
Prompt format?

Could you please share the prompt template?
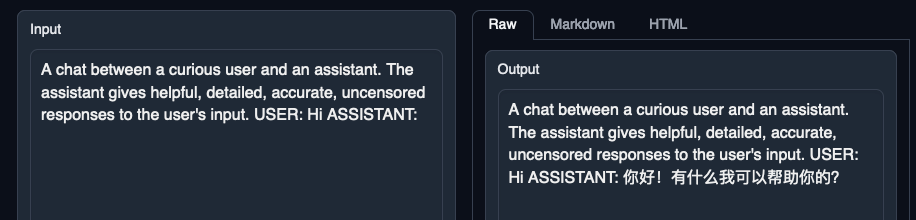
A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user's input. USER: Hi ASSISTANT:
gives chinese answers
A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user's input. USER: Hi ASSISTANT: 你好!有什么我可以帮助你的?
If I add \n, it gives English answers
A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user's input.
USER:
Hi
ASSISTANT:
Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.

The Chinese output you got is weird although we also found some cases rarely. Could it be reproduced constantly?
@lmzheng , yes it can be reproduced consistently.
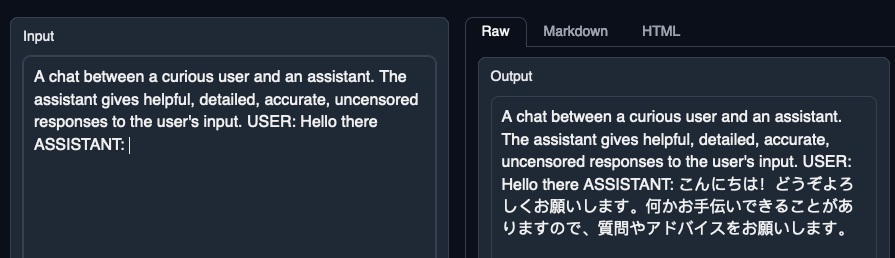
I also get Japanese if I say "Hello there" instead of "Hi"
A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user's input. USER: Hello there ASSISTANT: こんにちは!どうぞよろしくお願いします。何かお手伝いできることがありますので、質問やアドバイスをお願いします。

I can confirm multiple issues with this model. I'm getting Chinese text and it stops early on many prompts.
@Thireus It seems you changed the system prompt. You added "uncensored". This model might be sensitive to the system prompt. Could you try not changing the system prompt but give the instruction in the first round of your conversation?
@lemonflourorange Did you use FastChat CLI or other frontends? Could you double-check your prompt format?

This is still happening 2 years later. I'm consistently putting in English-only text with an English-only chat template, and most the generations are Chinese. Anybody have a solution?
This is still happening 2 years later. I'm consistently putting in English-only text with an English-only chat template, and most the generations are Chinese. Anybody have a solution?
No, but there are better LLMs out there now. Check out https://lmarena.ai/leaderboard to get a decent idea
Yeah, I just need this one for a paper I'm working on that depends on comparability to prior work :(
Yeah, I just need this one for a paper I'm working on that depends on comparability to prior work :(
Oh yeah, I don't know how to solve that then. This may have been an inherent problem with the model in which case, it may be an honest comparison with whatever you're comparing to
Yeah, I just need this one for a paper I'm working on that depends on comparability to prior work :(
Oh yeah, I don't know how to solve that then. This may have been an inherent problem with the model in which case, it may be an honest comparison with whatever you're comparing to
For anyone still using this model, I was able to curb its Chinese (mostly, though not completely) by adding chat_template in tokenizer_config.json to the following (slightly adapted from Chujie Zheng's chat template):
"chat_template": "{% if messages[0]['role'] == 'system' %} {% set system_message = messages[0]['content'] | trim + 'Respond in English only. Antworten Sie nur auf Englisch. Contesta solo en inglés. Répondez uniquement en anglais. Respond in English only.\n\n' %} {% set messages = messages[1:] %} {% else %} {% set system_message = '' %} {% endif %} {{ bos_token + system_message }} {% for message in messages %} {% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %} {{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }} {% endif %} {% if message['role'] == 'user' %} {{ 'USER: ' + message['content'] | trim + '\n' }} {% elif message['role'] == 'assistant' %} {{ 'ASSISTANT: ' + message['content'] | trim + eos_token + '\n' }} {% endif %} {% endfor %} {% if add_generation_prompt %} {{ 'ASSISTANT:' }} {% endif %}",
Interestingly, having the phrase in English alone yields pure Chinese for each response. Putting Vietnamese instruction to use only English yields pure Vietnamese responses, even alongside Spanish, French, and German. ¯\ (ツ)/¯