 |
+
real_l_volume = real_l_volume_
|
| 109 |
+
|
| 110 |
+
volume[real_l_volume == 1] = 128
|
| 111 |
+
|
| 112 |
+
pt_nda = volume.unsqueeze(0)
|
| 113 |
+
return pt_nda
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def augmentation_tumor_liver(pt_nda, output_size, random_seed=None):
|
| 117 |
+
volume = pt_nda.squeeze(0)
|
| 118 |
+
real_l_volume_ = torch.zeros_like(volume)
|
| 119 |
+
real_l_volume_[volume == 1] = 1
|
| 120 |
+
real_l_volume_[volume == 26] = 2
|
| 121 |
+
real_l_volume_ = real_l_volume_.to(torch.uint8)
|
| 122 |
+
|
| 123 |
+
elastic = Rand3DElastic(
|
| 124 |
+
mode="nearest",
|
| 125 |
+
prob=1.0,
|
| 126 |
+
sigma_range=(5, 8),
|
| 127 |
+
magnitude_range=(100, 200),
|
| 128 |
+
translate_range=(10, 10, 10),
|
| 129 |
+
rotate_range=(np.pi / 36, np.pi / 36, np.pi / 36),
|
| 130 |
+
scale_range=(0.2, 0.2, 0.2),
|
| 131 |
+
padding_mode="zeros",
|
| 132 |
+
)
|
| 133 |
+
elastic.set_random_state(seed=random_seed)
|
| 134 |
+
|
| 135 |
+
tumor_szie = torch.sum(real_l_volume_ == 2)
|
| 136 |
+
###########################
|
| 137 |
+
# remove pred organ labels
|
| 138 |
+
volume[volume == 1] = 0
|
| 139 |
+
volume[volume == 26] = 0
|
| 140 |
+
# before move tumor maks, full the original location by organ labels
|
| 141 |
+
volume[real_l_volume_ == 1] = 1
|
| 142 |
+
volume[real_l_volume_ == 2] = 1
|
| 143 |
+
###########################
|
| 144 |
+
while True:
|
| 145 |
+
real_l_volume = real_l_volume_
|
| 146 |
+
# random distor mask
|
| 147 |
+
real_l_volume = elastic((real_l_volume == 2).cuda(), spatial_size=tuple(output_size)).as_tensor()
|
| 148 |
+
# get organ mask
|
| 149 |
+
organ_mask = (real_l_volume_ == 1).float() + (real_l_volume_ == 2).float()
|
| 150 |
+
|
| 151 |
+
organ_mask = dilate3d(organ_mask.squeeze(0), erosion=5)
|
| 152 |
+
organ_mask = erode3d(organ_mask, erosion=5).unsqueeze(0)
|
| 153 |
+
real_l_volume = real_l_volume * organ_mask
|
| 154 |
+
print(torch.sum(real_l_volume), "|", tumor_szie * 0.80)
|
| 155 |
+
if torch.sum(real_l_volume) >= tumor_szie * 0.80:
|
| 156 |
+
real_l_volume = dilate3d(real_l_volume.squeeze(0), erosion=5)
|
| 157 |
+
real_l_volume = erode3d(real_l_volume, erosion=5).unsqueeze(0)
|
| 158 |
+
break
|
| 159 |
+
|
| 160 |
+
volume[real_l_volume == 1] = 26
|
| 161 |
+
|
| 162 |
+
pt_nda = volume.unsqueeze(0)
|
| 163 |
+
return pt_nda
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def augmentation_tumor_lung(pt_nda, output_size, random_seed=None):
|
| 167 |
+
volume = pt_nda.squeeze(0)
|
| 168 |
+
real_l_volume_ = torch.zeros_like(volume)
|
| 169 |
+
real_l_volume_[volume == 23] = 1
|
| 170 |
+
real_l_volume_ = real_l_volume_.to(torch.uint8)
|
| 171 |
+
|
| 172 |
+
elastic = Rand3DElastic(
|
| 173 |
+
mode="nearest",
|
| 174 |
+
prob=1.0,
|
| 175 |
+
sigma_range=(5, 8),
|
| 176 |
+
magnitude_range=(100, 200),
|
| 177 |
+
translate_range=(20, 20, 20),
|
| 178 |
+
rotate_range=(np.pi / 36, np.pi / 36, np.pi),
|
| 179 |
+
scale_range=(0.15, 0.15, 0.15),
|
| 180 |
+
padding_mode="zeros",
|
| 181 |
+
)
|
| 182 |
+
elastic.set_random_state(seed=random_seed)
|
| 183 |
+
|
| 184 |
+
tumor_szie = torch.sum(real_l_volume_)
|
| 185 |
+
# before move lung tumor maks, full the original location by lung labels
|
| 186 |
+
new_real_l_volume_ = dilate3d(real_l_volume_.squeeze(0), erosion=3)
|
| 187 |
+
new_real_l_volume_ = new_real_l_volume_.unsqueeze(0)
|
| 188 |
+
new_real_l_volume_[real_l_volume_ > 0] = 0
|
| 189 |
+
new_real_l_volume_[volume < 28] = 0
|
| 190 |
+
new_real_l_volume_[volume > 32] = 0
|
| 191 |
+
tmp = volume[(volume * new_real_l_volume_).nonzero(as_tuple=True)].view(-1)
|
| 192 |
+
|
| 193 |
+
mode = torch.mode(tmp, 0)[0].item()
|
| 194 |
+
print(mode)
|
| 195 |
+
assert 28 <= mode <= 32
|
| 196 |
+
volume[real_l_volume_.bool()] = mode
|
| 197 |
+
###########################
|
| 198 |
+
if tumor_szie > 0:
|
| 199 |
+
# aug
|
| 200 |
+
while True:
|
| 201 |
+
real_l_volume = real_l_volume_
|
| 202 |
+
# random distor mask
|
| 203 |
+
real_l_volume = elastic(real_l_volume, spatial_size=tuple(output_size)).as_tensor()
|
| 204 |
+
# get lung mask v2 (133 order)
|
| 205 |
+
lung_mask = (
|
| 206 |
+
(volume == 28).float()
|
| 207 |
+
+ (volume == 29).float()
|
| 208 |
+
+ (volume == 30).float()
|
| 209 |
+
+ (volume == 31).float()
|
| 210 |
+
+ (volume == 32).float()
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
lung_mask = dilate3d(lung_mask.squeeze(0), erosion=5)
|
| 214 |
+
lung_mask = erode3d(lung_mask, erosion=5).unsqueeze(0)
|
| 215 |
+
real_l_volume = real_l_volume * lung_mask
|
| 216 |
+
print(torch.sum(real_l_volume), "|", tumor_szie * 0.85)
|
| 217 |
+
if torch.sum(real_l_volume) >= tumor_szie * 0.85:
|
| 218 |
+
real_l_volume = dilate3d(real_l_volume.squeeze(0), erosion=5)
|
| 219 |
+
real_l_volume = erode3d(real_l_volume, erosion=5).unsqueeze(0).to(torch.uint8)
|
| 220 |
+
break
|
| 221 |
+
else:
|
| 222 |
+
real_l_volume = real_l_volume_
|
| 223 |
+
|
| 224 |
+
volume[real_l_volume == 1] = 23
|
| 225 |
+
|
| 226 |
+
pt_nda = volume.unsqueeze(0)
|
| 227 |
+
return pt_nda
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
def augmentation_tumor_pancreas(pt_nda, output_size, random_seed=None):
|
| 231 |
+
volume = pt_nda.squeeze(0)
|
| 232 |
+
real_l_volume_ = torch.zeros_like(volume)
|
| 233 |
+
real_l_volume_[volume == 4] = 1
|
| 234 |
+
real_l_volume_[volume == 24] = 2
|
| 235 |
+
real_l_volume_ = real_l_volume_.to(torch.uint8)
|
| 236 |
+
|
| 237 |
+
elastic = Rand3DElastic(
|
| 238 |
+
mode="nearest",
|
| 239 |
+
prob=1.0,
|
| 240 |
+
sigma_range=(5, 8),
|
| 241 |
+
magnitude_range=(100, 200),
|
| 242 |
+
translate_range=(15, 15, 15),
|
| 243 |
+
rotate_range=(np.pi / 36, np.pi / 36, np.pi / 36),
|
| 244 |
+
scale_range=(0.1, 0.1, 0.1),
|
| 245 |
+
padding_mode="zeros",
|
| 246 |
+
)
|
| 247 |
+
elastic.set_random_state(seed=random_seed)
|
| 248 |
+
|
| 249 |
+
tumor_szie = torch.sum(real_l_volume_ == 2)
|
| 250 |
+
###########################
|
| 251 |
+
# remove pred organ labels
|
| 252 |
+
volume[volume == 24] = 0
|
| 253 |
+
volume[volume == 4] = 0
|
| 254 |
+
# before move tumor maks, full the original location by organ labels
|
| 255 |
+
volume[real_l_volume_ == 1] = 4
|
| 256 |
+
volume[real_l_volume_ == 2] = 4
|
| 257 |
+
###########################
|
| 258 |
+
while True:
|
| 259 |
+
real_l_volume = real_l_volume_
|
| 260 |
+
# random distor mask
|
| 261 |
+
real_l_volume = elastic((real_l_volume == 2).cuda(), spatial_size=tuple(output_size)).as_tensor()
|
| 262 |
+
# get organ mask
|
| 263 |
+
organ_mask = (real_l_volume_ == 1).float() + (real_l_volume_ == 2).float()
|
| 264 |
+
|
| 265 |
+
organ_mask = dilate3d(organ_mask.squeeze(0), erosion=5)
|
| 266 |
+
organ_mask = erode3d(organ_mask, erosion=5).unsqueeze(0)
|
| 267 |
+
real_l_volume = real_l_volume * organ_mask
|
| 268 |
+
print(torch.sum(real_l_volume), "|", tumor_szie * 0.80)
|
| 269 |
+
if torch.sum(real_l_volume) >= tumor_szie * 0.80:
|
| 270 |
+
real_l_volume = dilate3d(real_l_volume.squeeze(0), erosion=5)
|
| 271 |
+
real_l_volume = erode3d(real_l_volume, erosion=5).unsqueeze(0)
|
| 272 |
+
break
|
| 273 |
+
|
| 274 |
+
volume[real_l_volume == 1] = 24
|
| 275 |
+
|
| 276 |
+
pt_nda = volume.unsqueeze(0)
|
| 277 |
+
return pt_nda
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
def augmentation_tumor_colon(pt_nda, output_size, random_seed=None):
|
| 281 |
+
volume = pt_nda.squeeze(0)
|
| 282 |
+
real_l_volume_ = torch.zeros_like(volume)
|
| 283 |
+
real_l_volume_[volume == 27] = 1
|
| 284 |
+
real_l_volume_ = real_l_volume_.to(torch.uint8)
|
| 285 |
+
|
| 286 |
+
elastic = Rand3DElastic(
|
| 287 |
+
mode="nearest",
|
| 288 |
+
prob=1.0,
|
| 289 |
+
sigma_range=(5, 8),
|
| 290 |
+
magnitude_range=(100, 200),
|
| 291 |
+
translate_range=(5, 5, 5),
|
| 292 |
+
rotate_range=(np.pi / 36, np.pi / 36, np.pi / 36),
|
| 293 |
+
scale_range=(0.1, 0.1, 0.1),
|
| 294 |
+
padding_mode="zeros",
|
| 295 |
+
)
|
| 296 |
+
elastic.set_random_state(seed=random_seed)
|
| 297 |
+
|
| 298 |
+
tumor_szie = torch.sum(real_l_volume_)
|
| 299 |
+
###########################
|
| 300 |
+
# before move tumor maks, full the original location by organ labels
|
| 301 |
+
volume[real_l_volume_.bool()] = 62
|
| 302 |
+
###########################
|
| 303 |
+
if tumor_szie > 0:
|
| 304 |
+
# get organ mask
|
| 305 |
+
organ_mask = (volume == 62).float()
|
| 306 |
+
organ_mask = dilate3d(organ_mask.squeeze(0), erosion=5)
|
| 307 |
+
organ_mask = erode3d(organ_mask, erosion=5).unsqueeze(0)
|
| 308 |
+
# cnt = 0
|
| 309 |
+
cnt = 0
|
| 310 |
+
while True:
|
| 311 |
+
threshold = 0.8
|
| 312 |
+
real_l_volume = real_l_volume_
|
| 313 |
+
if cnt < 20:
|
| 314 |
+
# random distor mask
|
| 315 |
+
distored_mask = elastic((real_l_volume == 1).cuda(), spatial_size=tuple(output_size)).as_tensor()
|
| 316 |
+
real_l_volume = distored_mask * organ_mask
|
| 317 |
+
elif 20 <= cnt < 40:
|
| 318 |
+
threshold = 0.75
|
| 319 |
+
else:
|
| 320 |
+
break
|
| 321 |
+
|
| 322 |
+
real_l_volume = real_l_volume * organ_mask
|
| 323 |
+
print(torch.sum(real_l_volume), "|", tumor_szie * threshold)
|
| 324 |
+
cnt += 1
|
| 325 |
+
if torch.sum(real_l_volume) >= tumor_szie * threshold:
|
| 326 |
+
real_l_volume = dilate3d(real_l_volume.squeeze(0), erosion=5)
|
| 327 |
+
real_l_volume = erode3d(real_l_volume, erosion=5).unsqueeze(0).to(torch.uint8)
|
| 328 |
+
break
|
| 329 |
+
else:
|
| 330 |
+
real_l_volume = real_l_volume_
|
| 331 |
+
# break
|
| 332 |
+
volume[real_l_volume == 1] = 27
|
| 333 |
+
|
| 334 |
+
pt_nda = volume.unsqueeze(0)
|
| 335 |
+
return pt_nda
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
def augmentation_body(pt_nda, random_seed=None):
|
| 339 |
+
volume = pt_nda.squeeze(0)
|
| 340 |
+
|
| 341 |
+
zoom = RandZoom(min_zoom=0.99, max_zoom=1.01, mode="nearest", align_corners=None, prob=1.0)
|
| 342 |
+
zoom.set_random_state(seed=random_seed)
|
| 343 |
+
|
| 344 |
+
volume = zoom(volume)
|
| 345 |
+
|
| 346 |
+
pt_nda = volume.unsqueeze(0)
|
| 347 |
+
return pt_nda
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
def augmentation(pt_nda, output_size, random_seed=None):
|
| 351 |
+
label_list = torch.unique(pt_nda)
|
| 352 |
+
label_list = list(label_list.cpu().numpy())
|
| 353 |
+
|
| 354 |
+
if 128 in label_list:
|
| 355 |
+
print("augmenting bone lesion/tumor")
|
| 356 |
+
pt_nda = augmentation_tumor_bone(pt_nda, output_size, random_seed)
|
| 357 |
+
elif 26 in label_list:
|
| 358 |
+
print("augmenting liver tumor")
|
| 359 |
+
pt_nda = augmentation_tumor_liver(pt_nda, output_size, random_seed)
|
| 360 |
+
elif 23 in label_list:
|
| 361 |
+
print("augmenting lung tumor")
|
| 362 |
+
pt_nda = augmentation_tumor_lung(pt_nda, output_size, random_seed)
|
| 363 |
+
elif 24 in label_list:
|
| 364 |
+
print("augmenting pancreas tumor")
|
| 365 |
+
pt_nda = augmentation_tumor_pancreas(pt_nda, output_size, random_seed)
|
| 366 |
+
elif 27 in label_list:
|
| 367 |
+
print("augmenting colon tumor")
|
| 368 |
+
pt_nda = augmentation_tumor_colon(pt_nda, output_size, random_seed)
|
| 369 |
+
else:
|
| 370 |
+
print("augmenting body")
|
| 371 |
+
pt_nda = augmentation_body(pt_nda, random_seed)
|
| 372 |
+
|
| 373 |
+
return pt_nda
|
scripts/compute_fid_2-5d_ct.py
ADDED
|
@@ -0,0 +1,747 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at:
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
#
|
| 7 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 8 |
+
# distributed under the License is distributed on an
|
| 9 |
+
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,
|
| 10 |
+
# either express or implied.
|
| 11 |
+
# See the License for the specific language governing permissions
|
| 12 |
+
# and limitations under the License.
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
Compute 2.5D FID using distributed GPU processing.
|
| 16 |
+
|
| 17 |
+
SHELL Usage Example:
|
| 18 |
+
-------------------
|
| 19 |
+
#!/bin/bash
|
| 20 |
+
|
| 21 |
+
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6
|
| 22 |
+
NUM_GPUS=7
|
| 23 |
+
|
| 24 |
+
torchrun --nproc_per_node=${NUM_GPUS} compute_fid_2-5d_ct.py \
|
| 25 |
+
--model_name "radimagenet_resnet50" \
|
| 26 |
+
--real_dataset_root "path/to/datasetA" \
|
| 27 |
+
--real_filelist "path/to/filelistA.txt" \
|
| 28 |
+
--real_features_dir "datasetA" \
|
| 29 |
+
--synth_dataset_root "path/to/datasetB" \
|
| 30 |
+
--synth_filelist "path/to/filelistB.txt" \
|
| 31 |
+
--synth_features_dir "datasetB" \
|
| 32 |
+
--enable_center_slices_ratio 0.4 \
|
| 33 |
+
--enable_padding True \
|
| 34 |
+
--enable_center_cropping True \
|
| 35 |
+
--enable_resampling_spacing "1.0x1.0x1.0" \
|
| 36 |
+
--ignore_existing True \
|
| 37 |
+
--num_images 100 \
|
| 38 |
+
--output_root "./features/features-512x512x512" \
|
| 39 |
+
--target_shape "512x512x512"
|
| 40 |
+
|
| 41 |
+
This script loads two datasets (real vs. synthetic) in 3D medical format (NIfTI)
|
| 42 |
+
and extracts feature maps via a 2.5D approach. It then computes the Frechet
|
| 43 |
+
Inception Distance (FID) across three orthogonal planes. Data parallelism
|
| 44 |
+
is implemented using torch.distributed with an NCCL backend.
|
| 45 |
+
|
| 46 |
+
Function Arguments (main):
|
| 47 |
+
--------------------------
|
| 48 |
+
real_dataset_root (str):
|
| 49 |
+
Root folder for the real dataset.
|
| 50 |
+
|
| 51 |
+
real_filelist (str):
|
| 52 |
+
Text file listing 3D images for the real dataset.
|
| 53 |
+
|
| 54 |
+
real_features_dir (str):
|
| 55 |
+
Subdirectory (under `output_root`) in which to store feature files
|
| 56 |
+
extracted from the real dataset.
|
| 57 |
+
|
| 58 |
+
synth_dataset_root (str):
|
| 59 |
+
Root folder for the synthetic dataset.
|
| 60 |
+
|
| 61 |
+
synth_filelist (str):
|
| 62 |
+
Text file listing 3D images for the synthetic dataset.
|
| 63 |
+
|
| 64 |
+
synth_features_dir (str):
|
| 65 |
+
Subdirectory (under `output_root`) in which to store feature files
|
| 66 |
+
extracted from the synthetic dataset.
|
| 67 |
+
|
| 68 |
+
enable_center_slices_ratio (float or None):
|
| 69 |
+
- If not None, only slices around the specified center ratio will be used
|
| 70 |
+
(analogous to "enable_center_slices=True" with that ratio).
|
| 71 |
+
- If None, no center-slice selection is performed
|
| 72 |
+
(analogous to "enable_center_slices=False").
|
| 73 |
+
|
| 74 |
+
enable_padding (bool):
|
| 75 |
+
Whether to pad images to `target_shape`.
|
| 76 |
+
|
| 77 |
+
enable_center_cropping (bool):
|
| 78 |
+
Whether to center-crop images to `target_shape`.
|
| 79 |
+
|
| 80 |
+
enable_resampling_spacing (str or None):
|
| 81 |
+
- If not None, resample images to the specified voxel spacing (e.g. "1.0x1.0x1.0")
|
| 82 |
+
(analogous to "enable_resampling=True" with that spacing).
|
| 83 |
+
- If None, resampling is skipped
|
| 84 |
+
(analogous to "enable_resampling=False").
|
| 85 |
+
|
| 86 |
+
ignore_existing (bool):
|
| 87 |
+
If True, ignore any existing .pt feature files and force re-extraction.
|
| 88 |
+
|
| 89 |
+
model_name (str):
|
| 90 |
+
Model identifier. Typically "radimagenet_resnet50" or "squeezenet1_1".
|
| 91 |
+
|
| 92 |
+
num_images (int):
|
| 93 |
+
Max number of images to process from each dataset (truncate if more are present).
|
| 94 |
+
|
| 95 |
+
output_root (str):
|
| 96 |
+
Folder where extracted .pt feature files, logs, and results are saved.
|
| 97 |
+
|
| 98 |
+
target_shape (str):
|
| 99 |
+
Target shape as "XxYxZ" for padding, cropping, or resampling operations.
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
from __future__ import annotations
|
| 104 |
+
|
| 105 |
+
import os
|
| 106 |
+
import sys
|
| 107 |
+
import torch
|
| 108 |
+
import fire
|
| 109 |
+
import monai
|
| 110 |
+
import re
|
| 111 |
+
import torch.distributed as dist
|
| 112 |
+
import torch.nn.functional as F
|
| 113 |
+
|
| 114 |
+
from datetime import timedelta
|
| 115 |
+
from pathlib import Path
|
| 116 |
+
from monai.metrics.fid import FIDMetric
|
| 117 |
+
from monai.transforms import Compose
|
| 118 |
+
|
| 119 |
+
import logging
|
| 120 |
+
|
| 121 |
+
# ------------------------------------------------------------------------------
|
| 122 |
+
# Create logger
|
| 123 |
+
# ------------------------------------------------------------------------------
|
| 124 |
+
logger = logging.getLogger("fid_2-5d_ct")
|
| 125 |
+
if not logger.handlers:
|
| 126 |
+
# Configure logger only if it has no handlers (avoid reconfiguring in multi-rank scenarios)
|
| 127 |
+
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
|
| 128 |
+
logger.setLevel(logging.INFO)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def drop_empty_slice(slices, empty_threshold: float):
|
| 132 |
+
"""
|
| 133 |
+
Decide which 2D slices to keep by checking if their maximum intensity
|
| 134 |
+
is below a certain threshold.
|
| 135 |
+
|
| 136 |
+
Args:
|
| 137 |
+
slices (tuple or list of Tensors): Each element is (B, C, H, W).
|
| 138 |
+
empty_threshold (float): If the slice's maximum value is below this threshold,
|
| 139 |
+
it is considered "empty".
|
| 140 |
+
|
| 141 |
+
Returns:
|
| 142 |
+
list[bool]: A list of booleans indicating for each slice whether to keep it.
|
| 143 |
+
"""
|
| 144 |
+
outputs = []
|
| 145 |
+
n_drop = 0
|
| 146 |
+
for s in slices:
|
| 147 |
+
largest_unique = torch.max(torch.unique(s))
|
| 148 |
+
if largest_unique < empty_threshold:
|
| 149 |
+
outputs.append(False)
|
| 150 |
+
n_drop += 1
|
| 151 |
+
else:
|
| 152 |
+
outputs.append(True)
|
| 153 |
+
|
| 154 |
+
logger.info(f"Empty slice drop rate {round((n_drop/len(slices))*100,1)}%")
|
| 155 |
+
return outputs
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def subtract_mean(x: torch.Tensor) -> torch.Tensor:
|
| 159 |
+
"""
|
| 160 |
+
Subtract per-channel means (ImageNet-like: [0.406, 0.456, 0.485])
|
| 161 |
+
from the input 4D or 5D tensor. Expects channels in the first dimension
|
| 162 |
+
after the batch dimension: (B, C, H, W) or (B, C, H, W, D).
|
| 163 |
+
"""
|
| 164 |
+
mean = [0.406, 0.456, 0.485]
|
| 165 |
+
x[:, 0, ...] -= mean[0]
|
| 166 |
+
x[:, 1, ...] -= mean[1]
|
| 167 |
+
x[:, 2, ...] -= mean[2]
|
| 168 |
+
return x
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def spatial_average(x: torch.Tensor, keepdim: bool = True) -> torch.Tensor:
|
| 172 |
+
"""
|
| 173 |
+
Average out the spatial dimensions of a tensor, preserving or removing them
|
| 174 |
+
according to `keepdim`. This is used to produce a 1D feature vector
|
| 175 |
+
out of a feature map.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
x (torch.Tensor): Input tensor (B, C, H, W, ...) or (B, C, H, W).
|
| 179 |
+
keepdim (bool): Whether to keep dimension or not after averaging.
|
| 180 |
+
|
| 181 |
+
Returns:
|
| 182 |
+
torch.Tensor: Tensor with reduced spatial dimensions.
|
| 183 |
+
"""
|
| 184 |
+
dim = len(x.shape)
|
| 185 |
+
# 2D -> no average
|
| 186 |
+
if dim == 2:
|
| 187 |
+
return x
|
| 188 |
+
# 3D -> average over last dim
|
| 189 |
+
if dim == 3:
|
| 190 |
+
return x.mean([2], keepdim=keepdim)
|
| 191 |
+
# 4D -> average over H,W
|
| 192 |
+
if dim == 4:
|
| 193 |
+
return x.mean([2, 3], keepdim=keepdim)
|
| 194 |
+
# 5D -> average over H,W,D
|
| 195 |
+
if dim == 5:
|
| 196 |
+
return x.mean([2, 3, 4], keepdim=keepdim)
|
| 197 |
+
return x
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def medicalnet_intensity_normalisation(volume: torch.Tensor) -> torch.Tensor:
|
| 201 |
+
"""
|
| 202 |
+
Intensity normalization approach from MedicalNet:
|
| 203 |
+
(volume - mean) / (std + 1e-5) across spatial dims.
