

https://github.com/ArneBinder/pie-datasets/pull/100
Browse files- README.md +140 -0
- argmicro.py +283 -283
- img/rtd-label_argmicro.png +3 -0
- img/slt_argmicro.png +3 -0
- img/tl_argmicro.png +3 -0
- requirements.txt +1 -1
README.md
CHANGED
|
@@ -3,6 +3,27 @@
|
|
| 3 |
This is a [PyTorch-IE](https://github.com/ChristophAlt/pytorch-ie) wrapper for the
|
| 4 |
[ArgMicro Huggingface dataset loading script](https://huggingface.co/datasets/DFKI-SLT/argmicro).
|
| 5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
## Dataset Variants
|
| 7 |
|
| 8 |
The dataset contains two `BuilderConfig`'s:
|
|
@@ -53,3 +74,122 @@ The dataset provides document converters for the following target document types
|
|
| 53 |
|
| 54 |
See [here](https://github.com/ChristophAlt/pytorch-ie/blob/main/src/pytorch_ie/documents.py) for the document type
|
| 55 |
definitions.
|
|
|
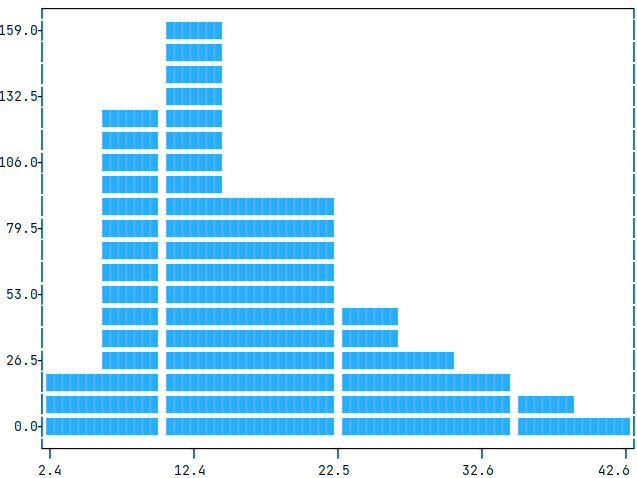
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
This is a [PyTorch-IE](https://github.com/ChristophAlt/pytorch-ie) wrapper for the
|
| 4 |
[ArgMicro Huggingface dataset loading script](https://huggingface.co/datasets/DFKI-SLT/argmicro).
|
| 5 |
|
| 6 |
+
## Usage
|
| 7 |
+
|
| 8 |
+
```python
|
| 9 |
+
from pie_datasets import load_dataset
|
| 10 |
+
from pytorch_ie.documents import TextDocumentWithLabeledSpansAndBinaryRelations
|
| 11 |
+
|
| 12 |
+
# load English variant
|
| 13 |
+
dataset = load_dataset("pie/argmicro", name="en")
|
| 14 |
+
|
| 15 |
+
# if required, normalize the document type (see section Document Converters below)
|
| 16 |
+
dataset_converted = dataset.to_document_type(TextDocumentWithLabeledSpansAndBinaryRelations)
|
| 17 |
+
assert isinstance(dataset_converted["train"][0], TextDocumentWithLabeledSpansAndBinaryRelations)
|
| 18 |
+
|
| 19 |
+
# get first relation in the first document
|
| 20 |
+
doc = dataset_converted["train"][0]
|
| 21 |
+
print(doc.binary_relations[0])
|
| 22 |
+
# BinaryRelation(head=LabeledSpan(start=0, end=81, label='opp', score=1.0), tail=LabeledSpan(start=326, end=402, label='pro', score=1.0), label='reb', score=1.0)
|
| 23 |
+
print(doc.binary_relations[0].resolve())
|
| 24 |
+
# ('reb', (('opp', "Yes, it's annoying and cumbersome to separate your rubbish properly all the time."), ('pro', 'We Berliners should take the chance and become pioneers in waste separation!')))
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
## Dataset Variants
|
| 28 |
|
| 29 |
The dataset contains two `BuilderConfig`'s:
|
|
|
|
| 74 |
|
| 75 |
See [here](https://github.com/ChristophAlt/pytorch-ie/blob/main/src/pytorch_ie/documents.py) for the document type
|
| 76 |
definitions.
|
| 77 |
+
|
| 78 |
+
### Collected Statistics after Document Conversion
|
| 79 |
+
|
| 80 |
+
We use the script `evaluate_documents.py` from [PyTorch-IE-Hydra-Template](https://github.com/ArneBinder/pytorch-ie-hydra-template-1) to generate these statistics.
|
| 81 |
+
After checking out that code, the statistics and plots can be generated by the command:
|
| 82 |
+
|
| 83 |
+
```commandline
|
| 84 |
+
python src/evaluate_documents.py dataset=argmicro_base metric=METRIC
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
where a `METRIC` is called according to the available metric configs in `config/metric/METRIC` (see [metrics](https://github.com/ArneBinder/pytorch-ie-hydra-template-1/tree/main/configs/metric)).
|
| 88 |
+
|
| 89 |
+
This also requires to have the following dataset config in `configs/dataset/argmicro_base.yaml` of this dataset within the repo directory:
|
| 90 |
+
|
| 91 |
+
```commandline
|
| 92 |
+
_target_: src.utils.execute_pipeline
|
| 93 |
+
input:
|
| 94 |
+
_target_: pie_datasets.DatasetDict.load_dataset
|
| 95 |
+
path: pie/argmicro
|
| 96 |
+
revision: 28ef031d2a2c97be7e9ed360e1a5b20bd55b57b2
|
| 97 |
+
name: en
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
For token based metrics, this uses `bert-base-uncased` from `transformer.AutoTokenizer` (see [AutoTokenizer](https://huggingface.co/docs/transformers/v4.37.1/en/model_doc/auto#transformers.AutoTokenizer), and [bert-based-uncased](https://huggingface.co/bert-base-uncased) to tokenize `text` in `TextDocumentWithLabeledSpansAndBinaryRelations` (see [document type](https://github.com/ChristophAlt/pytorch-ie/blob/main/src/pytorch_ie/documents.py)).
