
LSTM & GRU FOR RNN MODELS
WORD REPRESENTATION
- Word2vec & GloVe
- Word2vec includes two types of models, which are CBOW & Skip-Gram
- every sliding window, we calculate the gradients of both context and target words, so we could update our theta_t and e_c vector. After sliding all the windows, we could get embedding matrix E and prediction matrix W.
- After having trained our Word2Vec or GloVe model (both contains E and W), we only use the embedding matrix E for transfer learning.
Seq2Seq
- Neural Machine Translation/Image Captioning:
- CNN + one-to-many structure RNN for Image Captioning
- many-to-many Encoder-decoder structure & Encoder-Decoder Structure with Attention Mechanism for NMT
Attention Is All You Need
Implementing Transformers From Scratch Using Pytorch
- 1. Introduction
- 2. Import libraries
- 3. Basic components
- 4. Encoder
- 5. Decoder
- 6. Testing our code
- 7. Some useful resources
1. Introduction
In this tutorial, we will explain the try to implement transformers in "Attention is all you need paper" from scratch using Pytorch. Basically transformer have an encoder-decoder architecture. It is common for language translation models.
Note: Here we are not going for an indepth explaination of transformers. For that please refer [blog](http://jalammar.github.io/illustrated-transformer/.) by Jay alammar. He has given indepth explanation about the inner working of the transformers. We will just focus on the coding part.
The above image shows a language translation model from French to English. Actually we can use stack of encoder(one in top of each) and stack of decoders as below:
Before going further Let us see a full fledged image of our attention model.
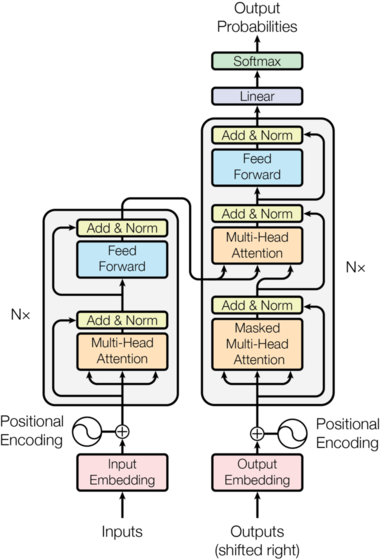
We know that transformer has an encoder decoder architecture for language translation. Before getting in to encoder pr decoder, let us discuss some common components.
Basic components
Create Word Embeddings
First of all we need to convert each word in the input sequence to an embedding vector. Embedding vectors will create a more semantic representation of each word.
Suppoese each embedding vector is of 512 dimension and suppose our vocab size is 100, then our embedding matrix will be of size 100x512. These marix will be learned on training and during inference each word will be mapped to corresponding 512 d vector. Suppose we have batch size of 32 and sequence length of 10(10 words). The the output will be 32x10x512.
Positional Encoding
Next step is to generate positional encoding. Inorder for the model to make sense of the sentence, it needs to know two things about the each word.
- what does the word mean?
- what is the position of the word in the sentence.
In "attention is all you need paper" author used the following functions to create positional encoding. On odd time steps a cosine function is used and in even time steps a sine function is used.
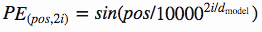
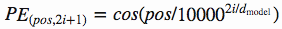
pos -> refers to order in the sentence
i -> refers to position along embedding vector dimension
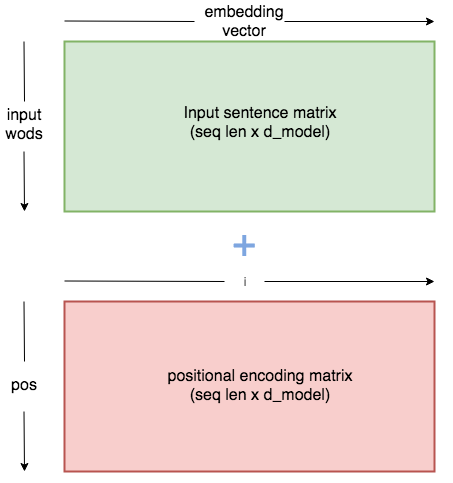
Positinal embedding will generate a matrix of similar to embedding matrix. It will create a matrix of dimension sequence length x embedding dimension. For each token(word) in sequence, we will find the embedding vector which is of dimension 1 x 512 and it is added with the correspondng positional vector which is of dimension 1 x 512 to get 1 x 512 dim out for each word/token.
for eg: if we have batch size of 32 and seq length of 10 and let embedding dimension be 512. Then we will have embedding vector of dimension 32 x 10 x 512. Similarly we will have positional encoding vector of dimension 32 x 10 x 512. Then we add both.