|
| 204 |
+
Expects (B, C, H, W) or (B, C, H, W, D).
|
| 205 |
+
"""
|
| 206 |
+
dim = len(volume.shape)
|
| 207 |
+
if dim == 4:
|
| 208 |
+
mean = volume.mean([2, 3], keepdim=True)
|
| 209 |
+
std = volume.std([2, 3], keepdim=True)
|
| 210 |
+
elif dim == 5:
|
| 211 |
+
mean = volume.mean([2, 3, 4], keepdim=True)
|
| 212 |
+
std = volume.std([2, 3, 4], keepdim=True)
|
| 213 |
+
else:
|
| 214 |
+
return volume
|
| 215 |
+
return (volume - mean) / (std + 1e-5)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def radimagenet_intensity_normalisation(volume: torch.Tensor, norm2d: bool = False) -> torch.Tensor:
|
| 219 |
+
"""
|
| 220 |
+
Intensity normalization for radimagenet_resnet. Optionally normalizes each 2D slice individually.
|
| 221 |
+
|
| 222 |
+
Args:
|
| 223 |
+
volume (torch.Tensor): Input (B, C, H, W) or (B, C, H, W, D).
|
| 224 |
+
norm2d (bool): If True, normalizes each (H,W) slice to [0,1], then subtracts the ImageNet mean.
|
| 225 |
+
"""
|
| 226 |
+
logger.info(f"norm2d: {norm2d}")
|
| 227 |
+
dim = len(volume.shape)
|
| 228 |
+
# If norm2d is True, only meaningful for 4D data (B, C, H, W):
|
| 229 |
+
if dim == 4 and norm2d:
|
| 230 |
+
max2d, _ = torch.max(volume, dim=2, keepdim=True)
|
| 231 |
+
max2d, _ = torch.max(max2d, dim=3, keepdim=True)
|
| 232 |
+
min2d, _ = torch.min(volume, dim=2, keepdim=True)
|
| 233 |
+
min2d, _ = torch.min(min2d, dim=3, keepdim=True)
|
| 234 |
+
# Scale each slice to 0..1
|
| 235 |
+
volume = (volume - min2d) / (max2d - min2d + 1e-10)
|
| 236 |
+
# Subtract channel mean
|
| 237 |
+
return subtract_mean(volume)
|
| 238 |
+
elif dim == 4:
|
| 239 |
+
# 4D but no per-slice normalization
|
| 240 |
+
max3d = torch.max(volume)
|
| 241 |
+
min3d = torch.min(volume)
|
| 242 |
+
volume = (volume - min3d) / (max3d - min3d + 1e-10)
|
| 243 |
+
return subtract_mean(volume)
|
| 244 |
+
# Fallback for e.g. 5D data is simply a min-max over entire volume
|
| 245 |
+
if dim == 5:
|
| 246 |
+
maxval = torch.max(volume)
|
| 247 |
+
minval = torch.min(volume)
|
| 248 |
+
volume = (volume - minval) / (maxval - minval + 1e-10)
|
| 249 |
+
return subtract_mean(volume)
|
| 250 |
+
return volume
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
def get_features_2p5d(
|
| 254 |
+
image: torch.Tensor,
|
| 255 |
+
feature_network: torch.nn.Module,
|
| 256 |
+
center_slices: bool = False,
|
| 257 |
+
center_slices_ratio: float = 1.0,
|
| 258 |
+
sample_every_k: int = 1,
|
| 259 |
+
xy_only: bool = True,
|
| 260 |
+
drop_empty: bool = False,
|
| 261 |
+
empty_threshold: float = -700,
|
| 262 |
+
) -> tuple[torch.Tensor | None, torch.Tensor | None, torch.Tensor | None]:
|
| 263 |
+
"""
|
| 264 |
+
Extract 2.5D features from a 3D image by slicing it along XY, YZ, ZX planes.
|
| 265 |
+
|
| 266 |
+
Args:
|
| 267 |
+
image (torch.Tensor): Input 5D tensor in shape (B, C, H, W, D).
|
| 268 |
+
feature_network (torch.nn.Module): Model that processes 2D slices (C,H,W).
|
| 269 |
+
center_slices (bool): Whether to slice only the center portion of each axis.
|
| 270 |
+
center_slices_ratio (float): Ratio of slices to keep in the center if `center_slices` is True.
|
| 271 |
+
sample_every_k (int): Downsampling factor along each axis when slicing.
|
| 272 |
+
xy_only (bool): If True, return only the XY-plane features.
|
| 273 |
+
drop_empty (bool): Drop slices that are deemed "empty" below `empty_threshold`.
|
| 274 |
+
empty_threshold (float): Threshold to decide emptiness of slices.
|
| 275 |
+
|
| 276 |
+
Returns:
|
| 277 |
+
tuple of torch.Tensor or None: (XY_features, YZ_features, ZX_features).
|
| 278 |
+
"""
|
| 279 |
+
logger.info(f"center_slices: {center_slices}, ratio: {center_slices_ratio}")
|
| 280 |
+
|
| 281 |
+
# If there's only 1 channel, replicate to 3 channels
|
| 282 |
+
if image.shape[1] == 1:
|
| 283 |
+
image = image.repeat(1, 3, 1, 1, 1)
|
| 284 |
+
|
| 285 |
+
# Convert from 'RGB'→(R,G,B) to (B,G,R)
|
| 286 |
+
image = image[:, [2, 1, 0], ...]
|
| 287 |
+
|
| 288 |
+
B, C, H, W, D = image.size()
|
| 289 |
+
with torch.no_grad():
|
| 290 |
+
# ---------------------- XY-plane slicing along D ----------------------
|
| 291 |
+
if center_slices:
|
| 292 |
+
start_d = int((1.0 - center_slices_ratio) / 2.0 * D)
|
| 293 |
+
end_d = int((1.0 + center_slices_ratio) / 2.0 * D)
|
| 294 |
+
slices = torch.unbind(image[:, :, :, :, start_d:end_d:sample_every_k], dim=-1)
|
| 295 |
+
else:
|
| 296 |
+
slices = torch.unbind(image, dim=-1)
|
| 297 |
+
|
| 298 |
+
if drop_empty:
|
| 299 |
+
mapping_index = drop_empty_slice(slices, empty_threshold)
|
| 300 |
+
else:
|
| 301 |
+
mapping_index = [True for _ in range(len(slices))]
|
| 302 |
+
|
| 303 |
+
images_2d = torch.cat(slices, dim=0)
|
| 304 |
+
images_2d = radimagenet_intensity_normalisation(images_2d)
|
| 305 |
+
images_2d = images_2d[mapping_index]
|
| 306 |
+
|
| 307 |
+
feature_image_xy = feature_network.forward(images_2d)
|
| 308 |
+
feature_image_xy = spatial_average(feature_image_xy, keepdim=False)
|
| 309 |
+
if xy_only:
|
| 310 |
+
return feature_image_xy, None, None
|
| 311 |
+
|
| 312 |
+
# ---------------------- YZ-plane slicing along H ----------------------
|
| 313 |
+
if center_slices:
|
| 314 |
+
start_h = int((1.0 - center_slices_ratio) / 2.0 * H)
|
| 315 |
+
end_h = int((1.0 + center_slices_ratio) / 2.0 * H)
|
| 316 |
+
slices = torch.unbind(image[:, :, start_h:end_h:sample_every_k, :, :], dim=2)
|
| 317 |
+
else:
|
| 318 |
+
slices = torch.unbind(image, dim=2)
|
| 319 |
+
|
| 320 |
+
if drop_empty:
|
| 321 |
+
mapping_index = drop_empty_slice(slices, empty_threshold)
|
| 322 |
+
else:
|
| 323 |
+
mapping_index = [True for _ in range(len(slices))]
|
| 324 |
+
|
| 325 |
+
images_2d = torch.cat(slices, dim=0)
|
| 326 |
+
images_2d = radimagenet_intensity_normalisation(images_2d)
|
| 327 |
+
images_2d = images_2d[mapping_index]
|
| 328 |
+
|
| 329 |
+
feature_image_yz = feature_network.forward(images_2d)
|
| 330 |
+
feature_image_yz = spatial_average(feature_image_yz, keepdim=False)
|
| 331 |
+
|
| 332 |
+
# ---------------------- ZX-plane slicing along W ----------------------
|
| 333 |
+
if center_slices:
|
| 334 |
+
start_w = int((1.0 - center_slices_ratio) / 2.0 * W)
|
| 335 |
+
end_w = int((1.0 + center_slices_ratio) / 2.0 * W)
|
| 336 |
+
slices = torch.unbind(image[:, :, :, start_w:end_w:sample_every_k, :], dim=3)
|
| 337 |
+
else:
|
| 338 |
+
slices = torch.unbind(image, dim=3)
|
| 339 |
+
|
| 340 |
+
if drop_empty:
|
| 341 |
+
mapping_index = drop_empty_slice(slices, empty_threshold)
|
| 342 |
+
else:
|
| 343 |
+
mapping_index = [True for _ in range(len(slices))]
|
| 344 |
+
|
| 345 |
+
images_2d = torch.cat(slices, dim=0)
|
| 346 |
+
images_2d = radimagenet_intensity_normalisation(images_2d)
|
| 347 |
+
images_2d = images_2d[mapping_index]
|
| 348 |
+
|
| 349 |
+
feature_image_zx = feature_network.forward(images_2d)
|
| 350 |
+
feature_image_zx = spatial_average(feature_image_zx, keepdim=False)
|
| 351 |
+
|
| 352 |
+
return feature_image_xy, feature_image_yz, feature_image_zx
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
def pad_to_max_size(tensor: torch.Tensor, max_size: int, padding_value: float = 0.0) -> torch.Tensor:
|
| 356 |
+
"""
|
| 357 |
+
Zero-pad a 2D feature map or other tensor along the first dimension to match a specified size.
|
| 358 |
+
|
| 359 |
+
Args:
|
| 360 |
+
tensor (torch.Tensor): The feature tensor to pad.
|
| 361 |
+
max_size (int): Desired size along the first dimension.
|
| 362 |
+
padding_value (float): Value to fill during padding.
|
| 363 |
+
|
| 364 |
+
Returns:
|
| 365 |
+
torch.Tensor: Padded tensor matching `max_size` along dim=0.
|
| 366 |
+
"""
|
| 367 |
+
pad_size = [0, 0] * (len(tensor.shape) - 1) + [0, max_size - tensor.shape[0]]
|
| 368 |
+
return F.pad(tensor, pad_size, "constant", padding_value)
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
def main(
|
| 372 |
+
real_dataset_root: str = "path/to/datasetA",
|
| 373 |
+
real_filelist: str = "path/to/filelistA.txt",
|
| 374 |
+
real_features_dir: str = "datasetA",
|
| 375 |
+
synth_dataset_root: str = "path/to/datasetB",
|
| 376 |
+
synth_filelist: str = "path/to/filelistB.txt",
|
| 377 |
+
synth_features_dir: str = "datasetB",
|
| 378 |
+
enable_center_slices_ratio: float = None,
|
| 379 |
+
enable_padding: bool = True,
|
| 380 |
+
enable_center_cropping: bool = True,
|
| 381 |
+
enable_resampling_spacing: str = None,
|
| 382 |
+
ignore_existing: bool = False,
|
| 383 |
+
model_name: str = "radimagenet_resnet50",
|
| 384 |
+
num_images: int = 100,
|
| 385 |
+
output_root: str = "./features/features-512x512x512",
|
| 386 |
+
target_shape: str = "512x512x512",
|
| 387 |
+
):
|
| 388 |
+
"""
|
| 389 |
+
Compute 2.5D FID using distributed GPU processing.
|
| 390 |
+
|
| 391 |
+
This function loads two datasets (real vs. synthetic) in 3D medical format (NIfTI)
|
| 392 |
+
and extracts feature maps via a 2.5D approach, then computes the Frechet Inception
|
| 393 |
+
Distance (FID) across three orthogonal planes. Data parallelism is implemented
|
| 394 |
+
using torch.distributed with an NCCL backend.
|
| 395 |
+
|
| 396 |
+
Args:
|
| 397 |
+
real_dataset_root (str):
|
| 398 |
+
Root folder for the real dataset.
|
| 399 |
+
real_filelist (str):
|
| 400 |
+
Path to a text file listing 3D images (e.g., NIfTI files) for the real dataset.
|
| 401 |
+
Each line in this file should contain a relative path (or filename) to a NIfTI file.
|
| 402 |
+
For example, your "real_filelist.txt" could look like:
|
| 403 |
+
case001.nii.gz
|
| 404 |
+
case002.nii.gz
|
| 405 |
+
case003.nii.gz
|
| 406 |
+
...
|
| 407 |
+
These entries will be appended to `real_dataset_root`.
|
| 408 |
+
real_features_dir (str):
|
| 409 |
+
Name of the directory under `output_root` in which to store
|
| 410 |
+
extracted features for the real dataset.
|
| 411 |
+
|
| 412 |
+
synth_dataset_root (str):
|
| 413 |
+
Root folder for the synthetic dataset.
|
| 414 |
+
synth_filelist (str):
|
| 415 |
+
Path to a text file listing 3D images (e.g., NIfTI files) for the synthetic dataset.
|
| 416 |
+
The format is the same as the real dataset file list, for example:
|
| 417 |
+
synth_case001.nii.gz
|
| 418 |
+
synth_case002.nii.gz
|
| 419 |
+
synth_case003.nii.gz
|
| 420 |
+
...
|
| 421 |
+
These entries will be appended to `synth_dataset_root`.
|
| 422 |
+
synth_features_dir (str):
|
| 423 |
+
Name of the directory under `output_root` in which to store
|
| 424 |
+
extracted features for the synthetic dataset.
|
| 425 |
+
|
| 426 |
+
enable_center_slices_ratio (float or None):
|
| 427 |
+
- If not None, only slices around the specified center ratio are used.
|
| 428 |
+
(similar to "enable_center_slices=True" with that ratio in an earlier script).
|
| 429 |
+
- If None, no center-slice selection is performed
|
| 430 |
+
(similar to "enable_center_slices=False").
|
| 431 |
+
|
| 432 |
+
enable_padding (bool):
|
| 433 |
+
Whether to pad images to `target_shape`.
|
| 434 |
+
|
| 435 |
+
enable_center_cropping (bool):
|
| 436 |
+
Whether to center-crop images to `target_shape`.
|
| 437 |
+
|
| 438 |
+
enable_resampling_spacing (str or None):
|
| 439 |
+
- If not None, resample images to this voxel spacing (e.g. "1.0x1.0x1.0")
|
| 440 |
+
(similar to "enable_resampling=True" with that spacing).
|
| 441 |
+
- If None, skip resampling (similar to "enable_resampling=False").
|
| 442 |
+
|
| 443 |
+
ignore_existing (bool):
|
| 444 |
+
If True, ignore any existing .pt feature files and force re-computation.
|
| 445 |
+
|
| 446 |
+
model_name (str):
|
| 447 |
+
Model identifier. Typically "radimagenet_resnet50" or "squeezenet1_1".
|
| 448 |
+
|
| 449 |
+
num_images (int):
|
| 450 |
+
Maximum number of images to load from each dataset (truncate if more are present).
|
| 451 |
+
|
| 452 |
+
output_root (str):
|
| 453 |
+
Parent folder where extracted .pt files and logs will be saved.
|
| 454 |
+
|
| 455 |
+
target_shape (str):
|
| 456 |
+
Target shape, e.g. "512x512x512", for padding, cropping, or resampling operations.
|
| 457 |
+
|
| 458 |
+
Returns:
|
| 459 |
+
None
|
| 460 |
+
"""
|
| 461 |
+
# -------------------------------------------------------------------------
|
| 462 |
+
# Initialize Process Group (Distributed)
|
| 463 |
+
# -------------------------------------------------------------------------
|
| 464 |
+
dist.init_process_group(backend="nccl", init_method="env://", timeout=timedelta(seconds=7200))
|
| 465 |
+
|
| 466 |
+
local_rank = int(os.environ["LOCAL_RANK"])
|
| 467 |
+
world_size = int(dist.get_world_size())
|
| 468 |
+
device = torch.device("cuda", local_rank)
|
| 469 |
+
torch.cuda.set_device(device)
|
| 470 |
+
logger.info(f"[INFO] Running process on {device} of total {world_size} ranks.")
|
| 471 |
+
|
| 472 |
+
# Convert potential string bools to actual bools (if using Fire or similar)
|
| 473 |
+
if not isinstance(enable_padding, bool):
|
| 474 |
+
enable_padding = enable_padding.lower() == "true"
|
| 475 |
+
if not isinstance(enable_center_cropping, bool):
|
| 476 |
+
enable_center_cropping = enable_center_cropping.lower() == "true"
|
| 477 |
+
if not isinstance(ignore_existing, bool):
|
| 478 |
+
ignore_existing = ignore_existing.lower() == "true"
|
| 479 |
+
|
| 480 |
+
# Merge logic for center slices
|
| 481 |
+
enable_center_slices = enable_center_slices_ratio is not None
|
| 482 |
+
|
| 483 |
+
# Merge logic for resampling
|
| 484 |
+
enable_resampling = enable_resampling_spacing is not None
|
| 485 |
+
|
| 486 |
+
# Print out some flags on rank 0
|
| 487 |
+
if local_rank == 0:
|
| 488 |
+
logger.info(f"Real dataset root: {real_dataset_root}")
|
| 489 |
+
logger.info(f"Synth dataset root: {synth_dataset_root}")
|
| 490 |
+
logger.info(f"enable_center_slices_ratio: {enable_center_slices_ratio}")
|
| 491 |
+
logger.info(f"enable_center_slices: {enable_center_slices}")
|
| 492 |
+
logger.info(f"enable_padding: {enable_padding}")
|
| 493 |
+
logger.info(f"enable_center_cropping: {enable_center_cropping}")
|
| 494 |
+
logger.info(f"enable_resampling_spacing: {enable_resampling_spacing}")
|
| 495 |
+
logger.info(f"enable_resampling: {enable_resampling}")
|
| 496 |
+
logger.info(f"ignore_existing: {ignore_existing}")
|
| 497 |
+
|
| 498 |
+
# -------------------------------------------------------------------------
|
| 499 |
+
# Load feature extraction model
|
| 500 |
+
# -------------------------------------------------------------------------
|
| 501 |
+
if model_name == "radimagenet_resnet50":
|
| 502 |
+
feature_network = torch.hub.load(
|
| 503 |
+
"Warvito/radimagenet-models", model="radimagenet_resnet50", verbose=True, trust_repo=True
|
| 504 |
+
)
|
| 505 |
+
suffix = "radimagenet_resnet50"
|
| 506 |
+
else:
|
| 507 |
+
import torchvision
|
| 508 |
+
|
| 509 |
+
feature_network = torchvision.models.squeezenet1_1(pretrained=True)
|
| 510 |
+
suffix = "squeezenet1_1"
|
| 511 |
+
|
| 512 |
+
feature_network.to(device)
|
| 513 |
+
feature_network.eval()
|
| 514 |
+
|
| 515 |
+
# -------------------------------------------------------------------------
|
| 516 |
+
# Parse shape/spacings
|
| 517 |
+
# -------------------------------------------------------------------------
|
| 518 |
+
t_shape = [int(x) for x in target_shape.split("x")]
|
| 519 |
+
target_shape_tuple = tuple(t_shape)
|
| 520 |
+
|
| 521 |
+
# If not None, parse the resampling spacing
|
| 522 |
+
if enable_resampling:
|
| 523 |
+
rs_spacing = [float(x) for x in enable_resampling_spacing.split("x")]
|
| 524 |
+
rs_spacing_tuple = tuple(rs_spacing)
|
| 525 |
+
if local_rank == 0:
|
| 526 |
+
logger.info(f"Resampling spacing: {rs_spacing_tuple}")
|
| 527 |
+
else:
|
| 528 |
+
rs_spacing_tuple = (1.0, 1.0, 1.0)
|
| 529 |
+
|
| 530 |
+
# Use the ratio if provided, otherwise 1.0
|
| 531 |
+
center_slices_ratio_final = enable_center_slices_ratio if enable_center_slices else 1.0
|
| 532 |
+
if local_rank == 0:
|
| 533 |
+
logger.info(f"center_slices_ratio: {center_slices_ratio_final}")
|
| 534 |
+
|
| 535 |
+
# -------------------------------------------------------------------------
|
| 536 |
+
# Prepare Real Dataset
|
| 537 |
+
# -------------------------------------------------------------------------
|
| 538 |
+
output_root_real = os.path.join(output_root, real_features_dir)
|
| 539 |
+
with open(real_filelist, "r") as rf:
|
| 540 |
+
real_lines = [l.strip() for l in rf.readlines()]
|
| 541 |
+
real_lines.sort()
|
| 542 |
+
real_lines = real_lines[:num_images]
|
| 543 |
+
|
| 544 |
+
real_filenames = [{"image": os.path.join(real_dataset_root, f)} for f in real_lines]
|
| 545 |
+
real_filenames = monai.data.partition_dataset(
|
| 546 |
+
data=real_filenames, shuffle=False, num_partitions=world_size, even_divisible=False
|
| 547 |
+
)[local_rank]
|
| 548 |
+
|
| 549 |
+
# -------------------------------------------------------------------------
|
| 550 |
+
# Prepare Synthetic Dataset
|
| 551 |
+
# -------------------------------------------------------------------------
|
| 552 |
+
output_root_synth = os.path.join(output_root, synth_features_dir)
|
| 553 |
+
with open(synth_filelist, "r") as sf:
|
| 554 |
+
synth_lines = [l.strip() for l in sf.readlines()]
|
| 555 |
+
synth_lines.sort()
|
| 556 |
+
synth_lines = synth_lines[:num_images]
|
| 557 |
+
|
| 558 |
+
synth_filenames = [{"image": os.path.join(synth_dataset_root, f)} for f in synth_lines]
|
| 559 |
+
synth_filenames = monai.data.partition_dataset(
|
| 560 |
+
data=synth_filenames, shuffle=False, num_partitions=world_size, even_divisible=False
|
| 561 |
+
)[local_rank]
|
| 562 |
+
|
| 563 |
+
# -------------------------------------------------------------------------
|
| 564 |
+
# Build MONAI transforms
|
| 565 |
+
# -------------------------------------------------------------------------
|
| 566 |
+
transform_list = [
|
| 567 |
+
monai.transforms.LoadImaged(keys=["image"]),
|
| 568 |
+
monai.transforms.EnsureChannelFirstd(keys=["image"]),
|
| 569 |
+
monai.transforms.Orientationd(keys=["image"], axcodes="RAS"),
|
| 570 |
+
]
|
| 571 |
+
|
| 572 |
+
if enable_resampling:
|
| 573 |
+
transform_list.append(monai.transforms.Spacingd(keys=["image"], pixdim=rs_spacing_tuple, mode=["bilinear"]))
|
| 574 |
+
|
| 575 |
+
if enable_padding:
|
| 576 |
+
transform_list.append(
|
| 577 |
+
monai.transforms.SpatialPadd(keys=["image"], spatial_size=target_shape_tuple, mode="constant", value=-1000)
|
| 578 |
+
)
|
| 579 |
+
|
| 580 |
+
if enable_center_cropping:
|
| 581 |
+
transform_list.append(monai.transforms.CenterSpatialCropd(keys=["image"], roi_size=target_shape_tuple))
|
| 582 |
+
|
| 583 |
+
transform_list.append(
|
| 584 |
+
monai.transforms.ScaleIntensityRanged(
|
| 585 |
+
keys=["image"], a_min=-1000, a_max=1000, b_min=-1000, b_max=1000, clip=True
|
| 586 |
+
)
|
| 587 |
+
)
|
| 588 |
+
transforms = Compose(transform_list)
|
| 589 |
+
|
| 590 |
+
# -------------------------------------------------------------------------
|
| 591 |
+
# Create DataLoaders
|
| 592 |
+
# -------------------------------------------------------------------------
|
| 593 |
+
real_ds = monai.data.Dataset(data=real_filenames, transform=transforms)
|
| 594 |
+
real_loader = monai.data.DataLoader(real_ds, num_workers=6, batch_size=1, shuffle=False)
|
| 595 |
+
|
| 596 |
+
synth_ds = monai.data.Dataset(data=synth_filenames, transform=transforms)
|
| 597 |
+
synth_loader = monai.data.DataLoader(synth_ds, num_workers=6, batch_size=1, shuffle=False)
|
| 598 |
+
|
| 599 |
+
# -------------------------------------------------------------------------
|
| 600 |
+
# Extract features for Real Dataset
|
| 601 |
+
# -------------------------------------------------------------------------
|
| 602 |
+
real_features_xy, real_features_yz, real_features_zx = [], [], []
|
| 603 |
+
for idx, batch_data in enumerate(real_loader, start=1):
|
| 604 |
+
img = batch_data["image"].to(device)
|
| 605 |
+
fn = img.meta["filename_or_obj"][0]
|
| 606 |
+
logger.info(f"[Rank {local_rank}] Real data {idx}/{len(real_filenames)}: {fn}")
|
| 607 |
+
|
| 608 |
+
out_fp = fn.replace(real_dataset_root, output_root_real).replace(".nii.gz", ".pt")
|
| 609 |
+
out_fp = Path(out_fp)
|
| 610 |
+
