
{kind=link}
GLM-5.2
Collection
2 items • Updated • 44
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.2 blog and GLM-5 Technical report.
📍 Use GLM-5.2 API services on Z.ai API Platform.
🔜 Try GLM-5.2 here.
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
| Benchmark | GLM-5.2 | GLM-5.1 | Qwen3.7-Max | MiniMax M3 | DeepSeek-V4-Pro | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|---|---|
| Reasoning | ||||||||
| HLE | 40.5 | 31 | 41.4 | 37 | 37.7 | 49.8* | 41.4* | 45 |
| HLE (w/ Tools) | 54.7 | 52.3 | 53.5 | - | 48.2 | 57.9* | 52.2* | 51.4* |
| CritPt | 20.9 | 4.6 | 13.4 | 3.7 | 12.9 | 20.9 | 27.1 | 17.7 |
| AIME 2026 | 99.2 | 95.3 | 97 | - | 94.6 | 95.7 | 98.3 | 98.2 |
| HMMT Nov. 2025 | 94.4 | 94 | 95 | 84.4 | 94.4 | 96.5 | 96.5 | 94.8 |
| HMMT Feb. 2026 | 92.5 | 82.6 | 97.1 | 84.4 | 95.2 | 96.7 | 96.7 | 87.3 |
| IMOAnswerBench | 91.0 | 83.8 | 90 | - | 89.8 | 83.5 | - | 81 |
| GPQA-Diamond | 91.2 | 86.2 | 90 | 93 | 90.1 | 93.6 | 93.6 | 94.3 |
| Coding | ||||||||
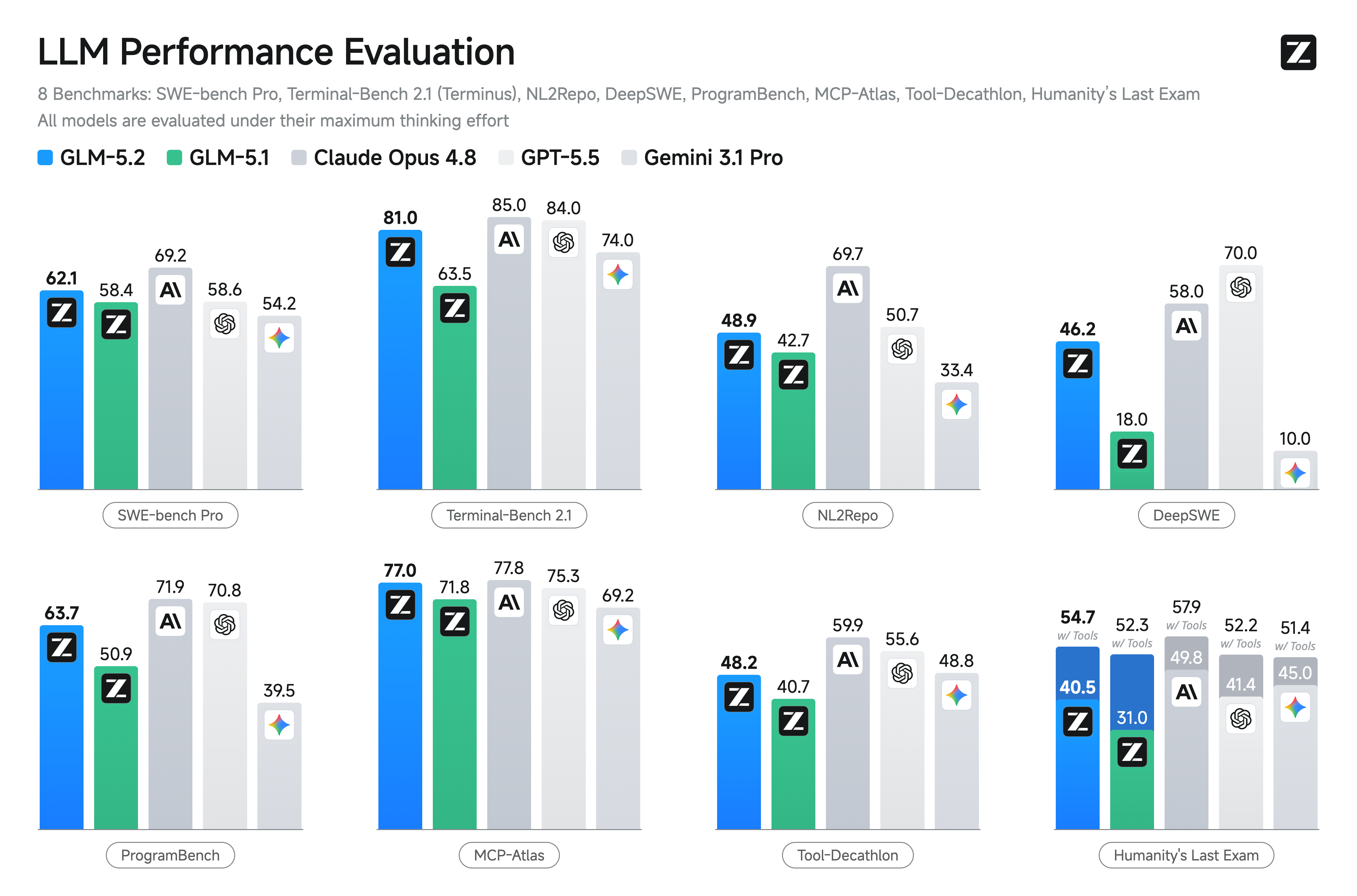
| SWE-bench Pro | 62.1 | 58.4 | 60.6 | 59 | 55.4 | 69.2 | 58.6 | 54.2 |
| NL2Repo | 48.9 | 42.7 | 47.2 | 42.1 | 35.5 | 69.7 | 50.7 | 33.4 |
| DeepSWE | 46.2 | 18 | 18 | 20 | 8 | 58 | 70 | 10 |
| ProgramBench | 63.7 | 50.9 | - | - | 47.8 | 71.9 | 70.8 | 39.5 |
| Terminal Bench 2.1 (Terminus-2) | 81.0 | 63.5 | 75 | 65 | 64 | 85 | 84 | 74 |
| Terminal Bench 2.1 (Best Reported Harness) | 82.7 | 69 | - | - | - | 78.9 | 83.4 | 70.7 |
| FrontierSWE (Dominance) | 74.4 | 30.5 | - | - | 29.0 | 75.1 | 72.6 | 39.6 |
| PostTrainBench | 34.3 | 20.1 | - | - | - | 37.2 | 28.4 | 21.6 |
| SWE-Marathon | 13.0 | 1.0 | - | - | - | 26.0 | 12.0 | 4.0 |
| Agentic | ||||||||
| MCP-Atlas (Public Set) | 76.8 | 71.8 | 76.4 | 74.2 | 73.6 | 77.8 | 75.3 | 69.2 |
| Tool-Decathlon | 48.2 | 40.7 | - | - | 52.8 | 59.9 | 55.6 | 48.8 |
GLM-5.2 supports deployment with the following frameworks. Feel free to try them out:
Ascend NPU platform, inference frameworks such as vLLM-Ascend, xLLM and SGLang are supported — see here.temperature=1.0, top_p=0.95 for evaluation. We evaluate with a maximum generation length of 163,840 tokens. By default, we report the text-only subset; results marked with * are from the full set. For AIME, HMMT and IMOAnswerBench, we evaluate each question