Self Attention
Let me give a glimpse on Self Attention and Multihead attention
What is self attention?
Suppose we have a sentence "Dog is crossing the street because it saw the kitchen".What does it refers to here? It's easy to understand for the humans that it is Dog. But not for the machines.
As model proceeses each word, self attention allows it to look at other positions in the input sequence for clues. It will creates a vector based on dependency of each word with the other.
Let us go through a step by step illustration of self attention.
- Step 1: The first step in calculating self-attention is to create three vectors from each of the encoder’s input vectors (in this case, the embedding of each word). So for each word, we create a Query vector, a Key vector, and a Value vector. Each of the vector will be of dimension 1x64.
Since we have a multihead attention we will have 8 self attention heads.I will explain the code with 8 attention head in mind.
How key,queries and values can be created?
We will have a key matrix,query matrix and a value matrix to generate key, query and value. These matrixes are learned during training.
code hint:
Suppose we have batch_size=32,sequence_length=10, embedding dimension=512. So after embedding and positional encoding our output will be of dimension 32x10x512.
We will resize it to 32x10x8x64.(About 8, it is the number of heads in multihead attention.Dont worry you will get to know about it once you go through the code.).
- Step 2: Second step is to calculate the score. ie, we will multiply query marix with key matrix. [Q x K.t]
code hint:
Suppose our key,query and value dimension be 32x10x8x64. Before proceeding further, we will transpose each of them for multiplication convinience (32x8x10x64). Now multiply query matrix with transpose key matrix. ie (32x8x10x64) x (32x8x64x10) -> (32x8x10x10).
- Step 3: Now divide the output matrix with square root of dimension of key matrix and then apply Softmax over it.
code hint: we will divide 32x8x10x10 vector by 8 ie, by square root of 64 (dimension of key matrix)
- Step 4: Then this gets multiply it with value matrix.
code hint:
After step 3 our output will be of dimension 32x8x10x10. Now muliply it with value matrix (32x8x10x64) to get output of dimension (32x8x10x64).Here 8 is the number of attention heads and 10 is the sequence length.Thus for each word we have 64 dim vector.
- Step 5: Once we have this we will pass this through a linear layer. This forms the output of multihead attention.
code hint:
(32x8x10x64) vector gets transposed to (32x10x8x64) and then reshaped as (32x10x512).Then it is passed through a linear layer to get output of (32x10x512).
Now you got an idea on how multihead attention works. You will be more clear once you go through the implementation part of it.
Ok, now a sudden question can strike your mind. What is this mask used for? Don't worry we will go through it once we are talking about the decoder.
4. Encoder
In the encoder section -
Step 1: First input(padded tokens corresponding to the sentence) get passes through embedding layer and positional encoding layer.
code hint
suppose we have input of 32x10 (batch size=32 and sequence length=10). Once it passes through embedding layer it becomes 32x10x512. Then it gets added with correspondng positional encoding vector and produces output of 32x10x512. This gets passed to the multihead attention
Step 2: As discussed above it will passed through the multihead attention layer and creates useful representational matrix as output.
code hint
input to multihead attention will be a 32x10x512 from which key,query and value vectors are generated as above and finally produces a 32x10x512 output.
Step 3: Next we have a normalization and residual connection. The output from multihead attention is added with its input and then normalized.
code hint
output of multihead attention which is 32x10x512 gets added with 32x10x512 input(which is output created by embedding vector) and then the layer is normalized.
Step 4: Next we have a feed forward layer and a then normalization layer with residual connection from input(input of feed forward layer) where we passes the output after normalization though it and finally gets the output of encoder.
code hint
The normalized output will be of dimension 32x10x512. This gets passed through 2 linear layers: 32x10x512 -> 32x10x2048 -> 32x10x512. Finally we have a residual connection which gets added with the output and the layer is normalized. Thus a 32x10x512 dimensional vector is created as output for the encoder.
5. Decoder
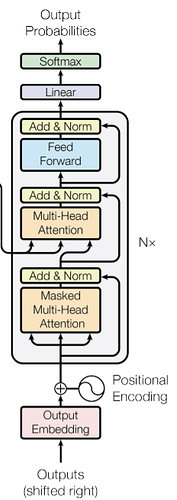
Now we have gone through most parts of the encoder.Let us get in to the components of the decoder. We will use the output of encoder to generate key and value vectors for the decoder.There are two kinds of multi head attention in the decoder.One is the decoder attention and other is the encoder decoder attention. Don't worry we will go step by step.