out_fp.parent.mkdir(parents=True, exist_ok=True)
|
| 611 |
+
|
| 612 |
+
if (not ignore_existing) and os.path.isfile(out_fp):
|
| 613 |
+
feats = torch.load(out_fp, weights_only=True)
|
| 614 |
+
else:
|
| 615 |
+
img_t = img.as_tensor()
|
| 616 |
+
logger.info(f"image shape: {tuple(img_t.shape)}")
|
| 617 |
+
|
| 618 |
+
feats = get_features_2p5d(
|
| 619 |
+
img_t,
|
| 620 |
+
feature_network,
|
| 621 |
+
center_slices=enable_center_slices,
|
| 622 |
+
center_slices_ratio=center_slices_ratio_final,
|
| 623 |
+
xy_only=False,
|
| 624 |
+
)
|
| 625 |
+
logger.info(f"feats shapes: {feats[0].shape}, {feats[1].shape}, {feats[2].shape}")
|
| 626 |
+
torch.save(feats, out_fp)
|
| 627 |
+
|
| 628 |
+
real_features_xy.append(feats[0])
|
| 629 |
+
real_features_yz.append(feats[1])
|
| 630 |
+
real_features_zx.append(feats[2])
|
| 631 |
+
|
| 632 |
+
real_features_xy = torch.vstack(real_features_xy)
|
| 633 |
+
real_features_yz = torch.vstack(real_features_yz)
|
| 634 |
+
real_features_zx = torch.vstack(real_features_zx)
|
| 635 |
+
logger.info(
|
| 636 |
+
f"Real feature shapes: {real_features_xy.shape}, " f"{real_features_yz.shape}, {real_features_zx.shape}"
|
| 637 |
+
)
|
| 638 |
+
|
| 639 |
+
# -------------------------------------------------------------------------
|
| 640 |
+
# Extract features for Synthetic Dataset
|
| 641 |
+
# -------------------------------------------------------------------------
|
| 642 |
+
synth_features_xy, synth_features_yz, synth_features_zx = [], [], []
|
| 643 |
+
for idx, batch_data in enumerate(synth_loader, start=1):
|
| 644 |
+
img = batch_data["image"].to(device)
|
| 645 |
+
fn = img.meta["filename_or_obj"][0]
|
| 646 |
+
logger.info(f"[Rank {local_rank}] Synth data {idx}/{len(synth_filenames)}: {fn}")
|
| 647 |
+
|
| 648 |
+
out_fp = fn.replace(synth_dataset_root, output_root_synth).replace(".nii.gz", ".pt")
|
| 649 |
+
out_fp = Path(out_fp)
|
| 650 |
+
out_fp.parent.mkdir(parents=True, exist_ok=True)
|
| 651 |
+
|
| 652 |
+
if (not ignore_existing) and os.path.isfile(out_fp):
|
| 653 |
+
feats = torch.load(out_fp, weights_only=True)
|
| 654 |
+
else:
|
| 655 |
+
img_t = img.as_tensor()
|
| 656 |
+
logger.info(f"image shape: {tuple(img_t.shape)}")
|
| 657 |
+
|
| 658 |
+
feats = get_features_2p5d(
|
| 659 |
+
img_t,
|
| 660 |
+
feature_network,
|
| 661 |
+
center_slices=enable_center_slices,
|
| 662 |
+
center_slices_ratio=center_slices_ratio_final,
|
| 663 |
+
xy_only=False,
|
| 664 |
+
)
|
| 665 |
+
logger.info(f"feats shapes: {feats[0].shape}, {feats[1].shape}, {feats[2].shape}")
|
| 666 |
+
torch.save(feats, out_fp)
|
| 667 |
+
|
| 668 |
+
synth_features_xy.append(feats[0])
|
| 669 |
+
synth_features_yz.append(feats[1])
|
| 670 |
+
synth_features_zx.append(feats[2])
|
| 671 |
+
|
| 672 |
+
synth_features_xy = torch.vstack(synth_features_xy)
|
| 673 |
+
synth_features_yz = torch.vstack(synth_features_yz)
|
| 674 |
+
synth_features_zx = torch.vstack(synth_features_zx)
|
| 675 |
+
logger.info(
|
| 676 |
+
f"Synth feature shapes: {synth_features_xy.shape}, " f"{synth_features_yz.shape}, {synth_features_zx.shape}"
|
| 677 |
+
)
|
| 678 |
+
|
| 679 |
+
# -------------------------------------------------------------------------
|
| 680 |
+
# All-reduce / gather features across ranks
|
| 681 |
+
# -------------------------------------------------------------------------
|
| 682 |
+
features = [
|
| 683 |
+
real_features_xy,
|
| 684 |
+
real_features_yz,
|
| 685 |
+
real_features_zx,
|
| 686 |
+
synth_features_xy,
|
| 687 |
+
synth_features_yz,
|
| 688 |
+
synth_features_zx,
|
| 689 |
+
]
|
| 690 |
+
|
| 691 |
+
# 1) Gather local feature sizes across ranks
|
| 692 |
+
local_sizes = []
|
| 693 |
+
for ft_idx in range(len(features)):
|
| 694 |
+
local_size = torch.tensor([features[ft_idx].shape[0]], dtype=torch.int64, device=device)
|
| 695 |
+
local_sizes.append(local_size)
|
| 696 |
+
|
| 697 |
+
all_sizes = []
|
| 698 |
+
for ft_idx in range(len(features)):
|
| 699 |
+
rank_sizes = [torch.tensor([0], dtype=torch.int64, device=device) for _ in range(world_size)]
|
| 700 |
+
dist.all_gather(rank_sizes, local_sizes[ft_idx])
|
| 701 |
+
all_sizes.append(rank_sizes)
|
| 702 |
+
|
| 703 |
+
# 2) Pad and gather all features
|
| 704 |
+
all_tensors_list = []
|
| 705 |
+
for ft_idx, ft in enumerate(features):
|
| 706 |
+
max_size = max(all_sizes[ft_idx]).item()
|
| 707 |
+
ft_padded = pad_to_max_size(ft, max_size)
|
| 708 |
+
|
| 709 |
+
gather_list = [torch.empty_like(ft_padded) for _ in range(world_size)]
|
| 710 |
+
dist.all_gather(gather_list, ft_padded)
|
| 711 |
+
|
| 712 |
+
# Trim each gather back to the real size
|
| 713 |
+
for rk in range(world_size):
|
| 714 |
+
gather_list[rk] = gather_list[rk][: all_sizes[ft_idx][rk], :]
|
| 715 |
+
|
| 716 |
+
all_tensors_list.append(gather_list)
|
| 717 |
+
|
| 718 |
+
# On rank 0, compute FID
|
| 719 |
+
if local_rank == 0:
|
| 720 |
+
real_xy = torch.vstack(all_tensors_list[0])
|
| 721 |
+
real_yz = torch.vstack(all_tensors_list[1])
|
| 722 |
+
real_zx = torch.vstack(all_tensors_list[2])
|
| 723 |
+
|
| 724 |
+
synth_xy = torch.vstack(all_tensors_list[3])
|
| 725 |
+
synth_yz = torch.vstack(all_tensors_list[4])
|
| 726 |
+
synth_zx = torch.vstack(all_tensors_list[5])
|
| 727 |
+
|
| 728 |
+
logger.info(f"Final Real shapes: {real_xy.shape}, {real_yz.shape}, {real_zx.shape}")
|
| 729 |
+
logger.info(f"Final Synth shapes: {synth_xy.shape}, {synth_yz.shape}, {synth_zx.shape}")
|
| 730 |
+
|
| 731 |
+
fid = FIDMetric()
|
| 732 |
+
logger.info(f"Computing FID for: {output_root_real} | {output_root_synth}")
|
| 733 |
+
fid_res_xy = fid(synth_xy, real_xy)
|
| 734 |
+
fid_res_yz = fid(synth_yz, real_yz)
|
| 735 |
+
fid_res_zx = fid(synth_zx, real_zx)
|
| 736 |
+
|
| 737 |
+
logger.info(f"FID XY: {fid_res_xy}")
|
| 738 |
+
logger.info(f"FID YZ: {fid_res_yz}")
|
| 739 |
+
logger.info(f"FID ZX: {fid_res_zx}")
|
| 740 |
+
fid_avg = (fid_res_xy + fid_res_yz + fid_res_zx) / 3.0
|
| 741 |
+
logger.info(f"FID Avg: {fid_avg}")
|
| 742 |
+
|
| 743 |
+
dist.destroy_process_group()
|
| 744 |
+
|
| 745 |
+
|
| 746 |
+
if __name__ == "__main__":
|
| 747 |
+
fire.Fire(main)
|
scripts/diff_model_create_training_data.py
ADDED
|
@@ -0,0 +1,231 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import json
|
| 16 |
+
import logging
|
| 17 |
+
import os
|
| 18 |
+
from pathlib import Path
|
| 19 |
+
|
| 20 |
+
import monai
|
| 21 |
+
import nibabel as nib
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
import torch.distributed as dist
|
| 25 |
+
from monai.transforms import Compose
|
| 26 |
+
from monai.utils import set_determinism
|
| 27 |
+
|
| 28 |
+
from .diff_model_setting import initialize_distributed, load_config, setup_logging
|
| 29 |
+
from .utils import define_instance
|
| 30 |
+
|
| 31 |
+
# Set the random seed for reproducibility
|
| 32 |
+
set_determinism(seed=0)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def create_transforms(dim: tuple = None) -> Compose:
|
| 36 |
+
"""
|
| 37 |
+
Create a set of MONAI transforms for preprocessing.
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
dim (tuple, optional): New dimensions for resizing. Defaults to None.
|
| 41 |
+
|
| 42 |
+
Returns:
|
| 43 |
+
Compose: Composed MONAI transforms.
|
| 44 |
+
"""
|
| 45 |
+
if dim:
|
| 46 |
+
return Compose(
|
| 47 |
+
[
|
| 48 |
+
monai.transforms.LoadImaged(keys="image"),
|
| 49 |
+
monai.transforms.EnsureChannelFirstd(keys="image"),
|
| 50 |
+
monai.transforms.Orientationd(keys="image", axcodes="RAS"),
|
| 51 |
+
monai.transforms.EnsureTyped(keys="image", dtype=torch.float32),
|
| 52 |
+
monai.transforms.ScaleIntensityRanged(
|
| 53 |
+
keys="image", a_min=-1000, a_max=1000, b_min=0, b_max=1, clip=True
|
| 54 |
+
),
|
| 55 |
+
monai.transforms.Resized(keys="image", spatial_size=dim, mode="trilinear"),
|
| 56 |
+
]
|
| 57 |
+
)
|
| 58 |
+
else:
|
| 59 |
+
return Compose(
|
| 60 |
+
[
|
| 61 |
+
monai.transforms.LoadImaged(keys="image"),
|
| 62 |
+
monai.transforms.EnsureChannelFirstd(keys="image"),
|
| 63 |
+
monai.transforms.Orientationd(keys="image", axcodes="RAS"),
|
| 64 |
+
]
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def round_number(number: int, base_number: int = 128) -> int:
|
| 69 |
+
"""
|
| 70 |
+
Round the number to the nearest multiple of the base number, with a minimum value of the base number.
|
| 71 |
+
|
| 72 |
+
Args:
|
| 73 |
+
number (int): Number to be rounded.
|
| 74 |
+
base_number (int): Number to be common divisor.
|
| 75 |
+
|
| 76 |
+
Returns:
|
| 77 |
+
int: Rounded number.
|
| 78 |
+
"""
|
| 79 |
+
new_number = max(round(float(number) / float(base_number)), 1.0) * float(base_number)
|
| 80 |
+
return int(new_number)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def load_filenames(data_list_path: str) -> list:
|
| 84 |
+
"""
|
| 85 |
+
Load filenames from the JSON data list.
|
| 86 |
+
|
| 87 |
+
Args:
|
| 88 |
+
data_list_path (str): Path to the JSON data list file.
|
| 89 |
+
|
| 90 |
+
Returns:
|
| 91 |
+
list: List of filenames.
|
| 92 |
+
"""
|
| 93 |
+
with open(data_list_path, "r") as file:
|
| 94 |
+
json_data = json.load(file)
|
| 95 |
+
filenames_raw = json_data["training"]
|
| 96 |
+
return [_item["image"] for _item in filenames_raw]
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def process_file(
|
| 100 |
+
filepath: str,
|
| 101 |
+
args: argparse.Namespace,
|
| 102 |
+
autoencoder: torch.nn.Module,
|
| 103 |
+
device: torch.device,
|
| 104 |
+
plain_transforms: Compose,
|
| 105 |
+
new_transforms: Compose,
|
| 106 |
+
logger: logging.Logger,
|
| 107 |
+
) -> None:
|
| 108 |
+
"""
|
| 109 |
+
Process a single file to create training data.
|
| 110 |
+
|
| 111 |
+
Args:
|
| 112 |
+
filepath (str): Path to the file to be processed.
|
| 113 |
+
args (argparse.Namespace): Configuration arguments.
|
| 114 |
+
autoencoder (torch.nn.Module): Autoencoder model.
|
| 115 |
+
device (torch.device): Device to process the file on.
|
| 116 |
+
plain_transforms (Compose): Plain transforms.
|
| 117 |
+
new_transforms (Compose): New transforms.
|
| 118 |
+
logger (logging.Logger): Logger for logging information.
|
| 119 |
+
"""
|
| 120 |
+
out_filename_base = filepath.replace(".gz", "").replace(".nii", "")
|
| 121 |
+
out_filename_base = os.path.join(args.embedding_base_dir, out_filename_base)
|
| 122 |
+
out_filename = out_filename_base + "_emb.nii.gz"
|
| 123 |
+
|
| 124 |
+
if os.path.isfile(out_filename):
|
| 125 |
+
return
|
| 126 |
+
|
| 127 |
+
test_data = {"image": os.path.join(args.data_base_dir, filepath)}
|
| 128 |
+
transformed_data = plain_transforms(test_data)
|
| 129 |
+
nda = transformed_data["image"]
|
| 130 |
+
|
| 131 |
+
dim = [int(nda.meta["dim"][_i]) for _i in range(1, 4)]
|
| 132 |
+
spacing = [float(nda.meta["pixdim"][_i]) for _i in range(1, 4)]
|
| 133 |
+
|
| 134 |
+
logger.info(f"old dim: {dim}, old spacing: {spacing}")
|
| 135 |
+
|
| 136 |
+
new_data = new_transforms(test_data)
|
| 137 |
+
nda_image = new_data["image"]
|
| 138 |
+
|
| 139 |
+
new_affine = nda_image.meta["affine"].numpy()
|
| 140 |
+
nda_image = nda_image.numpy().squeeze()
|
| 141 |
+
|
| 142 |
+
logger.info(f"new dim: {nda_image.shape}, new affine: {new_affine}")
|
| 143 |
+
|
| 144 |
+
try:
|
| 145 |
+
out_path = Path(out_filename)
|
| 146 |
+
out_path.parent.mkdir(parents=True, exist_ok=True)
|
| 147 |
+
logger.info(f"out_filename: {out_filename}")
|
| 148 |
+
|
| 149 |
+
with torch.amp.autocast("cuda"):
|
| 150 |
+
pt_nda = torch.from_numpy(nda_image).float().to(device).unsqueeze(0).unsqueeze(0)
|
| 151 |
+
z = autoencoder.encode_stage_2_inputs(pt_nda)
|
| 152 |
+
logger.info(f"z: {z.size()}, {z.dtype}")
|
| 153 |
+
|
| 154 |
+
out_nda = z.squeeze().cpu().detach().numpy().transpose(1, 2, 3, 0)
|
| 155 |
+
out_img = nib.Nifti1Image(np.float32(out_nda), affine=new_affine)
|
| 156 |
+
nib.save(out_img, out_filename)
|
| 157 |
+
except Exception as e:
|
| 158 |
+
logger.error(f"Error processing {filepath}: {e}")
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
@torch.inference_mode()
|
| 162 |
+
def diff_model_create_training_data(
|
| 163 |
+
env_config_path: str, model_config_path: str, model_def_path: str, num_gpus: int
|
| 164 |
+
) -> None:
|
| 165 |
+
"""
|
| 166 |
+
Create training data for the diffusion model.
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
env_config_path (str): Path to the environment configuration file.
|
| 170 |
+
model_config_path (str): Path to the model configuration file.
|
| 171 |
+
model_def_path (str): Path to the model definition file.
|
| 172 |
+
"""
|
| 173 |
+
args = load_config(env_config_path, model_config_path, model_def_path)
|
| 174 |
+
local_rank, world_size, device = initialize_distributed(num_gpus=num_gpus)
|
| 175 |
+
logger = setup_logging("creating training data")
|
| 176 |
+
logger.info(f"Using device {device}")
|
| 177 |
+
|
| 178 |
+
autoencoder = define_instance(args, "autoencoder_def").to(device)
|
| 179 |
+
try:
|
| 180 |
+
checkpoint_autoencoder = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 181 |
+
autoencoder.load_state_dict(checkpoint_autoencoder)
|
| 182 |
+
except Exception:
|
| 183 |
+
logger.error("The trained_autoencoder_path does not exist!")
|
| 184 |
+
|
| 185 |
+
Path(args.embedding_base_dir).mkdir(parents=True, exist_ok=True)
|
| 186 |
+
|
| 187 |
+
filenames_raw = load_filenames(args.json_data_list)
|
| 188 |
+
logger.info(f"filenames_raw: {filenames_raw}")
|
| 189 |
+
|
| 190 |
+
plain_transforms = create_transforms(dim=None)
|
| 191 |
+
|
| 192 |
+
for _iter in range(len(filenames_raw)):
|
| 193 |
+
if _iter % world_size != local_rank:
|
| 194 |
+
continue
|
| 195 |
+
|
| 196 |
+
filepath = filenames_raw[_iter]
|
| 197 |
+
new_dim = tuple(
|
| 198 |
+
round_number(
|
| 199 |
+
int(plain_transforms({"image": os.path.join(args.data_base_dir, filepath)})["image"].meta["dim"][_i])
|
| 200 |
+
)
|
| 201 |
+
for _i in range(1, 4)
|
| 202 |
+
)
|
| 203 |
+
new_transforms = create_transforms(new_dim)
|
| 204 |
+
|
| 205 |
+
process_file(filepath, args, autoencoder, device, plain_transforms, new_transforms, logger)
|
| 206 |
+
|
| 207 |
+
if dist.is_initialized():
|
| 208 |
+
dist.destroy_process_group()
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
if __name__ == "__main__":
|
| 212 |
+
parser = argparse.ArgumentParser(description="Diffusion Model Training Data Creation")
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--env_config",
|
| 215 |
+
type=str,
|
| 216 |
+
default="./configs/environment_maisi_diff_model_train.json",
|
| 217 |
+
help="Path to environment configuration file",
|
| 218 |
+
)
|
| 219 |
+
parser.add_argument(
|
| 220 |
+
"--model_config",
|
| 221 |
+
type=str,
|
| 222 |
+
default="./configs/config_maisi_diff_model_train.json",
|
| 223 |
+
help="Path to model training/inference configuration",
|
| 224 |
+
)
|
| 225 |
+
parser.add_argument(
|
| 226 |
+
"--model_def", type=str, default="./configs/config_maisi.json", help="Path to model definition file"
|
| 227 |
+
)
|
| 228 |
+
parser.add_argument("--num_gpus", type=int, default=1, help="Number of GPUs to use for distributed training")
|
| 229 |
+
|
| 230 |
+
args = parser.parse_args()
|
| 231 |
+
diff_model_create_training_data(args.env_config, args.model_config, args.model_def, args.num_gpus)
|
scripts/diff_model_infer.py
ADDED
|
@@ -0,0 +1,358 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import logging
|
| 16 |
+
import os
|
| 17 |
+
import random
|
| 18 |
+
from datetime import datetime
|
| 19 |
+
|
| 20 |
+
import nibabel as nib
|
| 21 |
+
import numpy as np
|
| 22 |
+
import torch
|
| 23 |
+
import torch.distributed as dist
|
| 24 |
+
from monai.inferers import sliding_window_inference
|
| 25 |
+
from monai.inferers.inferer import SlidingWindowInferer
|
| 26 |
+
from monai.networks.schedulers import RFlowScheduler
|
| 27 |
+
from monai.utils import set_determinism
|
| 28 |
+
from tqdm import tqdm
|
| 29 |
+
|
| 30 |
+
from .diff_model_setting import initialize_distributed, load_config, setup_logging
|
| 31 |
+
from .sample import ReconModel, check_input
|
| 32 |
+
from .utils import define_instance, dynamic_infer
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def set_random_seed(seed: int) -> int:
|
| 36 |
+
"""
|
| 37 |
+
Set random seed for reproducibility.
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
seed (int): Random seed.
|
| 41 |
+
|
| 42 |
+
Returns:
|
| 43 |
+
int: Set random seed.
|
| 44 |
+
"""
|
| 45 |
+
random_seed = random.randint(0, 99999) if seed is None else seed
|
| 46 |
+
set_determinism(random_seed)
|
| 47 |
+
return random_seed
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def load_models(args: argparse.Namespace, device: torch.device, logger: logging.Logger) -> tuple:
|
| 51 |
+
"""
|
| 52 |
+
Load the autoencoder and UNet models.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
args (argparse.Namespace): Configuration arguments.
|
| 56 |
+
device (torch.device): Device to load models on.
|
| 57 |
+
logger (logging.Logger): Logger for logging information.
|
| 58 |
+
|
| 59 |
+
Returns:
|
| 60 |
+
tuple: Loaded autoencoder, UNet model, and scale factor.
|
| 61 |
+
"""
|
| 62 |
+
autoencoder = define_instance(args, "autoencoder_def").to(device)
|
| 63 |
+
try:
|
| 64 |
+
checkpoint_autoencoder = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 65 |
+
autoencoder.load_state_dict(checkpoint_autoencoder)
|
| 66 |
+
except Exception:
|
| 67 |
+
logger.error("The trained_autoencoder_path does not exist!")
|
| 68 |
+
|
| 69 |
+
unet = define_instance(args, "diffusion_unet_def").to(device)
|
| 70 |
+
checkpoint = torch.load(f"{args.model_dir}/{args.model_filename}", map_location=device, weights_only=False)
|
| 71 |
+
unet.load_state_dict(checkpoint["unet_state_dict"], strict=True)
|
| 72 |
+
logger.info(f"checkpoints {args.model_dir}/{args.model_filename} loaded.")
|
| 73 |
+
|
| 74 |
+
scale_factor = checkpoint["scale_factor"]
|
| 75 |
+
logger.info(f"scale_factor -> {scale_factor}.")
|
| 76 |
+
|
| 77 |
+
return autoencoder, unet, scale_factor
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def prepare_tensors(args: argparse.Namespace, device: torch.device) -> tuple:
|
| 81 |
+
"""
|
| 82 |
+
Prepare necessary tensors for inference.
|
| 83 |
+
|
| 84 |
+
Args:
|
| 85 |
+
args (argparse.Namespace): Configuration arguments.
|
| 86 |
+
device (torch.device): Device to load tensors on.
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
tuple: Prepared top_region_index_tensor, bottom_region_index_tensor, and spacing_tensor.
|
| 90 |
+
"""
|
| 91 |
+
top_region_index_tensor = np.array(args.diffusion_unet_inference["top_region_index"]).astype(float) * 1e2
|
| 92 |
+
bottom_region_index_tensor = np.array(args.diffusion_unet_inference["bottom_region_index"]).astype(float) * 1e2
|
| 93 |
+
spacing_tensor = np.array(args.diffusion_unet_inference["spacing"]).astype(float) * 1e2
|
| 94 |
+
|
| 95 |
+
top_region_index_tensor = torch.from_numpy(top_region_index_tensor[np.newaxis, :]).half().to(device)
|
| 96 |
+
bottom_region_index_tensor = torch.from_numpy(bottom_region_index_tensor[np.newaxis, :]).half().to(device)
|
| 97 |
+
spacing_tensor = torch.from_numpy(spacing_tensor[np.newaxis, :]).half().to(device)
|
| 98 |
+
modality_tensor = args.diffusion_unet_inference["modality"] * torch.ones(
|
| 99 |
+
(len(spacing_tensor)), dtype=torch.long
|
| 100 |
+
).to(device)
|
| 101 |
+
|
| 102 |
+
return top_region_index_tensor, bottom_region_index_tensor, spacing_tensor, modality_tensor
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def run_inference(
|
| 106 |
+
args: argparse.Namespace,
|
| 107 |
+
device: torch.device,
|
| 108 |
+
autoencoder: torch.nn.Module,
|
| 109 |
+
unet: torch.nn.Module,
|
| 110 |
+
scale_factor: float,
|
| 111 |
+
top_region_index_tensor: torch.Tensor,
|
| 112 |
+
bottom_region_index_tensor: torch.Tensor,
|
| 113 |
+
spacing_tensor: torch.Tensor,
|
| 114 |
+
modality_tensor: torch.Tensor,
|
| 115 |
+
output_size: tuple,
|
| 116 |
+
divisor: int,
|
| 117 |
+
logger: logging.Logger,
|
| 118 |
+
) -> np.ndarray:
|
| 119 |
+
"""
|
| 120 |
+
Run the inference to generate synthetic images.