|
| 101 |
+
|
| 102 |
+
#### Relation argument (outer) token distance per label
|
| 103 |
+
|
| 104 |
+
The distance is measured from the first token of the first argumentative unit to the last token of the last unit, a.k.a. outer distance.
|
| 105 |
+
|
| 106 |
+
We collect the following statistics: number of documents in the split (*no. doc*), no. of relations (*len*), mean of token distance (*mean*), standard deviation of the distance (*std*), minimum outer distance (*min*), and maximum outer distance (*max*).
|
| 107 |
+
We also present histograms in the collapsible, showing the distribution of these relation distances (x-axis; and unit-counts in y-axis), accordingly.
|
| 108 |
+
|
| 109 |
+
<details>
|
| 110 |
+
<summary>Command</summary>
|
| 111 |
+
|
| 112 |
+
```
|
| 113 |
+
python src/evaluate_documents.py dataset=argmicro_base metric=relation_argument_token_distances
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
</details>
|
| 117 |
+
|
| 118 |
+
| | len | max | mean | min | std |
|
| 119 |
+
| :---- | ---: | --: | -----: | --: | -----: |
|
| 120 |
+
| ALL | 1018 | 127 | 44.434 | 14 | 21.501 |
|
| 121 |
+
| exa | 18 | 63 | 33.556 | 16 | 13.056 |
|
| 122 |
+
| joint | 88 | 48 | 30.091 | 17 | 9.075 |
|
| 123 |
+
| reb | 220 | 127 | 49.327 | 16 | 24.653 |
|
| 124 |
+
| sup | 562 | 124 | 46.534 | 14 | 22.079 |
|
| 125 |
+
| und | 130 | 84 | 38.292 | 17 | 12.321 |
|
| 126 |
+
|
| 127 |
+
<details>
|
| 128 |
+
<summary>Histogram (split: train, 112 documents)</summary>
|
| 129 |
+
|
| 130 |
+

|
| 131 |
+
|
| 132 |
+
</details>
|
| 133 |
+
|
| 134 |
+
#### Span lengths (tokens)
|
| 135 |
+
|
| 136 |
+
The span length is measured from the first token of the first argumentative unit to the last token of the particular unit.
|
| 137 |
+
|
| 138 |
+
We collect the following statistics: number of documents in the split (*no. doc*), no. of spans (*len*), mean of number of tokens in a span (*mean*), standard deviation of the number of tokens (*std*), minimum tokens in a span (*min*), and maximum tokens in a span (*max*).
|
| 139 |
+
We also present histograms in the collapsible, showing the distribution of these token-numbers (x-axis; and unit-counts in y-axis), accordingly.
|
| 140 |
+
|
| 141 |
+
<details>
|
| 142 |
+
<summary>Command</summary>
|
| 143 |
+
|
| 144 |
+
```
|
| 145 |
+
python src/evaluate_documents.py dataset=argmicro_base metric=span_lengths_tokens
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
</details>
|
| 149 |
+
|
| 150 |
+
| statistics | train |
|
| 151 |
+
| :--------- | -----: |
|
| 152 |
+
| no. doc | 112 |
|
| 153 |
+
| len | 576 |
|
| 154 |
+
| mean | 16.365 |
|
| 155 |
+
| std | 6.545 |
|
| 156 |
+
| min | 4 |
|
| 157 |
+
| max | 41 |
|
| 158 |
+
|
| 159 |
+
<details>
|
| 160 |
+
<summary>Histogram (split: train, 112 documents)</summary>
|
| 161 |
+
|
| 162 |
+

|
| 163 |
+
|
| 164 |
+
</details>
|
| 165 |
+
|
| 166 |
+
#### Token length (tokens)
|
| 167 |
+
|
| 168 |
+
The token length is measured from the first token of the document to the last one.
|
| 169 |
+
|
| 170 |
+
We collect the following statistics: number of documents in the split (*no. doc*), mean of document token-length (*mean*), standard deviation of the length (*std*), minimum number of tokens in a document (*min*), and maximum number of tokens in a document (*max*).
|
| 171 |
+
We also present histograms in the collapsible, showing the distribution of these token lengths (x-axis; and unit-counts in y-axis), accordingly.