using the following system prompt: Your response should be in the following format:\nExplanation: {your explanation for your final answer}\nExact Answer: {your succinct, final answer}\nConfidence: {your confidence score between 0% and 100% for your answer}. We use GPT-5.5 (medium) as the judge model. For HLE-with-tools, we use a maximum context length of 300,000 tokens, with no context management strategy.temperature=1, top_p=1, max_new_tokens=32k, with a 400K context window.temperature=1.0, top_p=1.0, and max_new_tokens=48k under 400k context. To prevent hacking, we use rule-based and a LLM-based judgement to prevent malicious behaviors (e.g., unauthorized pip or curl operations).temperature=1.0, top_p=1.0, timeout=2h, 400K context). Each task is solved in an isolated container with 2 CPUs, 8 GB RAM, and no internet access.temperature=1.0, top_p=1.0, max_tokens=64000, max_turns=2000, sample_timeout=6h, reasoning_effort=max, with a 400K context window. Each instance runs in a (4 CPUs, 8 GB RAM) sandbox with internet access disabled.parser=json, timeout=4h, temperature=1.0, top_p=1.0, max_new_tokens=48k, max_episodes=500, with a 256K context window. Resource limits are capped at 4 CPUs and 8 GB RAM.temperature=1.0, top_p=0.95, max_new_tokens=131072. We override max_new_tokens to 128k via a transparent proxy, bypassing the 64k CLI cap to restore the configurability of CLAUDE_CODE_MAX_OUTPUT_TOKENS. We remove wall-clock time limits, while preserving per-task CPU and memory constraints. Scores are averaged over 5 runs. If you find GLM-5.2 useful in your research, please cite our technical report:
@misc{glm5team2026glm5vibecodingagentic,
title={GLM-5: from Vibe Coding to Agentic Engineering},
author={GLM-5-Team and : and Aohan Zeng and Xin Lv and Zhenyu Hou and Zhengxiao Du and Qinkai Zheng and Bin Chen and Da Yin and Chendi Ge and Chenghua Huang and Chengxing Xie and Chenzheng Zhu and Congfeng Yin and Cunxiang Wang and Gengzheng Pan and Hao Zeng and Haoke Zhang and Haoran Wang and Huilong Chen and Jiajie Zhang and Jian Jiao and Jiaqi Guo and Jingsen Wang and Jingzhao Du and Jinzhu Wu and Kedong Wang and Lei Li and Lin Fan and Lucen Zhong and Mingdao Liu and Mingming Zhao and Pengfan Du and Qian Dong and Rui Lu and Shuang-Li and Shulin Cao and Song Liu and