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
args (argparse.Namespace): Configuration arguments.
|
| 124 |
+
device (torch.device): Device to run inference on.
|
| 125 |
+
autoencoder (torch.nn.Module): Autoencoder model.
|
| 126 |
+
unet (torch.nn.Module): UNet model.
|
| 127 |
+
scale_factor (float): Scale factor for the model.
|
| 128 |
+
top_region_index_tensor (torch.Tensor): Top region index tensor.
|
| 129 |
+
bottom_region_index_tensor (torch.Tensor): Bottom region index tensor.
|
| 130 |
+
spacing_tensor (torch.Tensor): Spacing tensor.
|
| 131 |
+
modality_tensor (torch.Tensor): Modality tensor.
|
| 132 |
+
output_size (tuple): Output size of the synthetic image.
|
| 133 |
+
divisor (int): Divisor for downsample level.
|
| 134 |
+
logger (logging.Logger): Logger for logging information.
|
| 135 |
+
|
| 136 |
+
Returns:
|
| 137 |
+
np.ndarray: Generated synthetic image data.
|
| 138 |
+
"""
|
| 139 |
+
include_body_region = unet.include_top_region_index_input
|
| 140 |
+
include_modality = unet.num_class_embeds is not None
|
| 141 |
+
|
| 142 |
+
noise = torch.randn(
|
| 143 |
+
(
|
| 144 |
+
1,
|
| 145 |
+
args.latent_channels,
|
| 146 |
+
output_size[0] // divisor,
|
| 147 |
+
output_size[1] // divisor,
|
| 148 |
+
output_size[2] // divisor,
|
| 149 |
+
),
|
| 150 |
+
device=device,
|
| 151 |
+
)
|
| 152 |
+
logger.info(f"noise: {noise.device}, {noise.dtype}, {type(noise)}")
|
| 153 |
+
|
| 154 |
+
image = noise
|
| 155 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 156 |
+
if isinstance(noise_scheduler, RFlowScheduler):
|
| 157 |
+
noise_scheduler.set_timesteps(
|
| 158 |
+
num_inference_steps=args.diffusion_unet_inference["num_inference_steps"],
|
| 159 |
+
input_img_size_numel=torch.prod(torch.tensor(noise.shape[2:])),
|
| 160 |
+
)
|
| 161 |
+
else:
|
| 162 |
+
noise_scheduler.set_timesteps(num_inference_steps=args.diffusion_unet_inference["num_inference_steps"])
|
| 163 |
+
|
| 164 |
+
recon_model = ReconModel(autoencoder=autoencoder, scale_factor=scale_factor).to(device)
|
| 165 |
+
autoencoder.eval()
|
| 166 |
+
unet.eval()
|
| 167 |
+
|
| 168 |
+
all_timesteps = noise_scheduler.timesteps
|
| 169 |
+
all_next_timesteps = torch.cat((all_timesteps[1:], torch.tensor([0], dtype=all_timesteps.dtype)))
|
| 170 |
+
progress_bar = tqdm(
|
| 171 |
+
zip(all_timesteps, all_next_timesteps),
|
| 172 |
+
total=min(len(all_timesteps), len(all_next_timesteps)),
|
| 173 |
+
)
|
| 174 |
+
with torch.amp.autocast("cuda", enabled=True):
|
| 175 |
+
for t, next_t in progress_bar:
|
| 176 |
+
# Create a dictionary to store the inputs
|
| 177 |
+
unet_inputs = {
|
| 178 |
+
"x": image,
|
| 179 |
+
"timesteps": torch.Tensor((t,)).to(device),
|
| 180 |
+
"spacing_tensor": spacing_tensor,
|
| 181 |
+
}
|
| 182 |
+
|
| 183 |
+
# Add extra arguments if include_body_region is True
|
| 184 |
+
if include_body_region:
|
| 185 |
+
unet_inputs.update(
|
| 186 |
+
{
|
| 187 |
+
"top_region_index_tensor": top_region_index_tensor,
|
| 188 |
+
"bottom_region_index_tensor": bottom_region_index_tensor,
|
| 189 |
+
}
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
if include_modality:
|
| 193 |
+
unet_inputs.update(
|
| 194 |
+
{
|
| 195 |
+
"class_labels": modality_tensor,
|
| 196 |
+
}
|
| 197 |
+
)
|
| 198 |
+
model_output = unet(**unet_inputs)
|
| 199 |
+
if not isinstance(noise_scheduler, RFlowScheduler):
|
| 200 |
+
image, _ = noise_scheduler.step(model_output, t, image) # type: ignore
|
| 201 |
+
else:
|
| 202 |
+
image, _ = noise_scheduler.step(model_output, t, image, next_t) # type: ignore
|
| 203 |
+
|
| 204 |
+
inferer = SlidingWindowInferer(
|
| 205 |
+
roi_size=[80, 80, 80],
|
| 206 |
+
sw_batch_size=1,
|
| 207 |
+
progress=True,
|
| 208 |
+
mode="gaussian",
|
| 209 |
+
overlap=0.4,
|
| 210 |
+
sw_device=device,
|
| 211 |
+
device=device,
|
| 212 |
+
)
|
| 213 |
+
synthetic_images = dynamic_infer(inferer, recon_model, image)
|
| 214 |
+
data = synthetic_images.squeeze().cpu().detach().numpy()
|
| 215 |
+
a_min, a_max, b_min, b_max = -1000, 1000, 0, 1
|
| 216 |
+
data = (data - b_min) / (b_max - b_min) * (a_max - a_min) + a_min
|
| 217 |
+
data = np.clip(data, a_min, a_max)
|
| 218 |
+
return np.int16(data)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def save_image(
|
| 222 |
+
data: np.ndarray,
|
| 223 |
+
output_size: tuple,
|
| 224 |
+
out_spacing: tuple,
|
| 225 |
+
output_path: str,
|
| 226 |
+
logger: logging.Logger,
|
| 227 |
+
) -> None:
|
| 228 |
+
"""
|
| 229 |
+
Save the generated synthetic image to a file.
|
| 230 |
+
|
| 231 |
+
Args:
|
| 232 |
+
data (np.ndarray): Synthetic image data.
|
| 233 |
+
output_size (tuple): Output size of the image.
|
| 234 |
+
out_spacing (tuple): Spacing of the output image.
|
| 235 |
+
output_path (str): Path to save the output image.
|
| 236 |
+
logger (logging.Logger): Logger for logging information.
|
| 237 |
+
"""
|
| 238 |
+
out_affine = np.eye(4)
|
| 239 |
+
for i in range(3):
|
| 240 |
+
out_affine[i, i] = out_spacing[i]
|
| 241 |
+
|
| 242 |
+
new_image = nib.Nifti1Image(data, affine=out_affine)
|
| 243 |
+
os.makedirs(os.path.dirname(output_path), exist_ok=True)
|
| 244 |
+
nib.save(new_image, output_path)
|
| 245 |
+
logger.info(f"Saved {output_path}.")
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
@torch.inference_mode()
|
| 249 |
+
def diff_model_infer(env_config_path: str, model_config_path: str, model_def_path: str, num_gpus: int) -> None:
|
| 250 |
+
"""
|
| 251 |
+
Main function to run the diffusion model inference.
|
| 252 |
+
|
| 253 |
+
Args:
|
| 254 |
+
env_config_path (str): Path to the environment configuration file.
|
| 255 |
+
model_config_path (str): Path to the model configuration file.
|
| 256 |
+
model_def_path (str): Path to the model definition file.
|
| 257 |
+
"""
|
| 258 |
+
args = load_config(env_config_path, model_config_path, model_def_path)
|
| 259 |
+
local_rank, world_size, device = initialize_distributed(num_gpus)
|
| 260 |
+
logger = setup_logging("inference")
|
| 261 |
+
random_seed = set_random_seed(
|
| 262 |
+
args.diffusion_unet_inference["random_seed"] + local_rank
|
| 263 |
+
if args.diffusion_unet_inference["random_seed"]
|
| 264 |
+
else None
|
| 265 |
+
)
|
| 266 |
+
logger.info(f"Using {device} of {world_size} with random seed: {random_seed}")
|
| 267 |
+
|
| 268 |
+
output_size = tuple(args.diffusion_unet_inference["dim"])
|
| 269 |
+
out_spacing = tuple(args.diffusion_unet_inference["spacing"])
|
| 270 |
+
output_prefix = args.output_prefix
|
| 271 |
+
ckpt_filepath = f"{args.model_dir}/{args.model_filename}"
|
| 272 |
+
|
| 273 |
+
if local_rank == 0:
|
| 274 |
+
logger.info(f"[config] ckpt_filepath -> {ckpt_filepath}.")
|
| 275 |
+
logger.info(f"[config] random_seed -> {random_seed}.")
|
| 276 |
+
logger.info(f"[config] output_prefix -> {output_prefix}.")
|
| 277 |
+
logger.info(f"[config] output_size -> {output_size}.")
|
| 278 |
+
logger.info(f"[config] out_spacing -> {out_spacing}.")
|
| 279 |
+
|
| 280 |
+
check_input(None, None, None, output_size, out_spacing, None)
|
| 281 |
+
|
| 282 |
+
autoencoder, unet, scale_factor = load_models(args, device, logger)
|
| 283 |
+
num_downsample_level = max(
|
| 284 |
+
1,
|
| 285 |
+
(
|
| 286 |
+
len(args.diffusion_unet_def["num_channels"])
|
| 287 |
+
if isinstance(args.diffusion_unet_def["num_channels"], list)
|
| 288 |
+
else len(args.diffusion_unet_def["attention_levels"])
|
| 289 |
+
),
|
| 290 |
+
)
|
| 291 |
+
divisor = 2 ** (num_downsample_level - 2)
|
| 292 |
+
logger.info(f"num_downsample_level -> {num_downsample_level}, divisor -> {divisor}.")
|
| 293 |
+
|
| 294 |
+
top_region_index_tensor, bottom_region_index_tensor, spacing_tensor, modality_tensor = prepare_tensors(args, device)
|
| 295 |
+
data = run_inference(
|
| 296 |
+
args,
|
| 297 |
+
device,
|
| 298 |
+
autoencoder,
|
| 299 |
+
unet,
|
| 300 |
+
scale_factor,
|
| 301 |
+
top_region_index_tensor,
|
| 302 |
+
bottom_region_index_tensor,
|
| 303 |
+
spacing_tensor,
|
| 304 |
+
modality_tensor,
|
| 305 |
+
output_size,
|
| 306 |
+
divisor,
|
| 307 |
+
logger,
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
|
| 311 |
+
output_path = "{0}/{1}_seed{2}_size{3:d}x{4:d}x{5:d}_spacing{6:.2f}x{7:.2f}x{8:.2f}_{9}_rank{10}.nii.gz".format(
|
| 312 |
+
args.output_dir,
|
| 313 |
+
output_prefix,
|
| 314 |
+
random_seed,
|
| 315 |
+
output_size[0],
|
| 316 |
+
output_size[1],
|
| 317 |
+
output_size[2],
|
| 318 |
+
out_spacing[0],
|
| 319 |
+
out_spacing[1],
|
| 320 |
+
out_spacing[2],
|
| 321 |
+
timestamp,
|
| 322 |
+
local_rank,
|
| 323 |
+
)
|
| 324 |
+
save_image(data, output_size, out_spacing, output_path, logger)
|
| 325 |
+
|
| 326 |
+
if dist.is_initialized():
|
| 327 |
+
dist.destroy_process_group()
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
if __name__ == "__main__":
|
| 331 |
+
parser = argparse.ArgumentParser(description="Diffusion Model Inference")
|
| 332 |
+
parser.add_argument(
|
| 333 |
+
"--env_config",
|
| 334 |
+
type=str,
|
| 335 |
+
default="./configs/environment_maisi_diff_model_train.json",
|
| 336 |
+
help="Path to environment configuration file",
|
| 337 |
+
)
|
| 338 |
+
parser.add_argument(
|
| 339 |
+
"--model_config",
|
| 340 |
+
type=str,
|
| 341 |
+
default="./configs/config_maisi_diff_model_train.json",
|
| 342 |
+
help="Path to model training/inference configuration",
|
| 343 |
+
)
|
| 344 |
+
parser.add_argument(
|
| 345 |
+
"--model_def",
|
| 346 |
+
type=str,
|
| 347 |
+
default="./configs/config_maisi.json",
|
| 348 |
+
help="Path to model definition file",
|
| 349 |
+
)
|
| 350 |
+
parser.add_argument(
|
| 351 |
+
"--num_gpus",
|
| 352 |
+
type=int,
|
| 353 |
+
default=1,
|
| 354 |
+
help="Number of GPUs to use for distributed inference",
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
args = parser.parse_args()
|
| 358 |
+
diff_model_infer(args.env_config, args.model_config, args.model_def, args.num_gpus)
|
scripts/diff_model_setting.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import json
|
| 16 |
+
import logging
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
import torch.distributed as dist
|
| 20 |
+
from monai.utils import RankFilter
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def setup_logging(logger_name: str = "") -> logging.Logger:
|
| 24 |
+
"""
|
| 25 |
+
Setup the logging configuration.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
logger_name (str): logger name.
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
logging.Logger: Configured logger.
|
| 32 |
+
"""
|
| 33 |
+
logger = logging.getLogger(logger_name)
|
| 34 |
+
if dist.is_initialized():
|
| 35 |
+
logger.addFilter(RankFilter())
|
| 36 |
+
logging.basicConfig(
|
| 37 |
+
level=logging.INFO,
|
| 38 |
+
format="[%(asctime)s.%(msecs)03d][%(levelname)5s](%(name)s) - %(message)s",
|
| 39 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 40 |
+
)
|
| 41 |
+
return logger
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def load_config(env_config_path: str, model_config_path: str, model_def_path: str) -> argparse.Namespace:
|
| 45 |
+
"""
|
| 46 |
+
Load configuration from JSON files.
|
| 47 |
+
|
| 48 |
+
Args:
|
| 49 |
+
env_config_path (str): Path to the environment configuration file.
|
| 50 |
+
model_config_path (str): Path to the model configuration file.
|
| 51 |
+
model_def_path (str): Path to the model definition file.
|
| 52 |
+
|
| 53 |
+
Returns:
|
| 54 |
+
argparse.Namespace: Loaded configuration.
|
| 55 |
+
"""
|
| 56 |
+
args = argparse.Namespace()
|
| 57 |
+
|
| 58 |
+
with open(env_config_path, "r") as f:
|
| 59 |
+
env_config = json.load(f)
|
| 60 |
+
for k, v in env_config.items():
|
| 61 |
+
setattr(args, k, v)
|
| 62 |
+
|
| 63 |
+
with open(model_config_path, "r") as f:
|
| 64 |
+
model_config = json.load(f)
|
| 65 |
+
for k, v in model_config.items():
|
| 66 |
+
setattr(args, k, v)
|
| 67 |
+
|
| 68 |
+
with open(model_def_path, "r") as f:
|
| 69 |
+
model_def = json.load(f)
|
| 70 |
+
for k, v in model_def.items():
|
| 71 |
+
setattr(args, k, v)
|
| 72 |
+
|
| 73 |
+
return args
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def initialize_distributed(num_gpus: int) -> tuple:
|
| 77 |
+
"""
|
| 78 |
+
Initialize distributed training.
|
| 79 |
+
|
| 80 |
+
Returns:
|
| 81 |
+
tuple: local_rank, world_size, and device.
|
| 82 |
+
"""
|
| 83 |
+
if torch.cuda.is_available() and num_gpus > 1:
|
| 84 |
+
dist.init_process_group(backend="nccl", init_method="env://")
|
| 85 |
+
local_rank = dist.get_rank()
|
| 86 |
+
world_size = dist.get_world_size()
|
| 87 |
+
else:
|
| 88 |
+
local_rank = 0
|
| 89 |
+
world_size = 1
|
| 90 |
+
device = torch.device("cuda", local_rank)
|
| 91 |
+
torch.cuda.set_device(device)
|
| 92 |
+
return local_rank, world_size, device
|
scripts/diff_model_train.py
ADDED
|
@@ -0,0 +1,499 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import json
|
| 16 |
+
import logging
|
| 17 |
+
import os
|
| 18 |
+
from datetime import datetime
|
| 19 |
+
from pathlib import Path
|
| 20 |
+
|
| 21 |
+
import monai
|
| 22 |
+
import torch
|
| 23 |
+
import torch.distributed as dist
|
| 24 |
+
from monai.data import DataLoader, partition_dataset
|
| 25 |
+
from monai.networks.schedulers import RFlowScheduler
|
| 26 |
+
from monai.networks.schedulers.ddpm import DDPMPredictionType
|
| 27 |
+
from monai.transforms import Compose
|
| 28 |
+
from monai.utils import first
|
| 29 |
+
from torch.amp import GradScaler, autocast
|
| 30 |
+
from torch.nn.parallel import DistributedDataParallel
|
| 31 |
+
|
| 32 |
+
from .diff_model_setting import initialize_distributed, load_config, setup_logging
|
| 33 |
+
from .utils import define_instance
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def load_filenames(data_list_path: str) -> list:
|
| 37 |
+
"""
|
| 38 |
+
Load filenames from the JSON data list.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
data_list_path (str): Path to the JSON data list file.
|
| 42 |
+
|
| 43 |
+
Returns:
|
| 44 |
+
list: List of filenames.
|
| 45 |
+
"""
|
| 46 |
+
with open(data_list_path, "r") as file:
|
| 47 |
+
json_data = json.load(file)
|
| 48 |
+
filenames_train = json_data["training"]
|
| 49 |
+
return [_item["image"].replace(".nii.gz", "_emb.nii.gz") for _item in filenames_train]
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def prepare_data(
|
| 53 |
+
train_files: list,
|
| 54 |
+
device: torch.device,
|
| 55 |
+
cache_rate: float,
|
| 56 |
+
num_workers: int = 2,
|
| 57 |
+
batch_size: int = 1,
|
| 58 |
+
include_body_region: bool = False,
|
| 59 |
+
) -> DataLoader:
|
| 60 |
+
"""
|
| 61 |
+
Prepare training data.
|
| 62 |
+
|
| 63 |
+
Args:
|
| 64 |
+
train_files (list): List of training files.
|
| 65 |
+
device (torch.device): Device to use for training.
|
| 66 |
+
cache_rate (float): Cache rate for dataset.
|
| 67 |
+
num_workers (int): Number of workers for data loading.
|
| 68 |
+
batch_size (int): Mini-batch size.
|
| 69 |
+
include_body_region (bool): Whether to include body region in data
|
| 70 |
+
|
| 71 |
+
Returns:
|
| 72 |
+
DataLoader: Data loader for training.
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def _load_data_from_file(file_path, key):
|
| 76 |
+
with open(file_path) as f:
|
| 77 |
+
return torch.FloatTensor(json.load(f)[key])
|
| 78 |
+
|
| 79 |
+
train_transforms_list = [
|
| 80 |
+
monai.transforms.LoadImaged(keys=["image"]),
|
| 81 |
+
monai.transforms.EnsureChannelFirstd(keys=["image"]),
|
| 82 |
+
monai.transforms.Lambdad(keys="spacing", func=lambda x: _load_data_from_file(x, "spacing")),
|
| 83 |
+
monai.transforms.Lambdad(keys="spacing", func=lambda x: x * 1e2),
|
| 84 |
+
]
|
| 85 |
+
if include_body_region:
|
| 86 |
+
train_transforms_list += [
|
| 87 |
+
monai.transforms.Lambdad(
|
| 88 |
+
keys="top_region_index", func=lambda x: _load_data_from_file(x, "top_region_index")
|
| 89 |
+
),
|
| 90 |
+
monai.transforms.Lambdad(
|
| 91 |
+
keys="bottom_region_index", func=lambda x: _load_data_from_file(x, "bottom_region_index")
|
| 92 |
+
),
|
| 93 |
+
monai.transforms.Lambdad(keys="top_region_index", func=lambda x: x * 1e2),
|
| 94 |
+
monai.transforms.Lambdad(keys="bottom_region_index", func=lambda x: x * 1e2),
|
| 95 |
+
]
|
| 96 |
+
train_transforms = Compose(train_transforms_list)
|
| 97 |
+
|
| 98 |
+
train_ds = monai.data.CacheDataset(
|
| 99 |
+
data=train_files, transform=train_transforms, cache_rate=cache_rate, num_workers=num_workers
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
return DataLoader(train_ds, num_workers=6, batch_size=batch_size, shuffle=True)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def load_unet(args: argparse.Namespace, device: torch.device, logger: logging.Logger) -> torch.nn.Module:
|
| 106 |
+
"""
|
| 107 |
+
Load the UNet model.
|
| 108 |
+
|
| 109 |
+
Args:
|
| 110 |
+
args (argparse.Namespace): Configuration arguments.
|
| 111 |
+
device (torch.device): Device to load the model on.
|
| 112 |
+
logger (logging.Logger): Logger for logging information.
|
| 113 |
+
|
| 114 |
+
Returns:
|
| 115 |
+
torch.nn.Module: Loaded UNet model.
|
| 116 |
+
"""
|
| 117 |
+
unet = define_instance(args, "diffusion_unet_def").to(device)
|
| 118 |
+
unet = torch.nn.SyncBatchNorm.convert_sync_batchnorm(unet)
|
| 119 |
+
|
| 120 |
+
if dist.is_initialized():
|
| 121 |
+
unet = DistributedDataParallel(unet, device_ids=[device], find_unused_parameters=True)
|
| 122 |
+
|
| 123 |
+
if args.existing_ckpt_filepath is None:
|
| 124 |
+
logger.info("Training from scratch.")
|
| 125 |
+
else:
|
| 126 |
+
checkpoint_unet = torch.load(f"{args.existing_ckpt_filepath}", map_location=device, weights_only=False)
|
| 127 |
+
if dist.is_initialized():
|
| 128 |
+
unet.module.load_state_dict(checkpoint_unet["unet_state_dict"], strict=True)
|
| 129 |
+
else:
|
| 130 |
+
unet.load_state_dict(checkpoint_unet["unet_state_dict"], strict=True)
|
| 131 |
+
logger.info(f"Pretrained checkpoint {args.existing_ckpt_filepath} loaded.")
|
| 132 |
+
|
| 133 |
+
return unet
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def calculate_scale_factor(train_loader: DataLoader, device: torch.device, logger: logging.Logger) -> torch.Tensor:
|
| 137 |
+
"""
|
| 138 |
+
Calculate the scaling factor for the dataset.
|
| 139 |
+
|
| 140 |
+
Args:
|
| 141 |
+
train_loader (DataLoader): Data loader for training.
|
| 142 |
+
device (torch.device): Device to use for calculation.
|
| 143 |
+
logger (logging.Logger): Logger for logging information.
|
| 144 |
+
|
| 145 |
+
Returns:
|
| 146 |
+
torch.Tensor: Calculated scaling factor.
|
| 147 |
+
"""
|
| 148 |
+
check_data = first(train_loader)
|
| 149 |
+
z = check_data["image"].to(device)
|
| 150 |
+
scale_factor = 1 / torch.std(z)
|
| 151 |
+
logger.info(f"Scaling factor set to {scale_factor}.")
|
| 152 |
+
|
| 153 |
+
if dist.is_initialized():
|
| 154 |
+
dist.barrier()
|
| 155 |
+
dist.all_reduce(scale_factor, op=torch.distributed.ReduceOp.AVG)
|
| 156 |
+
logger.info(f"scale_factor -> {scale_factor}.")
|
| 157 |
+
return scale_factor
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def create_optimizer(model: torch.nn.Module, lr: float) -> torch.optim.Optimizer:
|
| 161 |
+
"""
|
| 162 |
+
Create optimizer for training.
|
| 163 |
+
|
| 164 |
+
Args:
|
| 165 |
+
model (torch.nn.Module): Model to optimize.
|
| 166 |
+
lr (float): Learning rate.
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
torch.optim.Optimizer: Created optimizer.
|
| 170 |
+
"""
|
| 171 |
+
return torch.optim.Adam(params=model.parameters(), lr=lr)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def create_lr_scheduler(optimizer: torch.optim.Optimizer, total_steps: int) -> torch.optim.lr_scheduler.PolynomialLR:
|
| 175 |
+
"""
|
| 176 |
+
Create learning rate scheduler.
|
| 177 |
+
|
| 178 |
+
Args:
|
| 179 |
+
optimizer (torch.optim.Optimizer): Optimizer to schedule.
|
| 180 |
+
total_steps (int): Total number of training steps.
|
| 181 |
+
|
| 182 |
+
Returns:
|
| 183 |
+
torch.optim.lr_scheduler.PolynomialLR: Created learning rate scheduler.
|
| 184 |
+
"""
|
| 185 |
+
return torch.optim.lr_scheduler.PolynomialLR(optimizer, total_iters=total_steps, power=2.0)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def train_one_epoch(
|
| 189 |
+
epoch: int,
|
| 190 |
+
unet: torch.nn.Module,
|
| 191 |
+
train_loader: DataLoader,
|
| 192 |
+
optimizer: torch.optim.Optimizer,
|
| 193 |
+
lr_scheduler: torch.optim.lr_scheduler.PolynomialLR,
|
| 194 |
+
loss_pt: torch.nn.L1Loss,
|
| 195 |
+
scaler: GradScaler,
|
| 196 |
+
scale_factor: torch.Tensor,
|
| 197 |
+
noise_scheduler: torch.nn.Module,
|
| 198 |
+
num_images_per_batch: int,
|
| 199 |
+
num_train_timesteps: int,
|
| 200 |
+
device: torch.device,
|
| 201 |
+
logger: logging.Logger,
|
| 202 |
+
local_rank: int,
|
| 203 |
+
amp: bool = True,
|
| 204 |
+
) -> torch.Tensor:
|
| 205 |
+
"""
|
| 206 |
+
Train the model for one epoch.