|
| 172 |
+
|
| 173 |
+
<details>
|
| 174 |
+
<summary>Command</summary>
|
| 175 |
+
|
| 176 |
+
```
|
| 177 |
+
python src/evaluate_documents.py dataset=argmicro_base metric=count_text_tokens
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
</details>
|
| 181 |
+
|
| 182 |
+
| statistics | train |
|
| 183 |
+
| :--------- | -----: |
|
| 184 |
+
| no. doc | 112 |
|
| 185 |
+
| mean | 84.161 |
|
| 186 |
+
| std | 22.596 |
|
| 187 |
+
| min | 36 |
|
| 188 |
+
| max | 153 |
|
| 189 |
+
|
| 190 |
+
<details>
|
| 191 |
+
<summary>Histogram (split: train, 112 documents)</summary>
|
| 192 |
+
|
| 193 |
+

|
| 194 |
+
|
| 195 |
+
</details>
|
argmicro.py
CHANGED
|
@@ -1,283 +1,283 @@
|
|
| 1 |
-
import copy
|
| 2 |
-
import dataclasses
|
| 3 |
-
import logging
|
| 4 |
-
from collections import defaultdict
|
| 5 |
-
from itertools import combinations
|
| 6 |
-
from typing import Any, Dict, List, Optional, Set, Tuple
|
| 7 |
-
|
| 8 |
-
import datasets
|
| 9 |
-
from pytorch_ie.annotations import BinaryRelation, Label, LabeledSpan, Span
|
| 10 |
-
from pytorch_ie.core import Annotation, AnnotationList, annotation_field
|
| 11 |
-
from pytorch_ie.documents import (
|
| 12 |
-
TextBasedDocument,
|
| 13 |
-
TextDocumentWithLabeledSpansAndBinaryRelations,
|
| 14 |
-
)
|
| 15 |
-
|
| 16 |
-
from pie_datasets import GeneratorBasedBuilder
|
| 17 |
-
|
| 18 |
-
log = logging.getLogger(__name__)
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
def dl2ld(dict_of_lists):
|
| 22 |
-
return [dict(zip(dict_of_lists, t)) for t in zip(*dict_of_lists.values())]
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
def ld2dl(list_of_dicts, keys: Optional[List[str]] = None):
|
| 26 |
-
return {k: [d[k] for d in list_of_dicts] for k in keys}
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
@dataclasses.dataclass(frozen=True)
|
| 30 |
-
class LabeledAnnotationCollection(Annotation):
|
| 31 |
-
annotations: Tuple[Annotation, ...]
|
| 32 |
-
label: str
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
@dataclasses.dataclass(frozen=True)
|
| 36 |
-
class MultiRelation(Annotation):
|
| 37 |
-
heads: Tuple[Annotation, ...] # sources == heads
|
| 38 |
-
tails: Tuple[Annotation, ...] # targets == tails
|
| 39 |
-
label: str
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
@dataclasses.dataclass
|
| 43 |
-
class ArgMicroDocument(TextBasedDocument):
|
| 44 |
-
topic_id: Optional[str] = None
|
| 45 |
-
stance: AnnotationList[Label] = annotation_field()
|
| 46 |
-
edus: AnnotationList[Span] = annotation_field(target="text")
|
| 47 |
-
adus: AnnotationList[LabeledAnnotationCollection] = annotation_field(target="edus")
|
| 48 |
-
relations: AnnotationList[MultiRelation] = annotation_field(target="adus")
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
def example_to_document(
|
| 52 |
-
example: Dict[str, Any],
|
| 53 |
-
adu_type_label: datasets.ClassLabel,
|
| 54 |
-
edge_type_label: datasets.ClassLabel,
|
| 55 |
-
stance_label: datasets.ClassLabel,
|
| 56 |
-
) -> ArgMicroDocument:
|
| 57 |
-
stance = stance_label.int2str(example["stance"])
|
| 58 |
-
document = ArgMicroDocument(
|
| 59 |
-
id=example["id"],
|
| 60 |
-
text=example["text"],
|
| 61 |
-
topic_id=example["topic_id"] if example["topic_id"] != "UNDEFINED" else None,
|
| 62 |
-
)
|
| 63 |
-
if stance != "UNDEFINED":
|
| 64 |
-
document.stance.append(Label(label=stance))
|
| 65 |
-
|
| 66 |
-
# build EDUs
|
| 67 |
-
edus_dict = {
|
| 68 |
-
edu["id"]: Span(start=edu["start"], end=edu["end"]) for edu in dl2ld(example["edus"])
|
| 69 |
-
}
|
| 70 |
-
# build ADUs
|
| 71 |
-
adu_id2edus = defaultdict(list)
|
| 72 |
-
edges_multi_source = defaultdict(dict)
|
| 73 |
-
for edge in dl2ld(example["edges"]):
|
| 74 |
-
edge_type = edge_type_label.int2str(edge["type"])
|
| 75 |
-
if edge_type == "seg":
|
| 76 |
-
adu_id2edus[edge["trg"]].append(edus_dict[edge["src"]])
|
| 77 |
-
elif edge_type == "add":
|
| 78 |
-
if "src" not in edges_multi_source[edge["trg"]]:
|
| 79 |
-
edges_multi_source[edge["trg"]]["src"] = []
|
| 80 |
-
edges_multi_source[edge["trg"]]["src"].append(edge["src"])
|
| 81 |
-
else:
|
| 82 |
-
edges_multi_source[edge["id"]]["type"] = edge_type
|
| 83 |
-
edges_multi_source[edge["id"]]["trg"] = edge["trg"]
|
| 84 |
-
if "src" not in edges_multi_source[edge["id"]]:
|
| 85 |
-
edges_multi_source[edge["id"]]["src"] = []
|
| 86 |
-
edges_multi_source[edge["id"]]["src"].append(edge["src"])
|
| 87 |
-
adus_dict = {}
|
| 88 |
-
for adu in dl2ld(example["adus"]):
|
| 89 |
-
adu_type = adu_type_label.int2str(adu["type"])
|
| 90 |
-
adu_edus = adu_id2edus[adu["id"]]
|
| 91 |
-
adus_dict[adu["id"]] = LabeledAnnotationCollection(
|
| 92 |
-
annotations=tuple(adu_edus), label=adu_type
|
| 93 |
-
)
|
| 94 |
-
# build relations
|
| 95 |