Ting Jiang and Xiaodong Chen and Xiaohan Zhang and Xuancheng Huang and Xuezhen Dong and Yabo Xu and Yao Wei and Yifan An and Yilin Niu and Yitong Zhu and Yuanhao Wen and Yukuo Cen and Yushi Bai and Zhongpei Qiao and Zihan Wang and Zikang Wang and Zilin Zhu and Ziqiang Liu and Zixuan Li and Bojie Wang and Bosi Wen and Can Huang and Changpeng Cai and Chao Yu and Chen Li and Chengwei Hu and Chenhui Zhang and Dan Zhang and Daoyan Lin and Dayong Yang and Di Wang and Ding Ai and Erle Zhu and Fangzhou Yi and Feiyu Chen and Guohong Wen and Hailong Sun and Haisha Zhao and Haiyi Hu and Hanchen Zhang and Hanrui Liu and Hanyu Zhang and Hao Peng and Hao Tai and Haobo Zhang and He Liu and Hongwei Wang and Hongxi Yan and Hongyu Ge and Huan Liu and Huanpeng Chu and Jia'ni Zhao and Jiachen Wang and Jiajing Zhao and Jiamin Ren and Jiapeng Wang and Jiaxin Zhang and Jiayi Gui and Jiayue Zhao and Jijie Li and Jing An and Jing Li and Jingwei Yuan and Jinhua Du and Jinxin Liu and Junkai Zhi and Junwen Duan and Kaiyue Zhou and Kangjian Wei and Ke Wang and Keyun Luo and Laiqiang Zhang and Leigang Sha and Liang Xu and Lindong Wu and Lintao Ding and Lu Chen and Minghao Li and Nianyi Lin and Pan Ta and Qiang Zou and Rongjun Song and Ruiqi Yang and Shangqing Tu and Shangtong Yang and Shaoxiang Wu and Shengyan Zhang and Shijie Li and Shuang Li and Shuyi Fan and Wei Qin and Wei Tian and Weining Zhang and Wenbo Yu and Wenjie Liang and Xiang Kuang and Xiangmeng Cheng and Xiangyang Li and Xiaoquan Yan and Xiaowei Hu and Xiaoying Ling and Xing Fan and Xingye Xia and Xinyuan Zhang and Xinze Zhang and Xirui Pan and Xu Zou and Xunkai Zhang and Yadi Liu and Yandong Wu and Yanfu Li and Yidong Wang and Yifan Zhu and Yijun Tan and Yilin Zhou and Yiming Pan and Ying Zhang and Yinpei Su and Yipeng Geng and Yong Yan and Yonglin Tan and Yuean Bi and Yuhan Shen and Yuhao Yang and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yurong Wu and Yutao Zhang and Yuxi Duan and Yuxuan Zhang and Zezhen Liu and Zhengtao Jiang and Zhenhe Yan and Zheyu Zhang and Zhixiang Wei and Zhuo Chen and Zhuoer Feng and Zijun Yao and Ziwei Chai and Ziyuan Wang and Zuzhou Zhang and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
year={2026},
eprint={2602.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.15763},
}