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
epoch (int): Current epoch number.
|
| 210 |
+
unet (torch.nn.Module): UNet model.
|
| 211 |
+
train_loader (DataLoader): Data loader for training.
|
| 212 |
+
optimizer (torch.optim.Optimizer): Optimizer.
|
| 213 |
+
lr_scheduler (torch.optim.lr_scheduler.PolynomialLR): Learning rate scheduler.
|
| 214 |
+
loss_pt (torch.nn.L1Loss): Loss function.
|
| 215 |
+
scaler (GradScaler): Gradient scaler for mixed precision training.
|
| 216 |
+
scale_factor (torch.Tensor): Scaling factor.
|
| 217 |
+
noise_scheduler (torch.nn.Module): Noise scheduler.
|
| 218 |
+
num_images_per_batch (int): Number of images per batch.
|
| 219 |
+
num_train_timesteps (int): Number of training timesteps.
|
| 220 |
+
device (torch.device): Device to use for training.
|
| 221 |
+
logger (logging.Logger): Logger for logging information.
|
| 222 |
+
local_rank (int): Local rank for distributed training.
|
| 223 |
+
amp (bool): Use automatic mixed precision training.
|
| 224 |
+
|
| 225 |
+
Returns:
|
| 226 |
+
torch.Tensor: Training loss for the epoch.
|
| 227 |
+
"""
|
| 228 |
+
include_body_region = unet.include_top_region_index_input
|
| 229 |
+
include_modality = unet.num_class_embeds is not None
|
| 230 |
+
|
| 231 |
+
if local_rank == 0:
|
| 232 |
+
current_lr = optimizer.param_groups[0]["lr"]
|
| 233 |
+
logger.info(f"Epoch {epoch + 1}, lr {current_lr}.")
|
| 234 |
+
|
| 235 |
+
_iter = 0
|
| 236 |
+
loss_torch = torch.zeros(2, dtype=torch.float, device=device)
|
| 237 |
+
|
| 238 |
+
unet.train()
|
| 239 |
+
for train_data in train_loader:
|
| 240 |
+
current_lr = optimizer.param_groups[0]["lr"]
|
| 241 |
+
|
| 242 |
+
_iter += 1
|
| 243 |
+
images = train_data["image"].to(device)
|
| 244 |
+
images = images * scale_factor
|
| 245 |
+
|
| 246 |
+
if include_body_region:
|
| 247 |
+
top_region_index_tensor = train_data["top_region_index"].to(device)
|
| 248 |
+
bottom_region_index_tensor = train_data["bottom_region_index"].to(device)
|
| 249 |
+
# We trained with only CT in this version
|
| 250 |
+
if include_modality:
|
| 251 |
+
modality_tensor = torch.ones((len(images),), dtype=torch.long).to(device)
|
| 252 |
+
spacing_tensor = train_data["spacing"].to(device)
|
| 253 |
+
|
| 254 |
+
optimizer.zero_grad(set_to_none=True)
|
| 255 |
+
|
| 256 |
+
with autocast("cuda", enabled=amp):
|
| 257 |
+
noise = torch.randn_like(images)
|
| 258 |
+
|
| 259 |
+
if isinstance(noise_scheduler, RFlowScheduler):
|
| 260 |
+
timesteps = noise_scheduler.sample_timesteps(images)
|
| 261 |
+
else:
|
| 262 |
+
timesteps = torch.randint(0, num_train_timesteps, (images.shape[0],), device=images.device).long()
|
| 263 |
+
|
| 264 |
+
noisy_latent = noise_scheduler.add_noise(original_samples=images, noise=noise, timesteps=timesteps)
|
| 265 |
+
|
| 266 |
+
# Create a dictionary to store the inputs
|
| 267 |
+
unet_inputs = {
|
| 268 |
+
"x": noisy_latent,
|
| 269 |
+
"timesteps": timesteps,
|
| 270 |
+
"spacing_tensor": spacing_tensor,
|
| 271 |
+
}
|
| 272 |
+
# Add extra arguments if include_body_region is True
|
| 273 |
+
if include_body_region:
|
| 274 |
+
unet_inputs.update(
|
| 275 |
+
{
|
| 276 |
+
"top_region_index_tensor": top_region_index_tensor,
|
| 277 |
+
"bottom_region_index_tensor": bottom_region_index_tensor,
|
| 278 |
+
}
|
| 279 |
+
)
|
| 280 |
+
if include_modality:
|
| 281 |
+
unet_inputs.update(
|
| 282 |
+
{
|
| 283 |
+
"class_labels": modality_tensor,
|
| 284 |
+
}
|
| 285 |
+
)
|
| 286 |
+
model_output = unet(**unet_inputs)
|
| 287 |
+
|
| 288 |
+
if noise_scheduler.prediction_type == DDPMPredictionType.EPSILON:
|
| 289 |
+
# predict noise
|
| 290 |
+
model_gt = noise
|
| 291 |
+
elif noise_scheduler.prediction_type == DDPMPredictionType.SAMPLE:
|
| 292 |
+
# predict sample
|
| 293 |
+
model_gt = images
|
| 294 |
+
elif noise_scheduler.prediction_type == DDPMPredictionType.V_PREDICTION:
|
| 295 |
+
# predict velocity
|
| 296 |
+
model_gt = images - noise
|
| 297 |
+
else:
|
| 298 |
+
raise ValueError(
|
| 299 |
+
"noise scheduler prediction type has to be chosen from ",
|
| 300 |
+
f"[{DDPMPredictionType.EPSILON},{DDPMPredictionType.SAMPLE},{DDPMPredictionType.V_PREDICTION}]",
|
| 301 |
+
)
|
| 302 |
+
|
| 303 |
+
loss = loss_pt(model_output.float(), model_gt.float())
|
| 304 |
+
|
| 305 |
+
if amp:
|
| 306 |
+
scaler.scale(loss).backward()
|
| 307 |
+
scaler.step(optimizer)
|
| 308 |
+
scaler.update()
|
| 309 |
+
else:
|
| 310 |
+
loss.backward()
|
| 311 |
+
optimizer.step()
|
| 312 |
+
|
| 313 |
+
lr_scheduler.step()
|
| 314 |
+
|
| 315 |
+
loss_torch[0] += loss.item()
|
| 316 |
+
loss_torch[1] += 1.0
|
| 317 |
+
|
| 318 |
+
if local_rank == 0:
|
| 319 |
+
logger.info(
|
| 320 |
+
"[{0}] epoch {1}, iter {2}/{3}, loss: {4:.4f}, lr: {5:.12f}.".format(
|
| 321 |
+
str(datetime.now())[:19], epoch + 1, _iter, len(train_loader), loss.item(), current_lr
|
| 322 |
+
)
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
if dist.is_initialized():
|
| 326 |
+
dist.all_reduce(loss_torch, op=torch.distributed.ReduceOp.SUM)
|
| 327 |
+
|
| 328 |
+
return loss_torch
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
def save_checkpoint(
|
| 332 |
+
epoch: int,
|
| 333 |
+
unet: torch.nn.Module,
|
| 334 |
+
loss_torch_epoch: float,
|
| 335 |
+
num_train_timesteps: int,
|
| 336 |
+
scale_factor: torch.Tensor,
|
| 337 |
+
ckpt_folder: str,
|
| 338 |
+
args: argparse.Namespace,
|
| 339 |
+
) -> None:
|
| 340 |
+
"""
|
| 341 |
+
Save checkpoint.
|
| 342 |
+
|
| 343 |
+
Args:
|
| 344 |
+
epoch (int): Current epoch number.
|
| 345 |
+
unet (torch.nn.Module): UNet model.
|
| 346 |
+
loss_torch_epoch (float): Training loss for the epoch.
|
| 347 |
+
num_train_timesteps (int): Number of training timesteps.
|
| 348 |
+
scale_factor (torch.Tensor): Scaling factor.
|
| 349 |
+
ckpt_folder (str): Checkpoint folder path.
|
| 350 |
+
args (argparse.Namespace): Configuration arguments.
|
| 351 |
+
"""
|
| 352 |
+
unet_state_dict = unet.module.state_dict() if dist.is_initialized() else unet.state_dict()
|
| 353 |
+
torch.save(
|
| 354 |
+
{
|
| 355 |
+
"epoch": epoch + 1,
|
| 356 |
+
"loss": loss_torch_epoch,
|
| 357 |
+
"num_train_timesteps": num_train_timesteps,
|
| 358 |
+
"scale_factor": scale_factor,
|
| 359 |
+
"unet_state_dict": unet_state_dict,
|
| 360 |
+
},
|
| 361 |
+
f"{ckpt_folder}/{args.model_filename}",
|
| 362 |
+
)
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
def diff_model_train(
|
| 366 |
+
env_config_path: str, model_config_path: str, model_def_path: str, num_gpus: int, amp: bool = True
|
| 367 |
+
) -> None:
|
| 368 |
+
"""
|
| 369 |
+
Main function to train a diffusion model.
|
| 370 |
+
|
| 371 |
+
Args:
|
| 372 |
+
env_config_path (str): Path to the environment configuration file.
|
| 373 |
+
model_config_path (str): Path to the model configuration file.
|
| 374 |
+
model_def_path (str): Path to the model definition file.
|
| 375 |
+
num_gpus (int): Number of GPUs to use for training.
|
| 376 |
+
amp (bool): Use automatic mixed precision training.
|
| 377 |
+
"""
|
| 378 |
+
args = load_config(env_config_path, model_config_path, model_def_path)
|
| 379 |
+
local_rank, world_size, device = initialize_distributed(num_gpus)
|
| 380 |
+
logger = setup_logging("training")
|
| 381 |
+
|
| 382 |
+
logger.info(f"Using {device} of {world_size}")
|
| 383 |
+
|
| 384 |
+
if local_rank == 0:
|
| 385 |
+
logger.info(f"[config] ckpt_folder -> {args.model_dir}.")
|
| 386 |
+
logger.info(f"[config] data_root -> {args.embedding_base_dir}.")
|
| 387 |
+
logger.info(f"[config] data_list -> {args.json_data_list}.")
|
| 388 |
+
logger.info(f"[config] lr -> {args.diffusion_unet_train['lr']}.")
|
| 389 |
+
logger.info(f"[config] num_epochs -> {args.diffusion_unet_train['n_epochs']}.")
|
| 390 |
+
logger.info(f"[config] num_train_timesteps -> {args.noise_scheduler['num_train_timesteps']}.")
|
| 391 |
+
|
| 392 |
+
Path(args.model_dir).mkdir(parents=True, exist_ok=True)
|
| 393 |
+
|
| 394 |
+
unet = load_unet(args, device, logger)
|
| 395 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 396 |
+
include_body_region = unet.include_top_region_index_input
|
| 397 |
+
|
| 398 |
+
filenames_train = load_filenames(args.json_data_list)
|
| 399 |
+
if local_rank == 0:
|
| 400 |
+
logger.info(f"num_files_train: {len(filenames_train)}")
|
| 401 |
+
|
| 402 |
+
train_files = []
|
| 403 |
+
for _i in range(len(filenames_train)):
|
| 404 |
+
str_img = os.path.join(args.embedding_base_dir, filenames_train[_i])
|
| 405 |
+
if not os.path.exists(str_img):
|
| 406 |
+
continue
|
| 407 |
+
|
| 408 |
+
str_info = os.path.join(args.embedding_base_dir, filenames_train[_i]) + ".json"
|
| 409 |
+
train_files_i = {"image": str_img, "spacing": str_info}
|
| 410 |
+
if include_body_region:
|
| 411 |
+
train_files_i["top_region_index"] = str_info
|
| 412 |
+
train_files_i["bottom_region_index"] = str_info
|
| 413 |
+
train_files.append(train_files_i)
|
| 414 |
+
if dist.is_initialized():
|
| 415 |
+
train_files = partition_dataset(
|
| 416 |
+
data=train_files, shuffle=True, num_partitions=dist.get_world_size(), even_divisible=True
|
| 417 |
+
)[local_rank]
|
| 418 |
+
|
| 419 |
+
train_loader = prepare_data(
|
| 420 |
+
train_files,
|
| 421 |
+
device,
|
| 422 |
+
args.diffusion_unet_train["cache_rate"],
|
| 423 |
+
batch_size=args.diffusion_unet_train["batch_size"],
|
| 424 |
+
include_body_region=include_body_region,
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
scale_factor = calculate_scale_factor(train_loader, device, logger)
|
| 428 |
+
optimizer = create_optimizer(unet, args.diffusion_unet_train["lr"])
|
| 429 |
+
|
| 430 |
+
total_steps = (args.diffusion_unet_train["n_epochs"] * len(train_loader.dataset)) / args.diffusion_unet_train[
|
| 431 |
+
"batch_size"
|
| 432 |
+
]
|
| 433 |
+
lr_scheduler = create_lr_scheduler(optimizer, total_steps)
|
| 434 |
+
loss_pt = torch.nn.L1Loss()
|
| 435 |
+
scaler = GradScaler("cuda")
|
| 436 |
+
|
| 437 |
+
torch.set_float32_matmul_precision("highest")
|
| 438 |
+
logger.info("torch.set_float32_matmul_precision -> highest.")
|
| 439 |
+
|
| 440 |
+
for epoch in range(args.diffusion_unet_train["n_epochs"]):
|
| 441 |
+
loss_torch = train_one_epoch(
|
| 442 |
+
epoch,
|
| 443 |
+
unet,
|
| 444 |
+
train_loader,
|
| 445 |
+
optimizer,
|
| 446 |
+
lr_scheduler,
|
| 447 |
+
loss_pt,
|
| 448 |
+
scaler,
|
| 449 |
+
scale_factor,
|
| 450 |
+
noise_scheduler,
|
| 451 |
+
args.diffusion_unet_train["batch_size"],
|
| 452 |
+
args.noise_scheduler["num_train_timesteps"],
|
| 453 |
+
device,
|
| 454 |
+
logger,
|
| 455 |
+
local_rank,
|
| 456 |
+
amp=amp,
|
| 457 |
+
)
|
| 458 |
+
|
| 459 |
+
loss_torch = loss_torch.tolist()
|
| 460 |
+
if torch.cuda.device_count() == 1 or local_rank == 0:
|
| 461 |
+
loss_torch_epoch = loss_torch[0] / loss_torch[1]
|
| 462 |
+
logger.info(f"epoch {epoch + 1} average loss: {loss_torch_epoch:.4f}.")
|
| 463 |
+
|
| 464 |
+
save_checkpoint(
|
| 465 |
+
epoch,
|
| 466 |
+
unet,
|
| 467 |
+
loss_torch_epoch,
|
| 468 |
+
args.noise_scheduler["num_train_timesteps"],
|
| 469 |
+
scale_factor,
|
| 470 |
+
args.model_dir,
|
| 471 |
+
args,
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
if dist.is_initialized():
|
| 475 |
+
dist.destroy_process_group()
|
| 476 |
+
|
| 477 |
+
|
| 478 |
+
if __name__ == "__main__":
|
| 479 |
+
parser = argparse.ArgumentParser(description="Diffusion Model Training")
|
| 480 |
+
parser.add_argument(
|
| 481 |
+
"--env_config",
|
| 482 |
+
type=str,
|
| 483 |
+
default="./configs/environment_maisi_diff_model.json",
|
| 484 |
+
help="Path to environment configuration file",
|
| 485 |
+
)
|
| 486 |
+
parser.add_argument(
|
| 487 |
+
"--model_config",
|
| 488 |
+
type=str,
|
| 489 |
+
default="./configs/config_maisi_diff_model.json",
|
| 490 |
+
help="Path to model training/inference configuration",
|
| 491 |
+
)
|
| 492 |
+
parser.add_argument(
|
| 493 |
+
"--model_def", type=str, default="./configs/config_maisi.json", help="Path to model definition file"
|
| 494 |
+
)
|
| 495 |
+
parser.add_argument("--num_gpus", type=int, default=1, help="Number of GPUs to use for training")
|
| 496 |
+
parser.add_argument("--no_amp", dest="amp", action="store_false", help="Disable automatic mixed precision training")
|
| 497 |
+
|
| 498 |
+
args = parser.parse_args()
|
| 499 |
+
diff_model_train(args.env_config, args.model_config, args.model_def, args.num_gpus, args.amp)
|
scripts/find_masks.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
import json
|
| 14 |
+
import os
|
| 15 |
+
from typing import Sequence
|
| 16 |
+
|
| 17 |
+
from monai.apps.utils import extractall
|
| 18 |
+
from monai.utils import ensure_tuple_rep
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def convert_body_region(body_region: str | Sequence[str]) -> Sequence[int]:
|
| 22 |
+
"""
|
| 23 |
+
Convert body region string to body region index.
|
| 24 |
+
Args:
|
| 25 |
+
body_region: list of input body region string. If single str, will be converted to list of str.
|
| 26 |
+
Return:
|
| 27 |
+
body_region_indices, list of input body region index.
|
| 28 |
+
"""
|
| 29 |
+
if type(body_region) is str:
|
| 30 |
+
body_region = [body_region]
|
| 31 |
+
|
| 32 |
+
# body region mapping for maisi
|
| 33 |
+
region_mapping_maisi = {
|
| 34 |
+
"head": 0,
|
| 35 |
+
"chest": 1,
|
| 36 |
+
"thorax": 1,
|
| 37 |
+
"chest/thorax": 1,
|
| 38 |
+
"abdomen": 2,
|
| 39 |
+
"pelvis": 3,
|
| 40 |
+
"lower": 3,
|
| 41 |
+
"pelvis/lower": 3,
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
# perform mapping
|
| 45 |
+
body_region_indices = []
|
| 46 |
+
for region in body_region:
|
| 47 |
+
normalized_region = region.lower() # norm str to lower case
|
| 48 |
+
if normalized_region not in region_mapping_maisi:
|
| 49 |
+
raise ValueError(f"Invalid region: {normalized_region}")
|
| 50 |
+
body_region_indices.append(region_mapping_maisi[normalized_region])
|
| 51 |
+
|
| 52 |
+
return body_region_indices
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def find_masks(
|
| 56 |
+
body_region: str | Sequence[str],
|
| 57 |
+
anatomy_list: int | Sequence[int],
|
| 58 |
+
spacing: Sequence[float] | float = 1.0,
|
| 59 |
+
output_size: Sequence[int] = [512, 512, 512],
|
| 60 |
+
check_spacing_and_output_size: bool = False,
|
| 61 |
+
database_filepath: str = "./configs/database.json",
|
| 62 |
+
mask_foldername: str = "./datasets/masks/",
|
| 63 |
+
):
|
| 64 |
+
"""
|
| 65 |
+
Find candidate masks that fullfills all the requirements.
|
| 66 |
+
They shoud contain all the body region in `body_region`, all the anatomies in `anatomy_list`.
|
| 67 |
+
If there is no tumor specified in `anatomy_list`, we also expect the candidate masks to be tumor free.
|
| 68 |
+
If check_spacing_and_output_size is True, the candidate masks need to have the expected `spacing` and `output_size`.
|
| 69 |
+
Args:
|
| 70 |
+
body_region: list of input body region string. If single str, will be converted to list of str.
|
| 71 |
+
The found candidate mask will include these body regions.
|
| 72 |
+
anatomy_list: list of input anatomy. The found candidate mask will include these anatomies.
|
| 73 |
+
spacing: list of three floats, voxel spacing. If providing a single number, will use it for all the three dimensions.
|
| 74 |
+
output_size: list of three int, expected candidate mask spatial size.
|
| 75 |
+
check_spacing_and_output_size: whether we expect candidate mask to have spatial size of `output_size` and voxel size of `spacing`.
|
| 76 |
+
database_filepath: path for the json file that stores the information of all the candidate masks.
|
| 77 |
+
mask_foldername: directory that saves all the candidate masks.
|
| 78 |
+
Return:
|
| 79 |
+
candidate_masks, list of dict, each dict contains information of one candidate mask that fullfills all the requirements.
|
| 80 |
+
"""
|
| 81 |
+
# check and preprocess input
|
| 82 |
+
body_region = convert_body_region(body_region)
|
| 83 |
+
|
| 84 |
+
if isinstance(anatomy_list, int):
|
| 85 |
+
anatomy_list = [anatomy_list]
|
| 86 |
+
|
| 87 |
+
spacing = ensure_tuple_rep(spacing, 3)
|
| 88 |
+
|
| 89 |
+
if not os.path.exists(mask_foldername):
|
| 90 |
+
zip_file_path = mask_foldername + ".zip"
|
| 91 |
+
|
| 92 |
+
if not os.path.isfile(zip_file_path):
|
| 93 |
+
raise ValueError(f"Please download {zip_file_path} following the instruction in ./datasets/README.md.")
|
| 94 |
+
|
| 95 |
+
print(f"Extracting {zip_file_path} to {os.path.dirname(zip_file_path)}")
|
| 96 |
+
extractall(filepath=zip_file_path, output_dir=os.path.dirname(zip_file_path), file_type="zip")
|
| 97 |
+
print(f"Unzipped {zip_file_path} to {mask_foldername}.")
|
| 98 |
+
|
| 99 |
+
if not os.path.isfile(database_filepath):
|
| 100 |
+
raise ValueError(f"Please download {database_filepath} following the instruction in ./datasets/README.md.")
|
| 101 |
+
with open(database_filepath, "r") as f:
|
| 102 |
+
db = json.load(f)
|
| 103 |
+
|
| 104 |
+
# select candidate_masks
|
| 105 |
+
candidate_masks = []
|
| 106 |
+
for _item in db:
|
| 107 |
+
if not set(anatomy_list).issubset(_item["label_list"]):
|
| 108 |
+
continue
|
| 109 |
+
|
| 110 |
+
# whether to keep this mask, default to be True.
|
| 111 |
+
keep_mask = True
|
| 112 |
+
|
| 113 |
+
# extract region indice (top_index and bottom_index) for candidate mask
|
| 114 |
+
include_body_region = "top_region_index" in _item.keys()
|
| 115 |
+
if include_body_region:
|
| 116 |
+
top_index = [index for index, element in enumerate(_item["top_region_index"]) if element != 0]
|
| 117 |
+
top_index = top_index[0]
|
| 118 |
+
bottom_index = [index for index, element in enumerate(_item["bottom_region_index"]) if element != 0]
|
| 119 |
+
bottom_index = bottom_index[0]
|
| 120 |
+
|
| 121 |
+
# if candiate mask does not contain all the body_region, skip it
|
| 122 |
+
for _idx in body_region:
|
| 123 |
+
if _idx > bottom_index or _idx < top_index:
|
| 124 |
+
keep_mask = False
|
| 125 |
+
|
| 126 |
+
for tumor_label in [23, 24, 26, 27, 128]:
|
| 127 |
+
# we skip those mask with tumors if users do not provide tumor label in anatomy_list
|
| 128 |
+
if tumor_label not in anatomy_list and tumor_label in _item["label_list"]:
|
| 129 |
+
keep_mask = False
|
| 130 |
+
|
| 131 |
+
if check_spacing_and_output_size:
|
| 132 |
+
# if the output_size and spacing are different with user's input, skip it
|
| 133 |
+
for axis in range(3):
|
| 134 |
+
if _item["dim"][axis] != output_size[axis] or _item["spacing"][axis] != spacing[axis]:
|
| 135 |
+
keep_mask = False
|
| 136 |
+
|
| 137 |
+
if keep_mask:
|
| 138 |
+
# if decide to keep this mask, we pack the information of this mask and add to final output.
|
| 139 |
+
candidate = {
|
| 140 |
+
"pseudo_label": os.path.join(mask_foldername, _item["pseudo_label_filename"]),
|
| 141 |
+
"spacing": _item["spacing"],
|
| 142 |
+
"dim": _item["dim"],
|
| 143 |
+
}
|
| 144 |
+
if include_body_region:
|
| 145 |
+
candidate["top_region_index"] = _item["top_region_index"]
|
| 146 |
+
candidate["bottom_region_index"] = _item["bottom_region_index"]
|
| 147 |
+
|
| 148 |
+
# Conditionally add the label to the candidate dictionary
|
| 149 |
+
if "label_filename" in _item:
|
| 150 |
+
candidate["label"] = os.path.join(mask_foldername, _item["label_filename"])
|
| 151 |
+
|
| 152 |
+
candidate_masks.append(candidate)
|
| 153 |
+
|
| 154 |
+
if len(candidate_masks) == 0 and not check_spacing_and_output_size:
|
| 155 |
+
raise ValueError("Cannot find body region with given anatomy list.")