-
rels_dict = {}
|
| 96 |
-
for edge_id, edge in edges_multi_source.items():
|
| 97 |
-
edge_target = edge["trg"]
|
| 98 |
-
if edge_target in edges_multi_source:
|
| 99 |
-
targets = edges_multi_source[edge_target]["src"]
|
| 100 |
-
else:
|
| 101 |
-
targets = [edge_target]
|
| 102 |
-
if any(target in edges_multi_source for target in targets):
|
| 103 |
-
raise Exception("Multi-hop relations are not supported")
|
| 104 |
-
rel = MultiRelation(
|
| 105 |
-
heads=tuple(adus_dict[source] for source in edge["src"]),
|
| 106 |
-
tails=tuple(adus_dict[target] for target in targets),
|
| 107 |
-
label=edge["type"],
|
| 108 |
-
)
|
| 109 |
-
rels_dict[edge_id] = rel
|
| 110 |
-
|
| 111 |
-
document.edus.extend(edus_dict.values())
|
| 112 |
-
document.adus.extend(adus_dict.values())
|
| 113 |
-
document.relations.extend(rels_dict.values())
|
| 114 |
-
document.metadata["edu_ids"] = list(edus_dict.keys())
|
| 115 |
-
document.metadata["adu_ids"] = list(adus_dict.keys())
|
| 116 |
-
document.metadata["rel_ids"] = list(rels_dict.keys())
|
| 117 |
-
|
| 118 |
-
document.metadata["rel_seg_ids"] = {
|
| 119 |
-
edge["src"]: edge["id"]
|
| 120 |
-
for edge in dl2ld(example["edges"])
|
| 121 |
-
if edge_type_label.int2str(edge["type"]) == "seg"
|
| 122 |
-
}
|
| 123 |
-
document.metadata["rel_add_ids"] = {
|
| 124 |
-
edge["src"]: edge["id"]
|
| 125 |
-
for edge in dl2ld(example["edges"])
|
| 126 |
-
if edge_type_label.int2str(edge["type"]) == "add"
|
| 127 |
-
}
|
| 128 |
-
return document
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
def document_to_example(
|
| 132 |
-
document: ArgMicroDocument,
|
| 133 |
-
adu_type_label: datasets.ClassLabel,
|
| 134 |
-
edge_type_label: datasets.ClassLabel,
|
| 135 |
-
stance_label: datasets.ClassLabel,
|
| 136 |
-
) -> Dict[str, Any]:
|
| 137 |
-
stance = document.stance[0].label if len(document.stance) else "UNDEFINED"
|
| 138 |
-
result = {
|
| 139 |
-
"id": document.id,
|
| 140 |
-
"text": document.text,
|
| 141 |
-
"topic_id": document.topic_id or "UNDEFINED",
|
| 142 |
-
"stance": stance_label.str2int(stance),
|
| 143 |
-
}
|
| 144 |
-
|
| 145 |
-
# construct EDUs
|
| 146 |
-
edus = {
|
| 147 |
-
edu: {"id": edu_id, "start": edu.start, "end": edu.end}
|
| 148 |
-
for edu_id, edu in zip(document.metadata["edu_ids"], document.edus)
|
| 149 |
-
}
|
| 150 |
-
result["edus"] = ld2dl(
|
| 151 |
-
sorted(edus.values(), key=lambda x: x["id"]), keys=["id", "start", "end"]
|
| 152 |
-
)
|
| 153 |
-
|
| 154 |
-
# construct ADUs
|
| 155 |
-
adus = {
|
| 156 |
-
adu: {"id": adu_id, "type": adu_type_label.str2int(adu.label)}
|
| 157 |
-
for adu_id, adu in zip(document.metadata["adu_ids"], document.adus)
|
| 158 |
-
}
|
| 159 |
-
result["adus"] = ld2dl(sorted(adus.values(), key=lambda x: x["id"]), keys=["id", "type"])
|
| 160 |
-
|
| 161 |
-
# construct edges
|
| 162 |
-
rels_dict: Dict[str, MultiRelation] = {
|
| 163 |
-
rel_id: rel for rel_id, rel in zip(document.metadata["rel_ids"], document.relations)
|
| 164 |
-
}
|
| 165 |
-
heads2rel_id = {
|
| 166 |
-
rel.heads: red_id for red_id, rel in zip(document.metadata["rel_ids"], document.relations)
|
| 167 |
-
}
|
| 168 |
-
edges = []
|
| 169 |
-
for rel_id, rel in rels_dict.items():
|
| 170 |
-
# if it is an undercut attack, we need to change the target to the relation that connects the target
|
| 171 |
-
if rel.label == "und":
|
| 172 |
-
target_id = heads2rel_id[rel.tails]
|
| 173 |
-
else:
|
| 174 |
-
if len(rel.tails) > 1:
|
| 175 |
-
raise Exception("Multi-target relations are not supported")
|
| 176 |
-
target_id = adus[rel.tails[0]]["id"]
|
| 177 |
-
source_id = adus[rel.heads[0]]["id"]
|
| 178 |
-
edge = {
|
| 179 |
-
"id": rel_id,
|
| 180 |
-
"src": source_id,
|
| 181 |
-
"trg": target_id,
|
| 182 |
-
"type": edge_type_label.str2int(rel.label),
|
| 183 |
-
}
|
| 184 |
-
edges.append(edge)
|
| 185 |
-
# if it is an additional support, we need to change the source to the relation that connects the source
|
| 186 |
-
for head in rel.heads[1:]:
|
| 187 |
-
source_id = adus[head]["id"]
|
| 188 |
-
edge_id = document.metadata["rel_add_ids"][source_id]
|
| 189 |
-
edge = {
|
| 190 |
-
"id": edge_id,
|
| 191 |
-
"src": source_id,
|
| 192 |
-
"trg": rel_id,
|
| 193 |
-
"type": edge_type_label.str2int("add"),
|
| 194 |
-
}
|
| 195 |
-
edges.append(edge)
|
| 196 |
-
|
| 197 |
-
for adu_id, adu in zip(document.metadata["adu_ids"], document.adus):
|
| 198 |
-
for edu in adu.annotations:
|
| 199 |
-
source_id = edus[edu]["id"]
|
| 200 |
-
target_id = adus[adu]["id"]
|
| 201 |
-
edge_id = document.metadata["rel_seg_ids"][source_id]
|
| 202 |
-
edge = {
|
| 203 |
-
"id": edge_id,
|
| 204 |
-
"src": source_id,
|
| 205 |
-
"trg": target_id,
|
| 206 |
-
"type": edge_type_label.str2int("seg"),
|
| 207 |
-
}