|
| 156 |
+
|
| 157 |
+
return candidate_masks
|
scripts/infer_controlnet.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import json
|
| 14 |
+
import logging
|
| 15 |
+
import os
|
| 16 |
+
import sys
|
| 17 |
+
from datetime import datetime
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.distributed as dist
|
| 21 |
+
from monai.data import MetaTensor, decollate_batch
|
| 22 |
+
from monai.networks.utils import copy_model_state
|
| 23 |
+
from monai.transforms import SaveImage
|
| 24 |
+
from monai.utils import RankFilter
|
| 25 |
+
|
| 26 |
+
from .sample import check_input, ldm_conditional_sample_one_image
|
| 27 |
+
from .utils import define_instance, prepare_maisi_controlnet_json_dataloader, setup_ddp
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@torch.inference_mode()
|
| 31 |
+
def main():
|
| 32 |
+
parser = argparse.ArgumentParser(description="maisi.controlnet.infer")
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"-e",
|
| 35 |
+
"--environment-file",
|
| 36 |
+
default="./configs/environment_maisi_controlnet_train.json",
|
| 37 |
+
help="environment json file that stores environment path",
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"-c",
|
| 41 |
+
"--config-file",
|
| 42 |
+
default="./configs/config_maisi.json",
|
| 43 |
+
help="config json file that stores network hyper-parameters",
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"-t",
|
| 47 |
+
"--training-config",
|
| 48 |
+
default="./configs/config_maisi_controlnet_train.json",
|
| 49 |
+
help="config json file that stores training hyper-parameters",
|
| 50 |
+
)
|
| 51 |
+
parser.add_argument("-g", "--gpus", default=1, type=int, help="number of gpus per node")
|
| 52 |
+
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
|
| 55 |
+
# Step 0: configuration
|
| 56 |
+
logger = logging.getLogger("maisi.controlnet.infer")
|
| 57 |
+
# whether to use distributed data parallel
|
| 58 |
+
use_ddp = args.gpus > 1
|
| 59 |
+
if use_ddp:
|
| 60 |
+
rank = int(os.environ["LOCAL_RANK"])
|
| 61 |
+
world_size = int(os.environ["WORLD_SIZE"])
|
| 62 |
+
device = setup_ddp(rank, world_size)
|
| 63 |
+
logger.addFilter(RankFilter())
|
| 64 |
+
else:
|
| 65 |
+
rank = 0
|
| 66 |
+
world_size = 1
|
| 67 |
+
device = torch.device(f"cuda:{rank}")
|
| 68 |
+
|
| 69 |
+
torch.cuda.set_device(device)
|
| 70 |
+
logger.info(f"Number of GPUs: {torch.cuda.device_count()}")
|
| 71 |
+
logger.info(f"World_size: {world_size}")
|
| 72 |
+
|
| 73 |
+
with open(args.environment_file, "r") as env_file:
|
| 74 |
+
env_dict = json.load(env_file)
|
| 75 |
+
with open(args.config_file, "r") as config_file:
|
| 76 |
+
config_dict = json.load(config_file)
|
| 77 |
+
with open(args.training_config, "r") as training_config_file:
|
| 78 |
+
training_config_dict = json.load(training_config_file)
|
| 79 |
+
|
| 80 |
+
for k, v in env_dict.items():
|
| 81 |
+
setattr(args, k, v)
|
| 82 |
+
for k, v in config_dict.items():
|
| 83 |
+
setattr(args, k, v)
|
| 84 |
+
for k, v in training_config_dict.items():
|
| 85 |
+
setattr(args, k, v)
|
| 86 |
+
|
| 87 |
+
# Step 1: set data loader
|
| 88 |
+
_, val_loader = prepare_maisi_controlnet_json_dataloader(
|
| 89 |
+
json_data_list=args.json_data_list,
|
| 90 |
+
data_base_dir=args.data_base_dir,
|
| 91 |
+
rank=rank,
|
| 92 |
+
world_size=world_size,
|
| 93 |
+
batch_size=args.controlnet_train["batch_size"],
|
| 94 |
+
cache_rate=args.controlnet_train["cache_rate"],
|
| 95 |
+
fold=args.controlnet_train["fold"],
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
# Step 2: define AE, diffusion model and controlnet
|
| 99 |
+
# define AE
|
| 100 |
+
autoencoder = define_instance(args, "autoencoder_def").to(device)
|
| 101 |
+
# load trained autoencoder model
|
| 102 |
+
if args.trained_autoencoder_path is not None:
|
| 103 |
+
if not os.path.exists(args.trained_autoencoder_path):
|
| 104 |
+
raise ValueError("Please download the autoencoder checkpoint.")
|
| 105 |
+
autoencoder_ckpt = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 106 |
+
autoencoder.load_state_dict(autoencoder_ckpt)
|
| 107 |
+
logger.info(f"Load trained diffusion model from {args.trained_autoencoder_path}.")
|
| 108 |
+
else:
|
| 109 |
+
logger.info("trained autoencoder model is not loaded.")
|
| 110 |
+
|
| 111 |
+
# define diffusion Model
|
| 112 |
+
unet = define_instance(args, "diffusion_unet_def").to(device)
|
| 113 |
+
include_body_region = unet.include_top_region_index_input
|
| 114 |
+
include_modality = unet.num_class_embeds is not None
|
| 115 |
+
|
| 116 |
+
# load trained diffusion model
|
| 117 |
+
if args.trained_diffusion_path is not None:
|
| 118 |
+
if not os.path.exists(args.trained_diffusion_path):
|
| 119 |
+
raise ValueError("Please download the trained diffusion unet checkpoint.")
|
| 120 |
+
diffusion_model_ckpt = torch.load(args.trained_diffusion_path, map_location=device, weights_only=False)
|
| 121 |
+
unet.load_state_dict(diffusion_model_ckpt["unet_state_dict"])
|
| 122 |
+
# load scale factor from diffusion model checkpoint
|
| 123 |
+
scale_factor = diffusion_model_ckpt["scale_factor"]
|
| 124 |
+
logger.info(f"Load trained diffusion model from {args.trained_diffusion_path}.")
|
| 125 |
+
logger.info(f"loaded scale_factor from diffusion model ckpt -> {scale_factor}.")
|
| 126 |
+
else:
|
| 127 |
+
logger.info("trained diffusion model is not loaded.")
|
| 128 |
+
scale_factor = 1.0
|
| 129 |
+
logger.info(f"set scale_factor -> {scale_factor}.")
|
| 130 |
+
|
| 131 |
+
# define ControlNet
|
| 132 |
+
controlnet = define_instance(args, "controlnet_def").to(device)
|
| 133 |
+
# copy weights from the DM to the controlnet
|
| 134 |
+
copy_model_state(controlnet, unet.state_dict())
|
| 135 |
+
# load trained controlnet model if it is provided
|
| 136 |
+
if args.trained_controlnet_path is not None:
|
| 137 |
+
if not os.path.exists(args.trained_controlnet_path):
|
| 138 |
+
raise ValueError("Please download the trained ControlNet checkpoint.")
|
| 139 |
+
controlnet.load_state_dict(
|
| 140 |
+
torch.load(args.trained_controlnet_path, map_location=device, weights_only=False)["controlnet_state_dict"]
|
| 141 |
+
)
|
| 142 |
+
logger.info(f"load trained controlnet model from {args.trained_controlnet_path}")
|
| 143 |
+
else:
|
| 144 |
+
logger.info("trained controlnet is not loaded.")
|
| 145 |
+
|
| 146 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 147 |
+
|
| 148 |
+
# Step 3: inference
|
| 149 |
+
autoencoder.eval()
|
| 150 |
+
controlnet.eval()
|
| 151 |
+
unet.eval()
|
| 152 |
+
|
| 153 |
+
for batch in val_loader:
|
| 154 |
+
|
| 155 |
+
# get label mask
|
| 156 |
+
labels = batch["label"].to(device)
|
| 157 |
+
# get corresponding conditions
|
| 158 |
+
if include_body_region:
|
| 159 |
+
top_region_index_tensor = batch["top_region_index"].to(device)
|
| 160 |
+
bottom_region_index_tensor = batch["bottom_region_index"].to(device)
|
| 161 |
+
else:
|
| 162 |
+
top_region_index_tensor = None
|
| 163 |
+
bottom_region_index_tensor = None
|
| 164 |
+
spacing_tensor = batch["spacing"].to(device)
|
| 165 |
+
modality_tensor = args.controlnet_infer["modality"] * torch.ones((len(labels),), dtype=torch.long).to(device)
|
| 166 |
+
out_spacing = tuple((batch["spacing"].squeeze().numpy() / 100).tolist())
|
| 167 |
+
# get target dimension
|
| 168 |
+
dim = batch["dim"]
|
| 169 |
+
output_size = (dim[0].item(), dim[1].item(), dim[2].item())
|
| 170 |
+
latent_shape = (args.latent_channels, output_size[0] // 4, output_size[1] // 4, output_size[2] // 4)
|
| 171 |
+
# check if output_size and out_spacing are valid.
|
| 172 |
+
check_input(None, None, None, output_size, out_spacing, None)
|
| 173 |
+
# generate a single synthetic image using a latent diffusion model with controlnet.
|
| 174 |
+
synthetic_images, _ = ldm_conditional_sample_one_image(
|
| 175 |
+
autoencoder=autoencoder,
|
| 176 |
+
diffusion_unet=unet,
|
| 177 |
+
controlnet=controlnet,
|
| 178 |
+
noise_scheduler=noise_scheduler,
|
| 179 |
+
scale_factor=scale_factor,
|
| 180 |
+
device=device,
|
| 181 |
+
combine_label_or=labels,
|
| 182 |
+
top_region_index_tensor=top_region_index_tensor,
|
| 183 |
+
bottom_region_index_tensor=bottom_region_index_tensor,
|
| 184 |
+
spacing_tensor=spacing_tensor,
|
| 185 |
+
modality_tensor=modality_tensor,
|
| 186 |
+
latent_shape=latent_shape,
|
| 187 |
+
output_size=output_size,
|
| 188 |
+
noise_factor=1.0,
|
| 189 |
+
num_inference_steps=args.controlnet_infer["num_inference_steps"],
|
| 190 |
+
autoencoder_sliding_window_infer_size=args.controlnet_infer["autoencoder_sliding_window_infer_size"],
|
| 191 |
+
autoencoder_sliding_window_infer_overlap=args.controlnet_infer["autoencoder_sliding_window_infer_overlap"],
|
| 192 |
+
)
|
| 193 |
+
# save image/label pairs
|
| 194 |
+
labels = decollate_batch(batch)[0]["label"]
|
| 195 |
+
real_object_name = labels.meta.get("filename_or_obj", "default_name.nii.gz")
|
| 196 |
+
labels.meta["filename_or_obj"] = real_object_name
|
| 197 |
+
output_postfix = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 198 |
+
synthetic_images = MetaTensor(synthetic_images.squeeze(0), meta=labels.meta)
|
| 199 |
+
img_saver = SaveImage(
|
| 200 |
+
output_dir=args.output_dir,
|
| 201 |
+
output_postfix="image",
|
| 202 |
+
separate_folder=False,
|
| 203 |
+
)
|
| 204 |
+
img_saver(synthetic_images)
|
| 205 |
+
label_saver = SaveImage(
|
| 206 |
+
output_dir=args.output_dir,
|
| 207 |
+
output_postfix="label",
|
| 208 |
+
separate_folder=False,
|
| 209 |
+
)
|
| 210 |
+
label_saver(labels)
|
| 211 |
+
if use_ddp:
|
| 212 |
+
dist.destroy_process_group()
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
if __name__ == "__main__":
|
| 216 |
+
logging.basicConfig(
|
| 217 |
+
stream=sys.stdout,
|
| 218 |
+
level=logging.INFO,
|
| 219 |
+
format="[%(asctime)s.%(msecs)03d][%(levelname)5s](%(name)s) - %(message)s",
|
| 220 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 221 |
+
)
|
| 222 |
+
main()
|
scripts/infer_testV2_controlnet.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import json
|
| 14 |
+
import logging
|
| 15 |
+
import os
|
| 16 |
+
import sys
|
| 17 |
+
from datetime import datetime
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.distributed as dist
|
| 21 |
+
from monai.data import MetaTensor, decollate_batch
|
| 22 |
+
from monai.networks.utils import copy_model_state
|
| 23 |
+
from monai.transforms import SaveImage
|
| 24 |
+
from monai.utils import RankFilter
|
| 25 |
+
|
| 26 |
+
from .sample import check_input, ldm_conditional_sample_one_image
|
| 27 |
+
from .utils import define_instance, prepare_maisi_controlnet_json_dataloader, setup_ddp, prepare_maisi_controlnet_test_dataloader
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@torch.inference_mode()
|
| 31 |
+
def main():
|
| 32 |
+
parser = argparse.ArgumentParser(description="maisi.controlnet.infer")
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"-e",
|
| 35 |
+
"--environment-file",
|
| 36 |
+
default="./configs/environment_maisi_controlnet_train.json",
|
| 37 |
+
help="environment json file that stores environment path",
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"-c",
|
| 41 |
+
"--config-file",
|
| 42 |
+
default="./configs/config_maisi.json",
|
| 43 |
+
help="config json file that stores network hyper-parameters",
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"-t",
|
| 47 |
+
"--training-config",
|
| 48 |
+
default="./configs/config_maisi_controlnet_train.json",
|
| 49 |
+
help="config json file that stores training hyper-parameters",
|
| 50 |
+
)
|
| 51 |
+
parser.add_argument("-g", "--gpus", default=1, type=int, help="number of gpus per node")
|
| 52 |
+
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
|
| 55 |
+
# Step 0: configuration
|
| 56 |
+
logger = logging.getLogger("maisi.controlnet.infer")
|
| 57 |
+
# whether to use distributed data parallel
|
| 58 |
+
use_ddp = args.gpus > 1
|
| 59 |
+
if use_ddp:
|
| 60 |
+
rank = int(os.environ["LOCAL_RANK"])
|
| 61 |
+
world_size = int(os.environ["WORLD_SIZE"])
|
| 62 |
+
device = setup_ddp(rank, world_size)
|
| 63 |
+
logger.addFilter(RankFilter())
|
| 64 |
+
else:
|
| 65 |
+
rank = 0
|
| 66 |
+
world_size = 1
|
| 67 |
+
device = torch.device(f"cuda:{rank}")
|
| 68 |
+
|
| 69 |
+
torch.cuda.set_device(device)
|
| 70 |
+
logger.info(f"Number of GPUs: {torch.cuda.device_count()}")
|
| 71 |
+
logger.info(f"World_size: {world_size}")
|
| 72 |
+
|
| 73 |
+
with open(args.environment_file, "r") as env_file:
|
| 74 |
+
env_dict = json.load(env_file)
|
| 75 |
+
with open(args.config_file, "r") as config_file:
|
| 76 |
+
config_dict = json.load(config_file)
|
| 77 |
+
with open(args.training_config, "r") as training_config_file:
|
| 78 |
+
training_config_dict = json.load(training_config_file)
|
| 79 |
+
|
| 80 |
+
for k, v in env_dict.items():
|
| 81 |
+
setattr(args, k, v)
|
| 82 |
+
for k, v in config_dict.items():
|
| 83 |
+
setattr(args, k, v)
|
| 84 |
+
for k, v in training_config_dict.items():
|
| 85 |
+
setattr(args, k, v)
|
| 86 |
+
|
| 87 |
+
# Step 1: set data loader
|
| 88 |
+
val_loader = prepare_maisi_controlnet_test_dataloader(
|
| 89 |
+
json_data_list=args.json_data_list,
|
| 90 |
+
data_base_dir=args.data_base_dir,
|
| 91 |
+
batch_size=args.controlnet_train["batch_size"],
|
| 92 |
+
cache_rate=args.controlnet_train["cache_rate"],
|
| 93 |
+
rank=rank,
|
| 94 |
+
world_size=world_size,)
|
| 95 |
+
|
| 96 |
+
# Step 2: define AE, diffusion model and controlnet
|
| 97 |
+
# define AE
|
| 98 |
+
autoencoder = define_instance(args, "autoencoder_def").to(device)
|
| 99 |
+
# load trained autoencoder model
|
| 100 |
+
if args.trained_autoencoder_path is not None:
|
| 101 |
+
if not os.path.exists(args.trained_autoencoder_path):
|
| 102 |
+
raise ValueError("Please download the autoencoder checkpoint.")
|
| 103 |
+
autoencoder_ckpt = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 104 |
+
autoencoder.load_state_dict(autoencoder_ckpt)
|
| 105 |
+
logger.info(f"Load trained diffusion model from {args.trained_autoencoder_path}.")
|
| 106 |
+
else:
|
| 107 |
+
logger.info("trained autoencoder model is not loaded.")
|
| 108 |
+
|
| 109 |
+
# define diffusion Model
|
| 110 |
+
unet = define_instance(args, "diffusion_unet_def").to(device)
|
| 111 |
+
include_body_region = unet.include_top_region_index_input
|
| 112 |
+
include_modality = unet.num_class_embeds is not None
|
| 113 |
+
|
| 114 |
+
# load trained diffusion model
|
| 115 |
+
if args.trained_diffusion_path is not None:
|
| 116 |
+
if not os.path.exists(args.trained_diffusion_path):
|
| 117 |
+
raise ValueError("Please download the trained diffusion unet checkpoint.")
|
| 118 |
+
diffusion_model_ckpt = torch.load(args.trained_diffusion_path, map_location=device, weights_only=False)
|
| 119 |
+
unet.load_state_dict(diffusion_model_ckpt["unet_state_dict"])
|
| 120 |
+
# load scale factor from diffusion model checkpoint
|
| 121 |
+
scale_factor = diffusion_model_ckpt["scale_factor"]
|
| 122 |
+
logger.info(f"Load trained diffusion model from {args.trained_diffusion_path}.")
|
| 123 |
+
logger.info(f"loaded scale_factor from diffusion model ckpt -> {scale_factor}.")
|
| 124 |
+
else:
|
| 125 |
+
logger.info("trained diffusion model is not loaded.")
|
| 126 |
+
scale_factor = 1.0
|
| 127 |
+
logger.info(f"set scale_factor -> {scale_factor}.")
|
| 128 |
+
|
| 129 |
+
# define ControlNet
|
| 130 |
+
controlnet = define_instance(args, "controlnet_def").to(device)
|
| 131 |
+
# copy weights from the DM to the controlnet
|
| 132 |
+
copy_model_state(controlnet, unet.state_dict())
|
| 133 |
+
# load trained controlnet model if it is provided
|
| 134 |
+
if args.trained_controlnet_path is not None:
|
| 135 |
+
if not os.path.exists(args.trained_controlnet_path):
|
| 136 |
+
raise ValueError("Please download the trained ControlNet checkpoint.")
|
| 137 |
+
controlnet.load_state_dict(
|
| 138 |
+
torch.load(args.trained_controlnet_path, map_location=device, weights_only=False)["controlnet_state_dict"]
|
| 139 |
+
)
|
| 140 |
+
logger.info(f"load trained controlnet model from {args.trained_controlnet_path}")
|
| 141 |
+
else:
|
| 142 |
+
logger.info("trained controlnet is not loaded.")
|
| 143 |
+
|
| 144 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 145 |
+
|
| 146 |
+
# Step 3: inference
|
| 147 |
+
autoencoder.eval()
|
| 148 |
+
controlnet.eval()
|
| 149 |
+
unet.eval()
|
| 150 |
+
|
| 151 |
+
for batch in val_loader:
|
| 152 |
+
|
| 153 |
+
# get label mask
|
| 154 |
+
labels = batch["label"].to(device)
|
| 155 |
+
# get corresponding conditions
|
| 156 |
+
if include_body_region:
|
| 157 |
+
top_region_index_tensor = batch["top_region_index"].to(device)
|
| 158 |
+
bottom_region_index_tensor = batch["bottom_region_index"].to(device)
|
| 159 |
+
else:
|
| 160 |
+
top_region_index_tensor = None
|
| 161 |
+
bottom_region_index_tensor = None
|
| 162 |
+
spacing_tensor = batch["spacing"].to(device)
|
| 163 |
+
modality_tensor = args.controlnet_infer["modality"] * torch.ones((len(labels),), dtype=torch.long).to(device)
|
| 164 |
+
out_spacing = tuple((batch["spacing"].squeeze().numpy() / 100).tolist())
|
| 165 |
+
# get target dimension
|
| 166 |
+
dim = batch["dim"]
|
| 167 |
+
output_size = (dim[0].item(), dim[1].item(), dim[2].item())
|
| 168 |
+
latent_shape = (args.latent_channels, output_size[0] // 4, output_size[1] // 4, output_size[2] // 4)
|
| 169 |
+
# check if output_size and out_spacing are valid.
|
| 170 |
+
check_input(None, None, None, output_size, out_spacing, None)
|
| 171 |
+
# generate a single synthetic image using a latent diffusion model with controlnet.
|
| 172 |
+
synthetic_images, _ = ldm_conditional_sample_one_image(
|
| 173 |
+
autoencoder=autoencoder,
|
| 174 |
+
diffusion_unet=unet,
|
| 175 |
+
controlnet=controlnet,
|
| 176 |
+
noise_scheduler=noise_scheduler,
|
| 177 |
+
scale_factor=scale_factor,
|
| 178 |
+
device=device,
|
| 179 |
+
combine_label_or=labels,
|
| 180 |
+
top_region_index_tensor=top_region_index_tensor,
|
| 181 |
+
bottom_region_index_tensor=bottom_region_index_tensor,
|
| 182 |
+
spacing_tensor=spacing_tensor,
|
| 183 |
+
modality_tensor=modality_tensor,
|
| 184 |
+
latent_shape=latent_shape,
|
| 185 |
+
output_size=output_size,
|
| 186 |
+
noise_factor=1.0,
|
| 187 |
+
num_inference_steps=args.controlnet_infer["num_inference_steps"],
|
| 188 |
+
autoencoder_sliding_window_infer_size=args.controlnet_infer["autoencoder_sliding_window_infer_size"],
|
| 189 |
+
autoencoder_sliding_window_infer_overlap=args.controlnet_infer["autoencoder_sliding_window_infer_overlap"],
|
| 190 |
+
)
|
| 191 |
+
# save image/label pairs
|
| 192 |
+
labels = decollate_batch(batch)[0]["label"]
|
| 193 |
+
real_object_name = labels.meta.get("filename_or_obj", "default_name.nii.gz")
|
| 194 |
+
labels.meta["filename_or_obj"] = real_object_name
|
| 195 |
+
output_postfix = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 196 |
+
synthetic_images = MetaTensor(synthetic_images.squeeze(0), meta=labels.meta)
|
| 197 |
+
img_saver = SaveImage(
|
| 198 |
+
output_dir=args.output_dir,
|
| 199 |
+
output_postfix="image",
|
| 200 |
+
separate_folder=False,
|
| 201 |
+
)
|
| 202 |
+
img_saver(synthetic_images)
|
| 203 |
+
label_saver = SaveImage(
|
| 204 |
+
output_dir=args.output_dir,
|
| 205 |
+
output_postfix="label",
|
| 206 |
+
separate_folder=False,
|
| 207 |
+
)
|
| 208 |
+
label_saver(labels)
|
| 209 |
+
if use_ddp:
|
| 210 |
+
dist.destroy_process_group()
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
if __name__ == "__main__":
|
| 214 |
+
logging.basicConfig(
|
| 215 |
+
stream=sys.stdout,
|
| 216 |
+
level=logging.INFO,
|
| 217 |
+
format="[%(asctime)s.%(msecs)03d][%(levelname)5s](%(name)s) - %(message)s",
|
| 218 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 219 |
+
)
|
| 220 |
+
main()
|
scripts/infer_test_controlnet.py
ADDED
|
@@ -0,0 +1,220 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import argparse
|
| 13 |
+
import json
|
| 14 |
+
import logging
|
| 15 |
+
import os
|
| 16 |
+
import sys
|
| 17 |
+
from datetime import datetime
|
| 18 |
+
|
| 19 |
+
import torch
|
| 20 |
+
import torch.distributed as dist
|
| 21 |
+
from monai.data import MetaTensor, decollate_batch
|
| 22 |
+
from monai.networks.utils import copy_model_state
|
| 23 |
+
from monai.transforms import SaveImage
|
| 24 |
+
from monai.utils import RankFilter
|
| 25 |
+
|
| 26 |
+
from .sample import check_input, ldm_conditional_sample_one_image
|
| 27 |
+
from .utils import define_instance, prepare_maisi_controlnet_json_dataloader, setup_ddp, prepare_maisi_controlnet_infer_dataloader
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@torch.inference_mode()
|
| 31 |
+
def main():
|
| 32 |
+
parser = argparse.ArgumentParser(description="maisi.controlnet.infer")
|
| 33 |
+
parser.add_argument(
|
| 34 |
+
"-e",
|
| 35 |
+
"--environment-file",
|
| 36 |
+
default="./configs/environment_maisi_controlnet_train.json",
|
| 37 |
+
help="environment json file that stores environment path",
|
| 38 |
+
)
|
| 39 |
+
parser.add_argument(
|
| 40 |
+
"-c",
|
| 41 |
+
"--config-file",
|
| 42 |
+
default="./configs/config_maisi.json",
|
| 43 |
+
help="config json file that stores network hyper-parameters",
|
| 44 |
+
)
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"-t",
|
| 47 |
+
"--training-config",
|
| 48 |
+
default="./configs/config_maisi_controlnet_train.json",
|
| 49 |
+
help="config json file that stores training hyper-parameters",
|
| 50 |
+
)
|
| 51 |
+
parser.add_argument("-g", "--gpus", default=1, type=int, help="number of gpus per node")
|
| 52 |
+
|
| 53 |
+
args = parser.parse_args()
|
| 54 |
+
|
| 55 |
+
# Step 0: configuration
|
| 56 |
+
logger = logging.getLogger("maisi.controlnet.infer")
|
| 57 |
+
# whether to use distributed data parallel
|
| 58 |
+
use_ddp = args.gpus > 1
|
| 59 |
+
if use_ddp:
|
| 60 |
+
rank = int(os.environ["LOCAL_RANK"])
|
| 61 |
+
world_size = int(os.environ["WORLD_SIZE"])
|
| 62 |
+
device = setup_ddp(rank, world_size)
|
| 63 |
+
logger.addFilter(RankFilter())
|
| 64 |
+
else:
|
| 65 |
+
rank = 0
|
| 66 |
+
world_size = 1
|
| 67 |
+
device = torch.device(f"cuda:{rank}")
|
| 68 |
+
|
| 69 |
+
torch.cuda.set_device(device)
|
| 70 |
+
logger.info(f"Number of GPUs: {torch.cuda.device_count()}")
|
| 71 |
+
logger.info(f"World_size: {world_size}")
|
| 72 |
+
|
| 73 |
+
with open(args.environment_file, "r") as env_file:
|
| 74 |
+
env_dict = json.load(env_file)
|
| 75 |
+
with open(args.config_file, "r") as config_file:
|
| 76 |
+
config_dict = json.load(config_file)
|
| 77 |
+
with open(args.training_config, "r") as training_config_file:
|
| 78 |
+
training_config_dict = json.load(training_config_file)
|
| 79 |
+
|
| 80 |
+
for k, v in env_dict.items():
|
| 81 |
+
setattr(args, k, v)
|
| 82 |
+
for k, v in config_dict.items():
|
| 83 |
+
setattr(args, k, v)
|
| 84 |
+
for k, v in training_config_dict.items():
|
| 85 |
+
setattr(args, k, v)
|
| 86 |
+
|
| 87 |
+
# Step 1: set data loader
|
| 88 |
+
val_loader = prepare_maisi_controlnet_infer_dataloader(
|
| 89 |
+
json_data_list=args.json_data_list,
|
| 90 |
+
data_base_dir=args.data_base_dir,
|
| 91 |
+
batch_size=args.controlnet_train["batch_size"],
|
| 92 |
+
cache_rate=args.controlnet_train["cache_rate"],
|
| 93 |
+
rank=rank,
|
| 94 |
+
world_size=world_size,)
|
| 95 |
+
|
| 96 |
+
# Step 2: define AE, diffusion model and controlnet
|
| 97 |
+
# define AE
|
| 98 |
+
autoencoder = define_instance(args, "autoencoder_def").to(device)
|
| 99 |
+
# load trained autoencoder model
|
| 100 |
+
if args.trained_autoencoder_path is not None:
|
| 101 |
+
if not os.path.exists(args.trained_autoencoder_path):
|
| 102 |
+
raise ValueError("Please download the autoencoder checkpoint.")
|
| 103 |
+
autoencoder_ckpt = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 104 |
+
autoencoder.load_state_dict(autoencoder_ckpt)
|
| 105 |
+
logger.info(f"Load trained diffusion model from {args.trained_autoencoder_path}.")
|
| 106 |
+
else:
|
| 107 |
+
logger.info("trained autoencoder model is not loaded.")
|
| 108 |
+
|
| 109 |
+
# define diffusion Model
|
| 110 |
+
unet = define_instance(args, "diffusion_unet_def").to(device)
|
| 111 |
+
include_body_region = unet.include_top_region_index_input
|
| 112 |
+
include_modality = unet.num_class_embeds is not None
|
| 113 |
+
|
| 114 |
+
# load trained diffusion model
|
| 115 |
+
if args.trained_diffusion_path is not None:
|
| 116 |
+
if not os.path.exists(args.trained_diffusion_path):
|
| 117 |
+
raise ValueError("Please download the trained diffusion unet checkpoint.")
|
| 118 |
+
diffusion_model_ckpt = torch.load(args.trained_diffusion_path, map_location=device, weights_only=False)
|
| 119 |
+
unet.load_state_dict(diffusion_model_ckpt["unet_state_dict"])
|
| 120 |
+
# load scale factor from diffusion model checkpoint
|
| 121 |
+
scale_factor = diffusion_model_ckpt["scale_factor"]
|
| 122 |
+
logger.info(f"Load trained diffusion model from {args.trained_diffusion_path}.")
|
| 123 |
+
logger.info(f"loaded scale_factor from diffusion model ckpt -> {scale_factor}.")
|
| 124 |
+
else:
|
| 125 |
+
logger.info("trained diffusion model is not loaded.")
|
| 126 |
+
scale_factor = 1.0
|
| 127 |
+
logger.info(f"set scale_factor -> {scale_factor}.")
|
| 128 |
+
|
| 129 |
+
# define ControlNet
|
| 130 |
+
controlnet = define_instance(args, "controlnet_def").to(device)
|
| 131 |
+
# copy weights from the DM to the controlnet
|
| 132 |
+
copy_model_state(controlnet, unet.state_dict())
|
| 133 |
+
# load trained controlnet model if it is provided
|
| 134 |
+
if args.trained_controlnet_path is not None:
|
| 135 |
+
if not os.path.exists(args.trained_controlnet_path):
|
| 136 |
+
raise ValueError("Please download the trained ControlNet checkpoint.")
|
| 137 |
+
controlnet.load_state_dict(
|
| 138 |
+
torch.load(args.trained_controlnet_path, map_location=device, weights_only=False)["controlnet_state_dict"]
|
| 139 |
+
)
|
| 140 |
+
logger.info(f"load trained controlnet model from {args.trained_controlnet_path}")
|
| 141 |
+
else:
|
| 142 |
+
logger.info("trained controlnet is not loaded.")
|
| 143 |
+
|
| 144 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 145 |
+
|
| 146 |
+
# Step 3: inference
|
| 147 |
+
autoencoder.eval()
|
| 148 |
+
controlnet.eval()
|
| 149 |
+
unet.eval()
|
| 150 |
+
|
| 151 |
+
for batch in val_loader:
|
| 152 |
+
|
| 153 |
+
# get label mask
|
| 154 |
+
labels = batch["label"].to(device)
|
| 155 |
+
# get corresponding conditions
|
| 156 |
+
if include_body_region:
|
| 157 |
+
top_region_index_tensor = batch["top_region_index"].to(device)
|
| 158 |
+
bottom_region_index_tensor = batch["bottom_region_index"].to(device)
|
| 159 |
+
else:
|
| 160 |
+
top_region_index_tensor = None
|
| 161 |
+
bottom_region_index_tensor = None
|
| 162 |
+
spacing_tensor = batch["spacing"].to(device)
|
| 163 |
+
modality_tensor = args.controlnet_infer["modality"] * torch.ones((len(labels),), dtype=torch.long).to(device)
|
| 164 |
+
out_spacing = tuple((batch["spacing"].squeeze().numpy() / 100).tolist())
|
| 165 |
+
# get target dimension
|
| 166 |
+
dim = batch["dim"]
|
| 167 |
+
output_size = (dim[0].item(), dim[1].item(), dim[2].item())
|
| 168 |
+
latent_shape = (args.latent_channels, output_size[0] // 4, output_size[1] // 4, output_size[2] // 4)
|
| 169 |
+
# check if output_size and out_spacing are valid.
|
| 170 |
+
check_input(None, None, None, output_size, out_spacing, None)
|
| 171 |
+
# generate a single synthetic image using a latent diffusion model with controlnet.
|
| 172 |
+
synthetic_images, _ = ldm_conditional_sample_one_image(
|
| 173 |
+
autoencoder=autoencoder,
|
| 174 |
+
diffusion_unet=unet,
|
| 175 |
+
controlnet=controlnet,
|
| 176 |
+
noise_scheduler=noise_scheduler,
|
| 177 |
+
scale_factor=scale_factor,
|
| 178 |
+
device=device,
|
| 179 |
+
combine_label_or=labels,
|
| 180 |
+
top_region_index_tensor=top_region_index_tensor,
|
| 181 |
+
bottom_region_index_tensor=bottom_region_index_tensor,
|
| 182 |
+
spacing_tensor=spacing_tensor,
|
| 183 |
+
modality_tensor=modality_tensor,
|
| 184 |
+
latent_shape=latent_shape,
|
| 185 |
+
output_size=output_size,
|
| 186 |
+
noise_factor=1.0,
|
| 187 |
+
num_inference_steps=args.controlnet_infer["num_inference_steps"],
|
| 188 |
+
autoencoder_sliding_window_infer_size=args.controlnet_infer["autoencoder_sliding_window_infer_size"],
|
| 189 |
+
autoencoder_sliding_window_infer_overlap=args.controlnet_infer["autoencoder_sliding_window_infer_overlap"],
|
| 190 |
+
)
|
| 191 |
+
# save image/label pairs
|
| 192 |
+
labels = decollate_batch(batch)[0]["label"]
|
| 193 |
+
real_object_name = labels.meta.get("filename_or_obj", "default_name.nii.gz")
|
| 194 |
+
labels.meta["filename_or_obj"] = real_object_name
|
| 195 |
+
output_postfix = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 196 |
+
synthetic_images = MetaTensor(synthetic_images.squeeze(0), meta=labels.meta)
|
| 197 |
+
img_saver = SaveImage(
|
| 198 |
+
output_dir=args.output_dir,
|
| 199 |
+
output_postfix="image",
|
| 200 |
+
separate_folder=False,
|
| 201 |
+
)
|
| 202 |
+
img_saver(synthetic_images)
|
| 203 |
+
label_saver = SaveImage(
|
| 204 |
+
output_dir=args.output_dir,
|
| 205 |
+
output_postfix="label",
|
| 206 |
+
separate_folder=False,
|
| 207 |
+
)
|
| 208 |
+
label_saver(labels)
|
| 209 |
+
if use_ddp:
|
| 210 |
+
dist.destroy_process_group()
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
if __name__ == "__main__":
|
| 214 |
+
logging.basicConfig(
|
| 215 |
+
stream=sys.stdout,
|
| 216 |
+
level=logging.INFO,
|
| 217 |
+
format="[%(asctime)s.%(msecs)03d][%(levelname)5s](%(name)s) - %(message)s",
|
| 218 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 219 |
+
)
|
| 220 |
+
main()
|
scripts/inference.py
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
#
|
| 12 |
+
# # MAISI Inference Script
|
| 13 |
+
import argparse
|
| 14 |
+
import json
|
| 15 |
+
import logging
|
| 16 |
+
import os
|
| 17 |
+
import sys
|
| 18 |
+
import tempfile
|
| 19 |
+
|
| 20 |
+
import monai
|
| 21 |
+
import torch
|
| 22 |
+
from monai.apps import download_url
|
| 23 |
+
from monai.config import print_config
|
| 24 |
+
from monai.transforms import LoadImage, Orientation
|
| 25 |
+
from monai.utils import set_determinism
|
| 26 |
+
|
| 27 |
+
from scripts.sample import LDMSampler, check_input
|
| 28 |
+
from scripts.utils import define_instance
|
| 29 |
+
from scripts.utils_plot import find_label_center_loc, get_xyz_plot, show_image
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def main():
|
| 33 |
+
parser = argparse.ArgumentParser(description="maisi.controlnet.training")
|
| 34 |
+
parser.add_argument(
|
| 35 |
+
"-e",
|
| 36 |
+
"--environment-file",
|
| 37 |
+
default="./configs/environment.json",
|
| 38 |
+
help="environment json file that stores environment path",
|
| 39 |
+
)
|
| 40 |
+
parser.add_argument(
|
| 41 |
+
"-c",
|
| 42 |
+
"--config-file",
|
| 43 |
+
default="./configs/config_maisi.json",
|
| 44 |
+
help="config json file that stores network hyper-parameters",
|
| 45 |
+
)
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"-i",
|
| 48 |
+
"--inference-file",
|
| 49 |
+
default="./configs/config_infer.json",
|
| 50 |
+
help="config json file that stores inference hyper-parameters",
|
| 51 |
+
)
|
| 52 |
+
parser.add_argument(
|
| 53 |
+
"-x",
|
| 54 |
+
"--extra-config-file",
|
| 55 |
+
default=None,
|
| 56 |
+
help="config json file that stores inference extra parameters",
|
| 57 |
+
)
|
| 58 |
+
parser.add_argument(
|
| 59 |
+
"-s",
|
| 60 |
+
"--random-seed",
|
| 61 |
+
default=None,
|
| 62 |
+
help="random seed, can be None or int",
|
| 63 |
+
)
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--version",
|
| 66 |
+
default="maisi3d-rflow",
|
| 67 |
+
type=str,
|
| 68 |
+
help="maisi_version, choose from ['maisi3d-ddpm', 'maisi3d-rflow']",
|
| 69 |
+
)
|
| 70 |
+
args = parser.parse_args()
|
| 71 |
+
# Step 0: configuration
|
| 72 |
+
logger = logging.getLogger("maisi.inference")
|
| 73 |
+
|
| 74 |
+
maisi_version = args.version
|
| 75 |
+
|
| 76 |
+
# ## Set deterministic training for reproducibility
|
| 77 |
+
if args.random_seed is not None:
|
| 78 |
+
set_determinism(seed=args.random_seed)
|
| 79 |
+
|
| 80 |
+
# ## Setup data directory
|
| 81 |
+
# You can specify a directory with the `MONAI_DATA_DIRECTORY` environment variable.
|
| 82 |
+
# This allows you to save results and reuse downloads.
|
| 83 |
+
# If not specified a temporary directory will be used.
|
| 84 |
+
|
| 85 |
+
directory = os.environ.get("MONAI_DATA_DIRECTORY")
|
| 86 |
+
if directory is not None:
|
| 87 |
+
os.makedirs(directory, exist_ok=True)
|
| 88 |
+
root_dir = tempfile.mkdtemp() if directory is None else directory
|
| 89 |
+
print(root_dir)
|
| 90 |
+
|
| 91 |
+
# TODO: remove the `files` after the files are uploaded to the NGC
|
| 92 |
+
files = [
|
| 93 |
+
{
|
| 94 |
+
"path": "models/autoencoder_epoch273.pt",
|
| 95 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials"
|
| 96 |
+
"/model_zoo/model_maisi_autoencoder_epoch273_alternative.pt",
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"path": "models/mask_generation_autoencoder.pt",
|
| 100 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai"
|
| 101 |
+
"/tutorials/mask_generation_autoencoder.pt",
|
| 102 |
+
},
|
| 103 |
+
{
|
| 104 |
+
"path": "models/mask_generation_diffusion_unet.pt",
|
| 105 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai"
|
| 106 |
+
"/tutorials/model_zoo/model_maisi_mask_generation_diffusion_unet_v2.pt",
|
| 107 |
+
},
|
| 108 |
+
{
|
| 109 |
+
"path": "configs/all_anatomy_size_condtions.json",
|
| 110 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials/all_anatomy_size_condtions.json",
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"path": "datasets/all_masks_flexible_size_and_spacing_4000.zip",
|
| 114 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai"
|
| 115 |
+
"/tutorials/all_masks_flexible_size_and_spacing_4000.zip",
|
| 116 |
+
},
|
| 117 |
+
]
|
| 118 |
+
|
| 119 |
+
if maisi_version == "maisi3d-ddpm":
|
| 120 |
+
files += [
|
| 121 |
+
{
|
| 122 |
+
"path": "models/diff_unet_3d_ddpm.pt",
|
| 123 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials/model_zoo"
|
| 124 |
+
"/model_maisi_input_unet3d_data-all_steps1000size512ddpm_random_current_inputx_v1_alternative.pt",
|
| 125 |
+
},
|
| 126 |
+
{
|
| 127 |
+
"path": "models/controlnet_3d_ddpm.pt",
|
| 128 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials/model_zoo"
|
| 129 |
+
"/model_maisi_controlnet-20datasets-e20wl100fold0bc_noi_dia_fsize_current_alternative.pt",
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"path": "configs/candidate_masks_flexible_size_and_spacing_3000.json",
|
| 133 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai"
|
| 134 |
+
"/tutorials/candidate_masks_flexible_size_and_spacing_3000.json",
|
| 135 |
+
},
|
| 136 |
+
]
|
| 137 |
+
elif maisi_version == "maisi3d-rflow":
|
| 138 |
+
files += [
|
| 139 |
+
{
|
| 140 |
+
"path": "models/diff_unet_3d_rflow.pt",
|
| 141 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials/"
|
| 142 |
+
"diff_unet_ckpt_rflow_epoch19350.pt",
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"path": "models/controlnet_3d_rflow.pt",
|
| 146 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai/tutorials/"
|
| 147 |
+
"controlnet_rflow_epoch60.pt",
|
| 148 |
+
},
|
| 149 |
+
{
|
| 150 |
+
"path": "configs/candidate_masks_flexible_size_and_spacing_4000.json",
|
| 151 |
+
"url": "https://developer.download.nvidia.com/assets/Clara/monai"
|
| 152 |
+
"/tutorials/candidate_masks_flexible_size_and_spacing_4000.json",
|
| 153 |
+
},
|
| 154 |
+
]
|
| 155 |
+
else:
|
| 156 |
+
raise ValueError(
|
| 157 |
+
f"maisi_version has to be chosen from ['maisi3d-ddpm', 'maisi3d-rflow'], yet got {maisi_version}."
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
for file in files:
|
| 161 |
+
file["path"] = file["path"] if "datasets/" not in file["path"] else os.path.join(root_dir, file["path"])
|
| 162 |
+
download_url(url=file["url"], filepath=file["path"])
|
| 163 |
+
|
| 164 |
+
# ## Read in environment setting, including data directory, model directory, and output directory
|
| 165 |
+
# The information for data directory, model directory, and output directory are saved in ./configs/environment.json
|
| 166 |
+
env_dict = json.load(open(args.environment_file, "r"))
|
| 167 |
+
for k, v in env_dict.items():
|
| 168 |
+
# Update the path to the downloaded dataset in MONAI_DATA_DIRECTORY
|
| 169 |
+
val = v if "datasets/" not in v else os.path.join(root_dir, v)
|
| 170 |
+
setattr(args, k, val)
|
| 171 |
+
print(f"{k}: {val}")
|
| 172 |
+
print("Global config variables have been loaded.")
|
| 173 |
+
|
| 174 |
+
# ## Read in configuration setting, including network definition, body region and anatomy to generate, etc.
|
| 175 |
+
#
|
| 176 |
+
# The information for the inference input, like body region and anatomy to generate, is stored in "./configs/config_infer.json".
|
| 177 |
+
# Please refer to README.md for the details.
|
| 178 |
+
config_dict = json.load(open(args.config_file, "r"))
|
| 179 |
+
for k, v in config_dict.items():
|
| 180 |
+
setattr(args, k, v)
|
| 181 |
+
|
| 182 |
+
# check the format of inference inputs
|
| 183 |
+
config_infer_dict = json.load(open(args.inference_file, "r"))
|
| 184 |
+
# override num_split if asked
|
| 185 |
+
if "autoencoder_tp_num_splits" in config_infer_dict:
|
| 186 |
+
args.autoencoder_def["num_splits"] = config_infer_dict["autoencoder_tp_num_splits"]
|
| 187 |
+
args.mask_generation_autoencoder_def["num_splits"] = config_infer_dict["autoencoder_tp_num_splits"]
|
| 188 |
+
for k, v in config_infer_dict.items():
|
| 189 |
+
setattr(args, k, v)
|
| 190 |
+
print(f"{k}: {v}")
|
| 191 |
+
|
| 192 |
+
#
|
| 193 |
+
# ## Read in optional extra configuration setting - typically acceleration options (TRT)
|
| 194 |
+
#
|
| 195 |
+
#
|
| 196 |
+
if args.extra_config_file is not None:
|
| 197 |
+
extra_config_dict = json.load(open(args.extra_config_file, "r"))
|
| 198 |
+
for k, v in extra_config_dict.items():
|
| 199 |
+
setattr(args, k, v)
|
| 200 |
+
print(f"{k}: {v}")
|
| 201 |
+
|
| 202 |
+
check_input(
|
| 203 |
+
args.body_region,
|
| 204 |
+
args.anatomy_list,
|
| 205 |
+
args.label_dict_json,
|
| 206 |
+
args.output_size,
|
| 207 |
+
args.spacing,
|
| 208 |
+
args.controllable_anatomy_size,
|
| 209 |
+
)
|
| 210 |
+
latent_shape = [args.latent_channels, args.output_size[0] // 4, args.output_size[1] // 4, args.output_size[2] // 4]
|
| 211 |
+
print("Network definition and inference inputs have been loaded.")
|
| 212 |
+
|
| 213 |
+
# ## Initialize networks and noise scheduler, then load the trained model weights.
|
| 214 |
+
# The networks and noise scheduler are defined in `config_file`. We will read them in and load the model weights.
|
| 215 |
+
noise_scheduler = define_instance(args, "noise_scheduler")
|
| 216 |
+
mask_generation_noise_scheduler = define_instance(args, "mask_generation_noise_scheduler")
|
| 217 |
+
|
| 218 |
+
device = torch.device("cuda")
|
| 219 |
+
|
| 220 |
+
autoencoder = define_instance(args, "autoencoder").to(device)
|
| 221 |
+
checkpoint_autoencoder = torch.load(args.trained_autoencoder_path, weights_only=True)
|
| 222 |
+
autoencoder.load_state_dict(checkpoint_autoencoder)
|
| 223 |
+
|
| 224 |
+
diffusion_unet = define_instance(args, "diffusion_unet").to(device)
|
| 225 |
+
checkpoint_diffusion_unet = torch.load(args.trained_diffusion_path, weights_only=False)
|
| 226 |
+
diffusion_unet.load_state_dict(checkpoint_diffusion_unet["unet_state_dict"], strict=True)
|
| 227 |
+
scale_factor = checkpoint_diffusion_unet["scale_factor"].to(device)
|
| 228 |
+
|
| 229 |
+
controlnet = define_instance(args, "controlnet").to(device)
|
| 230 |
+
checkpoint_controlnet = torch.load(args.trained_controlnet_path, weights_only=False)
|
| 231 |
+
monai.networks.utils.copy_model_state(controlnet, diffusion_unet.state_dict())
|
| 232 |
+
controlnet.load_state_dict(checkpoint_controlnet["controlnet_state_dict"], strict=True)
|
| 233 |
+
|
| 234 |
+
mask_generation_autoencoder = define_instance(args, "mask_generation_autoencoder").to(device)
|
| 235 |
+
checkpoint_mask_generation_autoencoder = torch.load(
|
| 236 |
+
args.trained_mask_generation_autoencoder_path, weights_only=True
|
| 237 |
+
)
|
| 238 |
+
mask_generation_autoencoder.load_state_dict(checkpoint_mask_generation_autoencoder)
|
| 239 |
+
|
| 240 |
+
mask_generation_diffusion_unet = define_instance(args, "mask_generation_diffusion").to(device)
|
| 241 |
+
checkpoint_mask_generation_diffusion_unet = torch.load(
|
| 242 |
+
args.trained_mask_generation_diffusion_path, weights_only=False
|
| 243 |
+
)
|
| 244 |
+
mask_generation_diffusion_unet.load_state_dict(checkpoint_mask_generation_diffusion_unet["unet_state_dict"])
|
| 245 |
+
mask_generation_scale_factor = checkpoint_mask_generation_diffusion_unet["scale_factor"]
|
| 246 |
+
|
| 247 |
+
print("All the trained model weights have been loaded.")
|
| 248 |
+
|
| 249 |
+
# ## Define the LDM Sampler, which contains functions that will perform the inference.
|
| 250 |
+
ldm_sampler = LDMSampler(
|
| 251 |
+
args.body_region,
|
| 252 |
+
args.anatomy_list,
|
| 253 |
+
args.all_mask_files_json,
|
| 254 |
+
args.all_anatomy_size_conditions_json,
|
| 255 |
+
args.all_mask_files_base_dir,
|
| 256 |
+
args.label_dict_json,
|
| 257 |
+
args.label_dict_remap_json,
|
| 258 |
+
autoencoder,
|
| 259 |
+
diffusion_unet,
|
| 260 |
+
controlnet,
|
| 261 |
+
noise_scheduler,
|
| 262 |
+
scale_factor,
|
| 263 |
+
mask_generation_autoencoder,
|
| 264 |
+
mask_generation_diffusion_unet,
|
| 265 |
+
mask_generation_scale_factor,
|
| 266 |
+
mask_generation_noise_scheduler,
|
| 267 |
+
device,
|
| 268 |
+
latent_shape,
|
| 269 |
+
args.mask_generation_latent_shape,
|
| 270 |
+
args.output_size,
|
| 271 |
+
args.output_dir,
|
| 272 |
+
args.controllable_anatomy_size,
|
| 273 |
+
image_output_ext=args.image_output_ext,
|
| 274 |
+
label_output_ext=args.label_output_ext,
|
| 275 |
+
spacing=args.spacing,
|
| 276 |
+
modality=args.modality,
|
| 277 |
+
num_inference_steps=args.num_inference_steps,
|
| 278 |
+
mask_generation_num_inference_steps=args.mask_generation_num_inference_steps,
|
| 279 |
+
random_seed=args.random_seed,
|
| 280 |
+
autoencoder_sliding_window_infer_size=args.autoencoder_sliding_window_infer_size,
|
| 281 |
+
autoencoder_sliding_window_infer_overlap=args.autoencoder_sliding_window_infer_overlap,
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
print(f"The generated image/mask pairs will be saved in {args.output_dir}.")
|
| 285 |
+
output_filenames = ldm_sampler.sample_multiple_images(args.num_output_samples)
|
| 286 |
+
print("MAISI image/mask generation finished")
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
if __name__ == "__main__":
|
| 290 |
+
logging.basicConfig(
|
| 291 |
+
stream=sys.stdout,
|
| 292 |
+
level=logging.INFO,
|
| 293 |
+
format="[%(asctime)s.%(msecs)03d][%(levelname)5s](%(name)s) - %(message)s",
|
| 294 |
+
datefmt="%Y-%m-%d %H:%M:%S",
|
| 295 |
+
)
|
| 296 |
+
torch.cuda.reset_peak_memory_stats()
|
| 297 |
+
main()
|
| 298 |
+
peak_memory_gb = torch.cuda.max_memory_allocated() / (1024**3) # Convert to GB
|
| 299 |
+
print(f"Peak GPU memory usage: {peak_memory_gb:.2f} GB")
|
scripts/quality_check.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_masked_data(label_data, image_data, labels):
|
| 16 |
+
"""
|
| 17 |
+
Extracts and returns the image data corresponding to specified labels within a 3D volume.
|
| 18 |
+
|
| 19 |
+
This function efficiently masks the `image_data` array based on the provided `labels` in the `label_data` array.
|
| 20 |
+
The function handles cases with both a large and small number of labels, optimizing performance accordingly.
|
| 21 |
+
|
| 22 |
+
Args:
|
| 23 |
+
label_data (np.ndarray): A NumPy array containing label data, representing different anatomical
|
| 24 |
+
regions or classes in a 3D medical image.
|
| 25 |
+
image_data (np.ndarray): A NumPy array containing the image data from which the relevant regions
|
| 26 |
+
will be extracted.
|
| 27 |
+
labels (list of int): A list of integers representing the label values to be used for masking.
|
| 28 |
+
|
| 29 |
+
Returns:
|
| 30 |
+
np.ndarray: A NumPy array containing the elements of `image_data` that correspond to the specified
|
| 31 |
+
labels in `label_data`. If no labels are provided, an empty array is returned.
|
| 32 |
+
|
| 33 |
+
Raises:
|
| 34 |
+
ValueError: If `image_data` and `label_data` do not have the same shape.
|
| 35 |
+
|
| 36 |
+
Example:
|
| 37 |
+
label_int_dict = {"liver": [1], "kidney": [5, 14]}
|
| 38 |
+
masked_data = get_masked_data(label_data, image_data, label_int_dict["kidney"])
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
# Check if the shapes of image_data and label_data match
|
| 42 |
+
if image_data.shape != label_data.shape:
|
| 43 |
+
raise ValueError(
|
| 44 |
+
f"Shape mismatch: image_data has shape {image_data.shape}, "
|
| 45 |
+
f"but label_data has shape {label_data.shape}. They must be the same."