|
| 208 |
-
edges.append(edge)
|
| 209 |
-
|
| 210 |
-
result["edges"] = ld2dl(
|
| 211 |
-
sorted(edges, key=lambda x: x["id"]), keys=["id", "src", "trg", "type"]
|
| 212 |
-
)
|
| 213 |
-
return result
|
| 214 |
-
|
| 215 |
-
|
| 216 |
-
def convert_to_text_document_with_labeled_spans_and_binary_relations(
|
| 217 |
-
doc: ArgMicroDocument,
|
| 218 |
-
) -> TextDocumentWithLabeledSpansAndBinaryRelations:
|
| 219 |
-
# convert adus to entities
|
| 220 |
-
entities = []
|
| 221 |
-
adu2entity: Dict[LabeledAnnotationCollection, Span] = {}
|
| 222 |
-
for adu in doc.adus:
|
| 223 |
-
edus: Set[Span] = set(adu.annotations)
|
| 224 |
-
start = min(edu.start for edu in edus)
|
| 225 |
-
end = max(edu.end for edu in edus)
|
| 226 |
-
# assert there are no edus overlapping with the adu, but not part of it
|
| 227 |
-
for edu in doc.edus:
|
| 228 |
-
if (start <= edu.start < end or start < edu.end <= end) and edu not in edus:
|
| 229 |
-
raise Exception(f"edu {edu} is overlapping with adu {adu}, but is not part of it")
|
| 230 |
-
entity = LabeledSpan(start=start, end=end, label=adu.label)
|
| 231 |
-
entities.append(entity)
|
| 232 |
-
adu2entity[adu] = entity
|
| 233 |
-
relations = []
|
| 234 |
-
for relation in doc.relations:
|
| 235 |
-
# add all possible combinations of heads and tails
|
| 236 |
-
for head in relation.heads:
|
| 237 |
-
for tail in relation.tails:
|
| 238 |
-
rel = BinaryRelation(
|
| 239 |
-
label=relation.label, head=adu2entity[head], tail=adu2entity[tail]
|
| 240 |
-
)
|
| 241 |
-
relations.append(rel)
|
| 242 |
-
# also add the relations between the heads themselves
|
| 243 |
-
for head1, head2 in combinations(relation.heads, 2):
|
| 244 |
-
rel = BinaryRelation(label="joint", head=adu2entity[head1], tail=adu2entity[head2])
|
| 245 |
-
relations.append(rel)
|
| 246 |
-
# also add the reverse relation
|
| 247 |
-
rel = BinaryRelation(label="joint", head=adu2entity[head2], tail=adu2entity[head1])
|
| 248 |
-
relations.append(rel)
|
| 249 |
-
|
| 250 |
-
metadata = copy.deepcopy(doc.metadata)
|
| 251 |
-
if len(doc.stance) > 0:
|
| 252 |
-
metadata["stance"] = doc.stance[0].label
|
| 253 |
-
metadata["topic"] = doc.topic_id
|
| 254 |
-
result = TextDocumentWithLabeledSpansAndBinaryRelations(
|
| 255 |
-
text=doc.text, id=doc.id, metadata=doc.metadata
|
| 256 |
-
)
|
| 257 |
-
result.labeled_spans.extend(entities)
|
| 258 |
-
result.binary_relations.extend(relations)
|
| 259 |
-
|
| 260 |
-
return result
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
class ArgMicro(GeneratorBasedBuilder):
|
| 264 |
-
DOCUMENT_TYPE = ArgMicroDocument
|
| 265 |
-
|
| 266 |
-
DOCUMENT_CONVERTERS = {
|
| 267 |
-
TextDocumentWithLabeledSpansAndBinaryRelations: convert_to_text_document_with_labeled_spans_and_binary_relations
|
| 268 |
-
}
|
| 269 |
-
|
| 270 |
-
BASE_DATASET_PATH = "DFKI-SLT/argmicro"
|
| 271 |
-
BASE_DATASET_REVISION = "282733d6d57243f2a202d81143c4e31bb250e663"
|
| 272 |
-
|
| 273 |
-
BUILDER_CONFIGS = [datasets.BuilderConfig(name="en"), datasets.BuilderConfig(name="de")]
|
| 274 |
-
|
| 275 |
-
def _generate_document_kwargs(self, dataset):
|
| 276 |
-
return {
|
| 277 |
-
"adu_type_label": dataset.features["adus"].feature["type"],
|
| 278 |
-
"edge_type_label": dataset.features["edges"].feature["type"],
|
| 279 |
-
"stance_label": dataset.features["stance"],
|
| 280 |
-
}
|
| 281 |
-
|
| 282 |
-
def _generate_document(self, example, **kwargs):
|
| 283 |
-
return example_to_document(example, **kwargs)
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import dataclasses
|
| 3 |
+
import logging
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
from itertools import combinations
|
| 6 |
+
from typing import Any, Dict, List, Optional, Set, Tuple
|
| 7 |
+
|
| 8 |
+
import datasets
|
| 9 |
+
from pytorch_ie.annotations import BinaryRelation, Label, LabeledSpan, Span
|
| 10 |
+
from pytorch_ie.core import Annotation, AnnotationList, annotation_field
|
| 11 |
+
from pytorch_ie.documents import (
|
| 12 |
+
TextBasedDocument,
|
| 13 |
+
TextDocumentWithLabeledSpansAndBinaryRelations,
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
from pie_datasets import GeneratorBasedBuilder
|
| 17 |
+
|
| 18 |
+
log = logging.getLogger(__name__)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def dl2ld(dict_of_lists):
|
| 22 |
+
return [dict(zip(dict_of_lists, t)) for t in zip(*dict_of_lists.values())]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def ld2dl(list_of_dicts, keys: Optional[List[str]] = None):
|
| 26 |
+
return {k: [d[k] for d in list_of_dicts] for k in keys}
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclasses.dataclass(frozen=True)
|
| 30 |
+
class LabeledAnnotationCollection(Annotation):
|
| 31 |
+
annotations: Tuple[Annotation, ...]
|
| 32 |
+
label: str
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
@dataclasses.dataclass(frozen=True)
|
| 36 |
+
class MultiRelation(Annotation):
|
| 37 |
+
heads: Tuple[Annotation, ...] # sources == heads
|
| 38 |
+
tails: Tuple[Annotation, ...] # targets == tails
|
| 39 |
+
label: str
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@dataclasses.dataclass
|
| 43 |
+
class ArgMicroDocument(TextBasedDocument):
|
| 44 |
+
topic_id: Optional[str] = None
|
| 45 |
+
stance: AnnotationList[Label] = annotation_field()
|
| 46 |
+
edus: AnnotationList[Span] = annotation_field(target="text")
|
| 47 |
+
adus: AnnotationList[LabeledAnnotationCollection] = annotation_field(target="edus")
|
| 48 |
+
relations: AnnotationList[MultiRelation] = annotation_field(target="adus")
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def example_to_document(
|
| 52 |
+
example: Dict[str, Any],
|
| 53 |
+
adu_type_label: datasets.ClassLabel,
|
| 54 |
+
edge_type_label: datasets.ClassLabel,
|
| 55 |
+
stance_label: datasets.ClassLabel,
|
| 56 |
+
) -> ArgMicroDocument:
|
| 57 |
+
stance = stance_label.int2str(example["stance"])
|
| 58 |
+
document = ArgMicroDocument(
|
| 59 |
+
id=example["id"],
|
| 60 |
+
text=example["text"],
|
| 61 |
+
topic_id=example["topic_id"] if example["topic_id"] != "UNDEFINED" else None,
|
| 62 |
+
)
|
| 63 |
+
if stance != "UNDEFINED":
|
| 64 |
+
document.stance.append(Label(label=stance))
|
| 65 |
+
|
| 66 |
+
# build EDUs
|
| 67 |
+
edus_dict = {
|
| 68 |
+
edu["id"]: Span(start=edu["start"], end=edu["end"]) for edu in dl2ld(example["edus"])
|
| 69 |
+
}
|
| 70 |
+
# build ADUs
|
| 71 |
+
adu_id2edus = defaultdict(list)
|
| 72 |
+
edges_multi_source = defaultdict(dict)
|
| 73 |
+
for edge in dl2ld(example["edges"]):
|
| 74 |
+
edge_type = edge_type_label.int2str(edge["type"])
|
| 75 |
+
if edge_type == "seg":
|
| 76 |
+
adu_id2edus[edge["trg"]].append(edus_dict[edge["src"]])
|
| 77 |
+
elif edge_type == "add":
|
| 78 |
+
if "src" not in edges_multi_source[edge["trg"]]:
|
| 79 |
+
edges_multi_source[edge["trg"]]["src"] = []
|
| 80 |
+
edges_multi_source[edge["trg"]]["src"].append(edge["src"])
|
| 81 |
+
else:
|
| 82 |
+
edges_multi_source[edge["id"]]["type"] = edge_type
|
| 83 |
+
edges_multi_source[edge["id"]]["trg"] = edge["trg"]
|
| 84 |
+
if "src" not in edges_multi_source[edge["id"]]:
|
| 85 |
+
edges_multi_source[edge["id"]]["src"] = []
|
| 86 |
+
edges_multi_source[edge["id"]]["src"].append(edge["src"])
|
| 87 |
+
adus_dict = {}
|
| 88 |
+
for adu in dl2ld(example["adus"]):
|
| 89 |
+
adu_type = adu_type_label.int2str(adu["type"])
|
| 90 |
+
adu_edus = adu_id2edus[adu["id"]]
|
| 91 |
+
adus_dict[adu["id"]] = LabeledAnnotationCollection(
|
| 92 |
+
annotations=tuple(adu_edus), label=adu_type
|
| 93 |
+
)
|
| 94 |
+
# build relations
|
| 95 |
+
rels_dict = {}
|
| 96 |
+
for edge_id, edge in edges_multi_source.items():
|
| 97 |
+
edge_target = edge["trg"]
|
| 98 |
+
if edge_target in edges_multi_source:
|
| 99 |
+
targets = edges_multi_source[edge_target]["src"]
|
| 100 |
+
else:
|
| 101 |
+
targets = [edge_target]
|
| 102 |
+
if any(target in edges_multi_source for target in targets):
|
| 103 |
+
raise Exception("Multi-hop relations are not supported")
|
| 104 |
+
rel = MultiRelation(
|
| 105 |
+
heads=tuple(adus_dict[source] for source in edge["src"]),
|
| 106 |
+
tails=tuple(adus_dict[target] for target in targets),
|
| 107 |
+
label=edge["type"],
|
| 108 |
+
)
|
| 109 |
+
rels_dict[edge_id] = rel
|
| 110 |
+
|
| 111 |
+
document.edus.extend(edus_dict.values())
|
| 112 |
+
document.adus.extend(adus_dict.values())
|
| 113 |
+
document.relations.extend(rels_dict.values())
|
| 114 |
+
document.metadata["edu_ids"] = list(edus_dict.keys())
|
| 115 |
+
document.metadata["adu_ids"] = list(adus_dict.keys())
|