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
if not labels:
|
| 49 |
+
return np.array([]) # Return an empty array if no labels are provided
|
| 50 |
+
|
| 51 |
+
labels = list(set(labels)) # remove duplicate items
|
| 52 |
+
|
| 53 |
+
# Optimize performance based on the number of labels
|
| 54 |
+
num_label_acceleration_thresh = 3
|
| 55 |
+
if len(labels) >= num_label_acceleration_thresh:
|
| 56 |
+
# if many labels, np.isin is faster
|
| 57 |
+
mask = np.isin(label_data, labels)
|
| 58 |
+
else:
|
| 59 |
+
# Use logical OR to combine masks if the number of labels is small
|
| 60 |
+
mask = np.zeros_like(label_data, dtype=bool)
|
| 61 |
+
for label in labels:
|
| 62 |
+
mask = np.logical_or(mask, label_data == label)
|
| 63 |
+
|
| 64 |
+
# Retrieve the masked data
|
| 65 |
+
masked_data = image_data[mask.astype(bool)]
|
| 66 |
+
|
| 67 |
+
return masked_data
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def is_outlier(statistics, image_data, label_data, label_int_dict):
|
| 71 |
+
"""
|
| 72 |
+
Perform a quality check on the generated image by comparing its statistics with precomputed thresholds.
|
| 73 |
+
|
| 74 |
+
Args:
|
| 75 |
+
statistics (dict): Dictionary containing precomputed statistics including mean +/- 3sigma ranges.
|
| 76 |
+
image_data (np.ndarray): The image data to be checked, typically a 3D NumPy array.
|
| 77 |
+
label_data (np.ndarray): The label data corresponding to the image, used for masking regions of interest.
|
| 78 |
+
label_int_dict (dict): Dictionary mapping label names to their corresponding integer lists.
|
| 79 |
+
e.g., label_int_dict = {"liver": [1], "kidney": [5, 14]}
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
dict: A dictionary with labels as keys, each containing the quality check result,
|
| 83 |
+
including whether it's an outlier, the median value, and the thresholds used.
|
| 84 |
+
If no data is found for a label, the median value will be `None` and `is_outlier` will be `False`.
|
| 85 |
+
|
| 86 |
+
Example:
|
| 87 |
+
# Example input data
|
| 88 |
+
statistics = {
|
| 89 |
+
"liver": {
|
| 90 |
+
"sigma_6_low": -21.596463547885904,
|
| 91 |
+
"sigma_6_high": 156.27881534763367
|
| 92 |
+
},
|
| 93 |
+
"kidney": {
|
| 94 |
+
"sigma_6_low": -15.0,
|
| 95 |
+
"sigma_6_high": 120.0
|
| 96 |
+
}
|
| 97 |
+
}
|
| 98 |
+
label_int_dict = {
|
| 99 |
+
"liver": [1],
|
| 100 |
+
"kidney": [5, 14]
|
| 101 |
+
}
|
| 102 |
+
image_data = np.random.rand(100, 100, 100) # Replace with actual image data
|
| 103 |
+
label_data = np.zeros((100, 100, 100)) # Replace with actual label data
|
| 104 |
+
label_data[40:60, 40:60, 40:60] = 1 # Example region for liver
|
| 105 |
+
label_data[70:90, 70:90, 70:90] = 5 # Example region for kidney
|
| 106 |
+
result = is_outlier(statistics, image_data, label_data, label_int_dict)
|
| 107 |
+
"""
|
| 108 |
+
outlier_results = {}
|
| 109 |
+
|
| 110 |
+
for label_name, stats in statistics.items():
|
| 111 |
+
# Get the thresholds from the statistics
|
| 112 |
+
low_thresh = min(stats["sigma_6_low"], stats["percentile_0_5"]) # or "sigma_12_low" depending on your needs
|
| 113 |
+
high_thresh = max(stats["sigma_6_high"], stats["percentile_99_5"]) # or "sigma_12_high" depending on your needs
|
| 114 |
+
|
| 115 |
+
if label_name == "bone":
|
| 116 |
+
high_thresh = 1000.0
|
| 117 |
+
|
| 118 |
+
# Retrieve the corresponding label integers
|
| 119 |
+
labels = label_int_dict.get(label_name, [])
|
| 120 |
+
masked_data = get_masked_data(label_data, image_data, labels)
|
| 121 |
+
masked_data = masked_data[~np.isnan(masked_data)]
|
| 122 |
+
|
| 123 |
+
if len(masked_data) == 0 or masked_data.size == 0:
|
| 124 |
+
outlier_results[label_name] = {
|
| 125 |
+
"is_outlier": False,
|
| 126 |
+
"median_value": None,
|
| 127 |
+
"low_thresh": low_thresh,
|
| 128 |
+
"high_thresh": high_thresh,
|
| 129 |
+
}
|
| 130 |
+
continue
|
| 131 |
+
|
| 132 |
+
# Compute the median of the masked region
|
| 133 |
+
median_value = np.nanmedian(masked_data)
|
| 134 |
+
|
| 135 |
+
if np.isnan(median_value):
|
| 136 |
+
median_value = None
|
| 137 |
+
is_outlier = False
|
| 138 |
+
else:
|
| 139 |
+
# Determine if the median value is an outlier
|
| 140 |
+
is_outlier = median_value < low_thresh or median_value > high_thresh
|
| 141 |
+
|
| 142 |
+
outlier_results[label_name] = {
|
| 143 |
+
"is_outlier": is_outlier,
|
| 144 |
+
"median_value": median_value,
|
| 145 |
+
"low_thresh": low_thresh,
|
| 146 |
+
"high_thresh": high_thresh,
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
return outlier_results
|
scripts/rectified_flow.py
ADDED
|
@@ -0,0 +1,322 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) MONAI Consortium
|
| 2 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 3 |
+
# you may not use this file except in compliance with the License.
|
| 4 |
+
# You may obtain a copy of the License at
|
| 5 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 6 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 7 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 8 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 9 |
+
# See the License for the specific language governing permissions and
|
| 10 |
+
# limitations under the License.
|
| 11 |
+
#
|
| 12 |
+
# =========================================================================
|
| 13 |
+
# Adapted from https://github.com/hpcaitech/Open-Sora/blob/main/opensora/schedulers/rf/rectified_flow.py
|
| 14 |
+
# which has the following license:
|
| 15 |
+
# https://github.com/hpcaitech/Open-Sora/blob/main/LICENSE
|
| 16 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 17 |
+
# you may not use this file except in compliance with the License.
|
| 18 |
+
# You may obtain a copy of the License at
|
| 19 |
+
#
|
| 20 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 21 |
+
#
|
| 22 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 23 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 24 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 25 |
+
# See the License for the specific language governing permissions and
|
| 26 |
+
# limitations under the License.
|
| 27 |
+
# =========================================================================
|
| 28 |
+
|
| 29 |
+
from __future__ import annotations
|
| 30 |
+
|
| 31 |
+
from typing import Union
|
| 32 |
+
|
| 33 |
+
import numpy as np
|
| 34 |
+
import torch
|
| 35 |
+
from torch.distributions import LogisticNormal
|
| 36 |
+
|
| 37 |
+
from monai.utils import StrEnum
|
| 38 |
+
|
| 39 |
+
from .ddpm import DDPMPredictionType
|
| 40 |
+
from .scheduler import Scheduler
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class RFlowPredictionType(StrEnum):
|
| 44 |
+
"""
|
| 45 |
+
Set of valid prediction type names for the RFlow scheduler's `prediction_type` argument.
|
| 46 |
+
|
| 47 |
+
v_prediction: velocity prediction, see section 2.4 https://imagen.research.google/video/paper.pdf
|
| 48 |
+
"""
|
| 49 |
+
|
| 50 |
+
V_PREDICTION = DDPMPredictionType.V_PREDICTION
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def timestep_transform(
|
| 54 |
+
t, input_img_size_numel, base_img_size_numel=32 * 32 * 32, scale=1.0, num_train_timesteps=1000, spatial_dim=3
|
| 55 |
+
):
|
| 56 |
+
"""
|
| 57 |
+
Applies a transformation to the timestep based on image resolution scaling.
|
| 58 |
+
|
| 59 |
+
Args:
|
| 60 |
+
t (torch.Tensor): The original timestep(s).
|
| 61 |
+
input_img_size_numel (torch.Tensor): The input image's size (H * W * D).
|
| 62 |
+
base_img_size_numel (int): reference H*W*D size, usually smaller than input_img_size_numel.
|
| 63 |
+
scale (float): Scaling factor for the transformation.
|
| 64 |
+
num_train_timesteps (int): Total number of training timesteps.
|
| 65 |
+
spatial_dim (int): Number of spatial dimensions in the image.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
torch.Tensor: Transformed timestep(s).
|
| 69 |
+
"""
|
| 70 |
+
t = t / num_train_timesteps
|
| 71 |
+
ratio_space = (input_img_size_numel / base_img_size_numel) ** (1.0 / spatial_dim)
|
| 72 |
+
|
| 73 |
+
ratio = ratio_space * scale
|
| 74 |
+
new_t = ratio * t / (1 + (ratio - 1) * t)
|
| 75 |
+
|
| 76 |
+
new_t = new_t * num_train_timesteps
|
| 77 |
+
return new_t
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class RFlowScheduler(Scheduler):
|
| 81 |
+
"""
|
| 82 |
+
A rectified flow scheduler for guiding the diffusion process in a generative model.
|
| 83 |
+
|
| 84 |
+
Supports uniform and logit-normal sampling methods, timestep transformation for
|
| 85 |
+
different resolutions, and noise addition during diffusion.
|
| 86 |
+
|
| 87 |
+
Args:
|
| 88 |
+
num_train_timesteps (int): Total number of training timesteps.
|
| 89 |
+
use_discrete_timesteps (bool): Whether to use discrete timesteps.
|
| 90 |
+
sample_method (str): Training time step sampling method ('uniform' or 'logit-normal').
|
| 91 |
+
loc (float): Location parameter for logit-normal distribution, used only if sample_method='logit-normal'.
|
| 92 |
+
scale (float): Scale parameter for logit-normal distribution, used only if sample_method='logit-normal'.
|
| 93 |
+
use_timestep_transform (bool): Whether to apply timestep transformation.
|
| 94 |
+
If true, there will be more inference timesteps at early(noisy) stages for larger image volumes.
|
| 95 |
+
transform_scale (float): Scaling factor for timestep transformation, used only if use_timestep_transform=True.
|
| 96 |
+
steps_offset (int): Offset added to computed timesteps, used only if use_timestep_transform=True.
|
| 97 |
+
base_img_size_numel (int): Reference image volume size for scaling, used only if use_timestep_transform=True.
|
| 98 |
+
spatial_dim (int): 2 or 3, incidcating 2D or 3D images, used only if use_timestep_transform=True.
|
| 99 |
+
|
| 100 |
+
Example:
|
| 101 |
+
|
| 102 |
+
.. code-block:: python
|
| 103 |
+
|
| 104 |
+
# define a scheduler
|
| 105 |
+
noise_scheduler = RFlowScheduler(
|
| 106 |
+
num_train_timesteps = 1000,
|
| 107 |
+
use_discrete_timesteps = True,
|
| 108 |
+
sample_method = 'logit-normal',
|
| 109 |
+
use_timestep_transform = True,
|
| 110 |
+
base_img_size_numel = 32 * 32 * 32,
|
| 111 |
+
spatial_dim = 3
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
# during training
|
| 115 |
+
inputs = torch.ones(2,4,64,64,32)
|
| 116 |
+
noise = torch.randn_like(inputs)
|
| 117 |
+
timesteps = noise_scheduler.sample_timesteps(inputs)
|
| 118 |
+
noisy_inputs = noise_scheduler.add_noise(original_samples=inputs, noise=noise, timesteps=timesteps)
|
| 119 |
+
predicted_velocity = diffusion_unet(
|
| 120 |
+
x=noisy_inputs,
|
| 121 |
+
timesteps=timesteps
|
| 122 |
+
)
|
| 123 |
+
loss = loss_l1(predicted_velocity, (inputs - noise))
|
| 124 |
+
|
| 125 |
+
# during inference
|
| 126 |
+
noisy_inputs = torch.randn(2,4,64,64,32)
|
| 127 |
+
input_img_size_numel = torch.prod(torch.tensor(noisy_inputs.shape[-3:])
|
| 128 |
+
noise_scheduler.set_timesteps(
|
| 129 |
+
num_inference_steps=30, input_img_size_numel=input_img_size_numel)
|
| 130 |
+
)
|
| 131 |
+
all_next_timesteps = torch.cat(
|
| 132 |
+
(noise_scheduler.timesteps[1:], torch.tensor([0], dtype=noise_scheduler.timesteps.dtype))
|
| 133 |
+
)
|
| 134 |
+
for t, next_t in tqdm(
|
| 135 |
+
zip(noise_scheduler.timesteps, all_next_timesteps),
|
| 136 |
+
total=min(len(noise_scheduler.timesteps), len(all_next_timesteps)),
|
| 137 |
+
):
|
| 138 |
+
predicted_velocity = diffusion_unet(
|
| 139 |
+
x=noisy_inputs,
|
| 140 |
+
timesteps=timesteps
|
| 141 |
+
)
|
| 142 |
+
noisy_inputs, _ = noise_scheduler.step(predicted_velocity, t, noisy_inputs, next_t)
|
| 143 |
+
final_output = noisy_inputs
|
| 144 |
+
"""
|
| 145 |
+
|
| 146 |
+
def __init__(
|
| 147 |
+
self,
|
| 148 |
+
num_train_timesteps: int = 1000,
|
| 149 |
+
use_discrete_timesteps: bool = True,
|
| 150 |
+
sample_method: str = "uniform",
|
| 151 |
+
loc: float = 0.0,
|
| 152 |
+
scale: float = 1.0,
|
| 153 |
+
use_timestep_transform: bool = False,
|
| 154 |
+
transform_scale: float = 1.0,
|
| 155 |
+
steps_offset: int = 0,
|
| 156 |
+
base_img_size_numel: int = 32 * 32 * 32,
|
| 157 |
+
spatial_dim: int = 3,
|
| 158 |
+
):
|
| 159 |
+
# rectified flow only accepts velocity prediction
|
| 160 |
+
self.prediction_type = RFlowPredictionType.V_PREDICTION
|
| 161 |
+
|
| 162 |
+
self.num_train_timesteps = num_train_timesteps
|
| 163 |
+
self.use_discrete_timesteps = use_discrete_timesteps
|
| 164 |
+
self.base_img_size_numel = base_img_size_numel
|
| 165 |
+
self.spatial_dim = spatial_dim
|
| 166 |
+
|
| 167 |
+
# sample method
|
| 168 |
+
if sample_method not in ["uniform", "logit-normal"]:
|
| 169 |
+
raise ValueError(
|
| 170 |
+
f"sample_method = {sample_method}, which has to be chosen from ['uniform', 'logit-normal']."
|
| 171 |
+
)
|
| 172 |
+
self.sample_method = sample_method
|
| 173 |
+
if sample_method == "logit-normal":
|
| 174 |
+
self.distribution = LogisticNormal(torch.tensor([loc]), torch.tensor([scale]))
|
| 175 |
+
self.sample_t = lambda x: self.distribution.sample((x.shape[0],))[:, 0].to(x.device)
|
| 176 |
+
|
| 177 |
+
# timestep transform
|
| 178 |
+
self.use_timestep_transform = use_timestep_transform
|
| 179 |
+
self.transform_scale = transform_scale
|
| 180 |
+
self.steps_offset = steps_offset
|
| 181 |
+
|
| 182 |
+
def add_noise(self, original_samples: torch.Tensor, noise: torch.Tensor, timesteps: torch.Tensor) -> torch.Tensor:
|
| 183 |
+
"""
|
| 184 |
+
Add noise to the original samples.
|
| 185 |
+
|
| 186 |
+
Args:
|
| 187 |
+
original_samples: original samples
|
| 188 |
+
noise: noise to add to samples
|
| 189 |
+
timesteps: timesteps tensor with shape of (N,), indicating the timestep to be computed for each sample.
|
| 190 |
+
|
| 191 |
+
Returns:
|
| 192 |
+
noisy_samples: sample with added noise
|
| 193 |
+
"""
|
| 194 |
+
timepoints: torch.Tensor = timesteps.float() / self.num_train_timesteps
|
| 195 |
+
timepoints = 1 - timepoints # [1,1/1000]
|
| 196 |
+
|
| 197 |
+
# expand timepoint to noise shape
|
| 198 |
+
if noise.ndim == 5:
|
| 199 |
+
timepoints = timepoints[..., None, None, None, None].expand(-1, *noise.shape[1:])
|
| 200 |
+
elif noise.ndim == 4:
|
| 201 |
+
timepoints = timepoints[..., None, None, None].expand(-1, *noise.shape[1:])
|
| 202 |
+
else:
|
| 203 |
+
raise ValueError(f"noise tensor has to be 4D or 5D tensor, yet got shape of {noise.shape}")
|
| 204 |
+
|
| 205 |
+
noisy_samples: torch.Tensor = timepoints * original_samples + (1 - timepoints) * noise
|
| 206 |
+
|
| 207 |
+
return noisy_samples
|
| 208 |
+
|
| 209 |
+
def set_timesteps(
|
| 210 |
+
self,
|
| 211 |
+
num_inference_steps: int,
|
| 212 |
+
device: str | torch.device | None = None,
|
| 213 |
+
input_img_size_numel: int | None = None,
|
| 214 |
+
) -> None:
|
| 215 |
+
"""
|
| 216 |
+
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
|
| 217 |
+
|
| 218 |
+
Args:
|
| 219 |
+
num_inference_steps: number of diffusion steps used when generating samples with a pre-trained model.
|
| 220 |
+
device: target device to put the data.
|
| 221 |
+
input_img_size_numel: int, H*W*D of the image, used with self.use_timestep_transform is True.
|
| 222 |
+
"""
|
| 223 |
+
if num_inference_steps > self.num_train_timesteps or num_inference_steps < 1:
|
| 224 |
+
raise ValueError(
|
| 225 |
+
f"`num_inference_steps`: {num_inference_steps} should be at least 1, "
|
| 226 |
+
"and cannot be larger than `self.num_train_timesteps`:"
|
| 227 |
+
f" {self.num_train_timesteps} as the unet model trained with this scheduler can only handle"
|
| 228 |
+
f" maximal {self.num_train_timesteps} timesteps."
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
self.num_inference_steps = num_inference_steps
|
| 232 |
+
# prepare timesteps
|
| 233 |
+
timesteps = [
|
| 234 |
+
(1.0 - i / self.num_inference_steps) * self.num_train_timesteps for i in range(self.num_inference_steps)
|
| 235 |
+
]
|
| 236 |
+
if self.use_discrete_timesteps:
|
| 237 |
+
timesteps = [int(round(t)) for t in timesteps]
|
| 238 |
+
if self.use_timestep_transform:
|
| 239 |
+
timesteps = [
|
| 240 |
+
timestep_transform(
|
| 241 |
+
t,
|
| 242 |
+
input_img_size_numel=input_img_size_numel,
|
| 243 |
+
base_img_size_numel=self.base_img_size_numel,
|
| 244 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 245 |
+
spatial_dim=self.spatial_dim,
|
| 246 |
+
)
|
| 247 |
+
for t in timesteps
|
| 248 |
+
]
|
| 249 |
+
timesteps_np = np.array(timesteps).astype(np.float16)
|
| 250 |
+
if self.use_discrete_timesteps:
|
| 251 |
+
timesteps_np = timesteps_np.astype(np.int64)
|
| 252 |
+
self.timesteps = torch.from_numpy(timesteps_np).to(device)
|
| 253 |
+
self.timesteps += self.steps_offset
|
| 254 |
+
|
| 255 |
+
def sample_timesteps(self, x_start):
|
| 256 |
+
"""
|
| 257 |
+
Randomly samples training timesteps using the chosen sampling method.
|
| 258 |
+
|
| 259 |
+
Args:
|
| 260 |
+
x_start (torch.Tensor): The input tensor for sampling.
|
| 261 |
+
|
| 262 |
+
Returns:
|
| 263 |
+
torch.Tensor: Sampled timesteps.
|
| 264 |
+
"""
|
| 265 |
+
if self.sample_method == "uniform":
|
| 266 |
+
t = torch.rand((x_start.shape[0],), device=x_start.device) * self.num_train_timesteps
|
| 267 |
+
elif self.sample_method == "logit-normal":
|
| 268 |
+
t = self.sample_t(x_start) * self.num_train_timesteps
|
| 269 |
+
|
| 270 |
+
if self.use_discrete_timesteps:
|
| 271 |
+
t = t.long()
|
| 272 |
+
|
| 273 |
+
if self.use_timestep_transform:
|
| 274 |
+
input_img_size_numel = torch.prod(torch.tensor(x_start.shape[2:]))
|
| 275 |
+
t = timestep_transform(
|
| 276 |
+
t,
|
| 277 |
+
input_img_size_numel=input_img_size_numel,
|
| 278 |
+
base_img_size_numel=self.base_img_size_numel,
|
| 279 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 280 |
+
spatial_dim=len(x_start.shape) - 2,
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
return t
|
| 284 |
+
|
| 285 |
+
def step(
|
| 286 |
+
self, model_output: torch.Tensor, timestep: int, sample: torch.Tensor, next_timestep: Union[int, None] = None
|
| 287 |
+
) -> tuple[torch.Tensor, torch.Tensor]:
|
| 288 |
+
"""
|
| 289 |
+
Predicts the next sample in the diffusion process.
|
| 290 |
+
|
| 291 |
+
Args:
|
| 292 |
+
model_output (torch.Tensor): Output from the trained diffusion model.
|
| 293 |
+
timestep (int): Current timestep in the diffusion chain.
|
| 294 |
+
sample (torch.Tensor): Current sample in the process.
|
| 295 |
+
next_timestep (Union[int, None]): Optional next timestep.
|
| 296 |
+
|
| 297 |
+
Returns:
|
| 298 |
+
tuple[torch.Tensor, torch.Tensor]: Predicted sample at the next step and additional info.
|
| 299 |
+
"""
|
| 300 |
+
# Ensure num_inference_steps exists and is a valid integer
|
| 301 |
+
if not hasattr(self, "num_inference_steps") or not isinstance(self.num_inference_steps, int):
|
| 302 |
+
raise AttributeError(
|
| 303 |
+
"num_inference_steps is missing or not an integer in the class."
|
| 304 |
+
"Please run self.set_timesteps(num_inference_steps,device,input_img_size_numel) to set it."
|
| 305 |
+
)
|
| 306 |
+
|
| 307 |
+
v_pred = model_output
|
| 308 |
+
|
| 309 |
+
if next_timestep is not None:
|
| 310 |
+
next_timestep = int(next_timestep)
|
| 311 |
+
dt: float = (
|
| 312 |
+
float(timestep - next_timestep) / self.num_train_timesteps
|
| 313 |
+
) # Now next_timestep is guaranteed to be int
|
| 314 |
+
else:
|
| 315 |
+
dt = (
|
| 316 |
+
1.0 / float(self.num_inference_steps) if self.num_inference_steps > 0 else 0.0
|
| 317 |
+
) # Avoid division by zero
|
| 318 |
+
|
| 319 |
+
pred_post_sample = sample + v_pred * dt
|
| 320 |
+
pred_original_sample = sample + v_pred * timestep / self.num_train_timesteps
|
| 321 |
+
|
| 322 |
+
return pred_post_sample, pred_original_sample
|