| 116 |
+
document.metadata["rel_ids"] = list(rels_dict.keys())
|
| 117 |
+
|
| 118 |
+
document.metadata["rel_seg_ids"] = {
|
| 119 |
+
edge["src"]: edge["id"]
|
| 120 |
+
for edge in dl2ld(example["edges"])
|
| 121 |
+
if edge_type_label.int2str(edge["type"]) == "seg"
|
| 122 |
+
}
|
| 123 |
+
document.metadata["rel_add_ids"] = {
|
| 124 |
+
edge["src"]: edge["id"]
|
| 125 |
+
for edge in dl2ld(example["edges"])
|
| 126 |
+
if edge_type_label.int2str(edge["type"]) == "add"
|
| 127 |
+
}
|
| 128 |
+
return document
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def document_to_example(
|
| 132 |
+
document: ArgMicroDocument,
|
| 133 |
+
adu_type_label: datasets.ClassLabel,
|
| 134 |
+
edge_type_label: datasets.ClassLabel,
|
| 135 |
+
stance_label: datasets.ClassLabel,
|
| 136 |
+
) -> Dict[str, Any]:
|
| 137 |
+
stance = document.stance[0].label if len(document.stance) else "UNDEFINED"
|
| 138 |
+
result = {
|
| 139 |
+
"id": document.id,
|
| 140 |
+
"text": document.text,
|
| 141 |
+
"topic_id": document.topic_id or "UNDEFINED",
|
| 142 |
+
"stance": stance_label.str2int(stance),
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
# construct EDUs
|
| 146 |
+
edus = {
|
| 147 |
+
edu: {"id": edu_id, "start": edu.start, "end": edu.end}
|
| 148 |
+
for edu_id, edu in zip(document.metadata["edu_ids"], document.edus)
|
| 149 |
+
}
|
| 150 |
+
result["edus"] = ld2dl(
|
| 151 |
+
sorted(edus.values(), key=lambda x: x["id"]), keys=["id", "start", "end"]
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
# construct ADUs
|
| 155 |
+
adus = {
|
| 156 |
+
adu: {"id": adu_id, "type": adu_type_label.str2int(adu.label)}
|
| 157 |
+
for adu_id, adu in zip(document.metadata["adu_ids"], document.adus)
|
| 158 |
+
}
|
| 159 |
+
result["adus"] = ld2dl(sorted(adus.values(), key=lambda x: x["id"]), keys=["id", "type"])
|
| 160 |
+
|
| 161 |
+
# construct edges
|
| 162 |
+
rels_dict: Dict[str, MultiRelation] = {
|
| 163 |
+
rel_id: rel for rel_id, rel in zip(document.metadata["rel_ids"], document.relations)
|
| 164 |
+
}
|
| 165 |
+
heads2rel_id = {
|
| 166 |
+
rel.heads: red_id for red_id, rel in zip(document.metadata["rel_ids"], document.relations)
|
| 167 |
+
}
|
| 168 |
+
edges = []
|
| 169 |
+
for rel_id, rel in rels_dict.items():
|
| 170 |
+
# if it is an undercut attack, we need to change the target to the relation that connects the target
|
| 171 |
+
if rel.label == "und":
|
| 172 |
+
target_id = heads2rel_id[rel.tails]
|
| 173 |
+
else:
|
| 174 |
+
if len(rel.tails) > 1:
|
| 175 |
+
raise Exception("Multi-target relations are not supported")
|
| 176 |
+
target_id = adus[rel.tails[0]]["id"]
|
| 177 |
+
source_id = adus[rel.heads[0]]["id"]
|
| 178 |
+
edge = {
|
| 179 |
+
"id": rel_id,
|
| 180 |
+
"src": source_id,
|
| 181 |
+
"trg": target_id,
|
| 182 |
+
"type": edge_type_label.str2int(rel.label),
|
| 183 |
+
}
|
| 184 |
+
edges.append(edge)
|
| 185 |
+
# if it is an additional support, we need to change the source to the relation that connects the source
|
| 186 |
+
for head in rel.heads[1:]:
|
| 187 |
+
source_id = adus[head]["id"]
|
| 188 |
+
edge_id = document.metadata["rel_add_ids"][source_id]
|
| 189 |
+
edge = {
|
| 190 |
+
"id": edge_id,
|
| 191 |
+
"src": source_id,
|
| 192 |
+
"trg": rel_id,
|
| 193 |
+
"type": edge_type_label.str2int("add"),
|
| 194 |
+
}
|
| 195 |
+
edges.append(edge)
|
| 196 |
+
|
| 197 |
+
for adu_id, adu in zip(document.metadata["adu_ids"], document.adus):
|
| 198 |
+
for edu in adu.annotations:
|
| 199 |
+
source_id = edus[edu]["id"]
|
| 200 |
+
target_id = adus[adu]["id"]
|
| 201 |
+
edge_id = document.metadata["rel_seg_ids"][source_id]
|
| 202 |
+
edge = {
|
| 203 |
+
"id": edge_id,
|
| 204 |
+
"src": source_id,
|
| 205 |
+
"trg": target_id,
|
| 206 |
+
"type": edge_type_label.str2int("seg"),
|
| 207 |
+
}
|
| 208 |
+
edges.append(edge)
|
| 209 |
+
|
| 210 |
+
result["edges"] = ld2dl(
|
| 211 |
+
sorted(edges, key=lambda x: x["id"]), keys=["id", "src", "trg", "type"]
|
| 212 |
+
)
|
| 213 |
+
return result
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
def convert_to_text_document_with_labeled_spans_and_binary_relations(
|
| 217 |
+
doc: ArgMicroDocument,
|
| 218 |
+
) -> TextDocumentWithLabeledSpansAndBinaryRelations:
|
| 219 |
+
# convert adus to entities
|
| 220 |
+
entities = []
|
| 221 |
+
adu2entity: Dict[LabeledAnnotationCollection, Span] = {}
|
| 222 |
+
for adu in doc.adus:
|
| 223 |
+
edus: Set[Span] = set(adu.annotations)
|
| 224 |
+
start = min(edu.start for edu in edus)
|
| 225 |
+
end = max(edu.end for edu in edus)
|
| 226 |
+
# assert there are no edus overlapping with the adu, but not part of it
|
| 227 |
+
for edu in doc.edus:
|
| 228 |
+
if (start <= edu.start < end or start < edu.end <= end) and edu not in edus:
|
| 229 |
+
raise Exception(f"edu {edu} is overlapping with adu {adu}, but is not part of it")
|
| 230 |
+
entity = LabeledSpan(start=start, end=end, label=adu.label)
|
| 231 |
+
entities.append(entity)
|
| 232 |
+
adu2entity[adu] = entity
|
| 233 |
+
relations = []
|
| 234 |
+
for relation in doc.relations:
|
| 235 |
+
# add all possible combinations of heads and tails
|
| 236 |
+
for head in relation.heads:
|
| 237 |
+
for tail in relation.tails:
|
| 238 |
+
rel = BinaryRelation(
|
| 239 |
+
label=relation.label, head=adu2entity[head], tail=adu2entity[tail]
|
| 240 |
+
)
|
| 241 |
+
relations.append(rel)
|
| 242 |
+
# also add the relations between the heads themselves
|
| 243 |
+
for head1, head2 in combinations(relation.heads, 2):
|
| 244 |
+
rel = BinaryRelation(label="joint", head=adu2entity[head1], tail=adu2entity[head2])
|
| 245 |
+
relations.append(rel)
|
| 246 |
+
# also add the reverse relation
|
| 247 |
+
rel = BinaryRelation(label="joint", head=adu2entity[head2], tail=adu2entity[head1])
|
| 248 |
+
relations.append(rel)
|
| 249 |
+
|
| 250 |
+
metadata = copy.deepcopy(doc.metadata)
|
| 251 |
+
if len(doc.stance) > 0:
|
| 252 |
+
metadata["stance"] = doc.stance[0].label
|
| 253 |
+
metadata["topic"] = doc.topic_id
|
| 254 |
+
result = TextDocumentWithLabeledSpansAndBinaryRelations(
|
| 255 |
+
text=doc.text, id=doc.id, metadata=doc.metadata
|
| 256 |
+
)
|
| 257 |
+
result.labeled_spans.extend(entities)
|
| 258 |
+
result.binary_relations.extend(relations)
|
| 259 |
+
|
| 260 |
+
return result
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class ArgMicro(GeneratorBasedBuilder):
|
| 264 |
+
DOCUMENT_TYPE = ArgMicroDocument
|
| 265 |
+
|
| 266 |
+
DOCUMENT_CONVERTERS = {
|
| 267 |
+
TextDocumentWithLabeledSpansAndBinaryRelations: convert_to_text_document_with_labeled_spans_and_binary_relations
|
| 268 |
+
}
|
| 269 |
+
|
| 270 |
+
BASE_DATASET_PATH = "DFKI-SLT/argmicro"
|
| 271 |
+
BASE_DATASET_REVISION = "282733d6d57243f2a202d81143c4e31bb250e663"
|
| 272 |
+
|
| 273 |
+
BUILDER_CONFIGS = [datasets.BuilderConfig(name="en"), datasets.BuilderConfig(name="de")]
|
| 274 |
+
|
| 275 |
+
def _generate_document_kwargs(self, dataset):
|
| 276 |
+
return {
|
| 277 |
+
"adu_type_label": dataset.features["adus"].feature["type"],
|
| 278 |
+
"edge_type_label": dataset.features["edges"].feature["type"],
|
| 279 |
+
"stance_label": dataset.features["stance"],
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
def _generate_document(self, example, **kwargs):
|
| 283 |
+
return example_to_document(example, **kwargs)
|
img/rtd-label_argmicro.png
ADDED

|
Git LFS Details
|
img/slt_argmicro.png
ADDED
|
Git LFS Details
|
img/tl_argmicro.png
ADDED

|
Git LFS Details
|
requirements.txt
CHANGED
|
@@ -1 +1 @@
|
|
| 1 |
-
pie-datasets>=0.3.3,<0.
|
|
|
|
| 1 |
+
pie-datasets>=0.3.3,<0.11.0
|